1. INTRODUCTION
Relevance has a rich history as a core concept in information research but it and the way it is measured might be based on a fundamental weakness. Does relevance define the ways that individuals assess information or does it tell us more about how researchers classify information? It is probably no accident that relevance research has been obsessed with how to measure relevance, with some suggesting simple dichotomous response scales or three- four- five- seven- and ninepoint scales, and with others suggesting the need for complex multidimensional distance measures. How then might relevance be defined at its basic level if the ways we expect respondents to report it are so uncertain and even contradictory?
This paper addresses how the very definitions of relevance used by scholars might or might not be consistent with the definitions employed by users. If there are differences in such fundamental assumptions then this could call into question the generalizations derived from relevance research. The sheer volume of publications on relevance points to its significance as a platform for defining new and related concepts and variables in ensuing research. If the concept of relevance can be defined or perceived by users to underlie their relevance judgment, then how that concept is constructed and represented by them should be used to inform the research community how it, in turn, might construct its definition of relevance. Important here are the constituent elements of the concept of relevance from users’ views. Further, are information users’ views different from other groups of information users -- including information professionals who also use relevance criteria? In short, does a relevance judgment tell us about a user decision or does it inform us about how individuals react to the ways in which researchers create measurement scales to classify how others might make information decisions? This problem has deep roots, and it emerged long ago in research by Cuadra and Katter (1967, 1968) and in their related studies (System Development Corporation, 1967; Katter 1968). Surprisingly, those results were often ignored by later researchers who resorted to what appears as reasonable measurement scales, but may reflect how the researcher assesses relevance and not how users evaluate information. It would be important to anchor relevance in the words of the user and re-define it in their terms.
Relevance research has focused on such constructs as topicality, aboutness, and pertinence, which have been derived from the more general concept of relevance. Nonetheless, it is not known if end-users would naturally employ such a structure to assess how retrieved information can be categorized and evaluated as applicable to the original information needs. The importance of establishing an isometric relationship between the assumptions and definitions of the researchers and the users might be compared to early studies of personality. When it was found that personality attributes of individuals did not link directly to the construction of behavior, it was concluded that the personality traits more properly identified how psychologists classified individuals. If the basis for relevance defined by the researcher and end-user do not correspond with each other, then it might be possible to conclude that relevance studies more likely uncover how researchers classify underlying motivations such as information needs to explain why individuals seek and evaluate information the way that they do. This may also mean that the users have their own conceptual models when constructing the necessary or sufficient pre-conditions to trigger an observable information behavior. If this is so, then it might be concluded that relevance research has been able to provide explanatory models of users’ behavior but not ones with any meaningful predictive power.
Saracevic’s holistic, interdisciplinary review of the concept of relevance (1975) identified research covering various approaches to understanding relevance in information science and other several disciplines. Saracevic’s more recent articles (2007a; 2007b) have covered, categorized, annotated, and updated relevance studies since his earlier work. In addition to Saracevic’s summary of the existing framework of relevance (2007a, p. 1931), Cronin (2008) and Hjørland (2002; 2010) have proposed a social or socio-cognitive framework in information science which has ramifications for the definition and empirical bases of relevance studies. Hjørland (2010) identified critical issues in creating a platform for user-based relevance and he offers a subjective yet realistic view where subject experts are separated from lay users with links across system characteristics and user attributes. This reinforces the possibility that prior notions and classifications of relevance may describe those who study this phenomenon more than describing the behaviors associated with users. To address these issues, this paper attempts to apply a social representations framework to reify ‘user-based relevance’ through a social representations framework. In other words, this current study attempts to examine how users construct their collective perceptions of ‘relevance’ through the lens of a structural analysis of social representations theory while also comparing information users’ construction of their perception of the relevance concept to that of information professionals.
As Saracevic pointed out (2007a; 2007b), the existing body of studies on user-based relevance criteria are subjective, and samples in those studies were not tested over a broader, general public. This motivated a need to address research questions throughout this current paper such as: (1) what are the emergent concepts (facets or elements) of relevance from information users and from information professionals?; (2) how are those concepts organized to constitute the concept of relevance in terms of core and periphery elements?; and (3) how are users’ views on relevance different from those held by information professionals? Relevance is an intuitive human notion (Saracevic, 2007) with a long established explanatory base; nevertheless, this study attempts to identify, operationalize, and measure the different facets of relevance to make them more predictable and to explore where overlap among concepts might exist. This is also an attempt to expand those participating in this research from the usual college students and faculty to a more general public sample.
At one time, relevance was often linked to those using online or printed bibliographic or text based systems. Today, relevance can be viewed from a much broader horizon with global audiences seeking all manner of information from online sources. Consequently, relevance and relevance judgments are intertwined in everyday life as information permeates and pervades most societies. The focus of relevance shifts across topicality to user-identified criteria, and then to socially constructed meaning. The motivation of this research is to examine how general information users—both information users and information professionals who regularly make relevance judgments in their everyday life—view the concept of relevance and make judgments on relevant information from the perspective of social representations theory (SRT). A social representation is a concept or the set of concepts that shape our understanding on a social object/concept without considering specific contexts or situations. Social representations are the collective representations of a social concept or object, which are produced, re-elaborated, and re-interpreted from time to time by the members of a community/society. In the field of information science, the understanding/interpretation of the concept of relevance has been approached from different angles such as situationbased, or individual cognition-based, or system vs. user-based. In this current study, we use the social representation theory proposed by Sergei Moscovic and a structural analysis by Jean Calude Arbric for specific analytic methods appropriate for data interpretation.
The significance of this study is to revisit the concept of relevance (or relevance criteria) from the perspectives held by information professionals compared to views held by the general public who may represent different social strata, and to investigate how these different views on relevance are socially constructed by applying a theoretical lens of social representations theory. It is expected that different collective perspectives will be proffered by different social groups.
2. LITERATURE REVIEW
Related literature reviewed in this study pertains to user-based relevance criteria in information science and a structural analysis of social representations theory.
2.1 User-based relevance and relevance criteria in information science
Saracevic’s research (2007a, 2007b) provides comprehensive views on relevance, including different perspectives on the concept of relevance in information science and other disciplines. During recent decades, there were differing and contrasting views and arguments on the concept of relevance and the criteria used to measure it. The most obvious and widely accepted contrast focused on system-oriented vs. user-oriented views (Saracevic, 1975; destination view evolving into a system vs. human perspective, Saracevic, 2007a). Our review does not re-visit the Saracevic analyses except to focus on the ‘user-oriented’ or ‘user-centered’ concept of relevance and its concomitant relevance criteria.
User-based relevance could be traced back to Vickery (1959), who differentiated ‘user relevance’ from ‘relevance to a subject.’ The user relevance refers to the users’ decision on how far to pursue a search for particular information. Cuadra and Katter’s (1967) research identified “implicit use orientations” which indicated the relationship between documents and users’ interest or intention to use, in contrast to work which assumed that there was a link between system output and the users’ information requirement statement. The latter is more about the topicality aspect of relevance which is used in retrieval system evaluation.
Wilson (1978) saw the concept of relevance as “retrieval-worthy” of documents (p.17) in the context of information retrieval. This places relevance as a link connecting what is requested to who requested it, and how it was requested in terms of document attributes. It reaffirms his approach of defining relevance in his earlier work (1973). He categorized relevance into four components: psychological, logical, evidential, and situational. His situational relevance refers to “relevance to a particular individual’s situation” (p. 460) that is “confined to the aspects of our situation that concern us” (p. 461). Along with this concern, other parameters, such as preference, interests, time (past and future), and completeness, could all be factored in to constitute a specific situation. His situational relevance was drawn from the definition of logical relevance by Cooper (1971) who created a logical connection between the linguistically expressed requests of information needs and a minimal set of statements that logically entail an answer to those requests. Later, Swanson (1986) attempted to elaborate on a distinction between subjective and objective relevance. Subjective relevance is relevance that can be defined only by the originator of the requestors (“the sole legitimate authority,” p. 391) and describing subjective relevance as intractable, while objective relevance can be defined independently of the creator. The objectified information need is logically related to some documents that are relevant regardless of being so identified by others. Relevance then becomes an essential component of the link between the objectified written request and a document which can “belong to the world of objective knowledge.”
Schamber and her colleagues (1990) introduced a dynamic and situational conceptualization of relevance focusing on the users’ situation. Their conceptualization reflects Dervin’s constructivist view of information users’ Sense-Making process/environment (1983) for information needs and uses. Dervin’s situationality of her Sense-Making theory posits that humans make sense of their world in terms of discontinuity and time/space boundaries. According to this, relevance becomes “a dynamic concept that depends on users’ individual judgments of the quality of the relationship between information and information need at a certain point in time” (p. 771), and this approaches a user-based criteria for relevance judgments. Schamber (1991) identified users’ relevance criteria with 20 categories which emerged from interviewing 30 users. Barry (1994) extended this by conceptualizing relevance as “any connection between the users’ information need situation and the information provided by documents.” The findings support her assumption of relevance beyond topicality by presenting categories pertaining to users’ background and experience, users’ belief and preferences, and the users’ situation. The results of these two studies were compared (Barry & Schamber, 1998) to explore similarities and differences in the criteria identified in both investigations. Similarities arose from evidence for the existence of a finite range of criteria that are applied across types of users, information problem situations, and information sources, while differences (or divergences) came from different research tasks given and situational differences rather than “inherent differences in the evaluation behaviors of respondents” (p. 234). They reaffirm that users’ perceptions on relevance and relevance evaluation extends beyond the content of information.
Park (1993) investigated factors contributing to user-based relevance using ten participants in a naturalistic inquiry on their citation selection process. Three major categories were identified: internal (experience) context, external (search) context, and problem (content) context. This was combined with how individuals approach and interpret citations. Her empirical model found that “relevance is interpretive” of users and cannot be represented as a static and precise relationship between documents and a user’s question” (p. 345). Wang (1997) compared previous relevance criteria studies done by Barry (1994), Schamber (1991), and Park (1992), and presented a document selection model. This model (Wang, 1994; Wang & White, 1995) describes the relationship between relevance criteria identified and the decision rules to be applied.
Bruce (1994) developed a model of cognitive schema for people to estimate relevance, which presented a dynamic association between users’ relevance and a contextual dependence as modified during retrieval interaction. His proposed schema was drawn from a notion of a “problem state” (Saracevic, et al., 1988; Belkin & Vickery, 1985) with attention to document attributes and information attributes such as those addressed by Cuadra and Katter (1967). This schema allows for observing the proportional relationship of the magnitude of changes in information retrieval interaction and resulting changes in problem states and document and information attributes. Wang and White (1995) and Tang and Solomon (2001) investigated the shift of relevance usage at the different stages of the document evaluation process.
User perspectives on relevance criteria for relevant, partially relevant, and not-relevant judgments linked to users’ information needs were investigated in a study conducted by Maglaughlin and Sonnenwald (2002). A comparison of content criteria in passage selection and document selection resulted in identifying six core components: abstract, author, content, full text, journal/publisher, and personal information (p. 337). Hirsh (1999) explored ten fifth-grade children’s relevance criteria for searching different electronic formats of materials. The study identified criteria for textual, graphical, and both textual and graphical materials (pp. 1279-1280). Major categories include topicality, novelty, authority, interesting, and peer interest which encompassed children’s relevance criteria applied during the search process. It also needs to be noted that other concepts have emerged in relevance research: pertinence (Foskett, 1972; Kemp, 1974; Howard, 1994), satisfaction (Bookstein, 1979; Gluck, 1995, 1996), and utility (Saracevic, 1975; Janes, 1994).
2.2. Social representations theory
At this point it is obvious that the very selection of a competing theory to explain users’ information decisions and behaviors may, in fact, “load the dice” to achieve a pre-determined outcome and a pre-packaged conclusion. One escape from this conundrum would be to recognize that certain situations channel individuals’ behaviors the way one-way streets corral traffic to move in a particular pattern. It might be contended that information systems create a restricted range of choices over what might be displayed given a particular query. It can usually be safely assumed that certain isomorphic patterns will link query characteristics to document representations. The order of the queries may be manipulated but some logic is present to select the document in the first place. The objects in the document representations exist within an order governed by a social convention defined by group members. This social representation of phenomena or social objects can be understood in different frames but their basis and ongoing control is rooted in group discourse and concrete activities.
Such a world view of social representation was espoused by Serge Moscovici in the field of social psychology. Moscovici’s motivation was to understand “when and why large numbers of people hold the same or similar views or opinions of the world and to investigate differences among individuals in their views” (Fraser, 1994). Social representation is, in essence, about “objective reality” which claims that there is no a priori objective reality but that all reality is represented (Abric, 2001). A current example might clarify such a process if we were to consider what occurs when journal articles are refereed. The referee does not assess the truthfulness of the data or the report; instead, the referee adjudicates the language used in the article. If the manuscript uses the most current language used by the social group of a particular sub-discipline and if the methodology is that of the type accepted by that social group, then the prospective article meets the liminal standards for approval. What is approved might be viewed by some as a use of current jargon buttressed by a particular methodology but, in reality, it represents a social representation that provides logic and order to an otherwise arbitrary system. The same might be said of relevance research; theretofore, it has confirmed researcher expectations but at the possible expense of ignoring end-users’ definitional criteria.
The underlying structure of social representation theory involves certain critical components. Symbolic coping (Wagner et al., 1999) is part of the process of forming social representation and it includes such concepts as anchoring, objectification, and conventionalization (Moscovici, 1976; Moscovici, 1984; Markova & Wilkie, 1987; Moscovici & Marcova, 1998). Anchoring is the process used by a social group when it encounters an unfamiliar object; the object is named according to its attributes, in order for group members to communicate about it among themselves. Through the repetition of discourse by naming and talking about it, the unfamiliar object becomes a part of the group’s social life. Conventionalization is the process when people become familiar with unconventional things by using similar conventional schemata, and objectification is a type of symbolic coping where a social group develops its own way of interpreting an unfamiliar object or phenomenon.
This study attempts to modify and apply this process to information users and their understanding of the concept of relevance. The widespread use of the Internet and the proliferation of IT technology can be viewed as situations which are part of everyday life for most individuals. The adoption of the term “relevance” can be viewed for these users through the lens of symbolic coping where social groups create a definitional framework using a process to reinforce a particular interpretation of relevance.
2.3. A structural analysis approach of social representations theory
French psychologist Moscovici first proposed and defined social representation as “the elaborating of a social object by the community for the purpose of behaving and communicating” (Moscovici, 1963, p. 250). Since then, social representations theory and its associated research activities and various perspectives have flourished. Moscovici’s intellectual motivation was to explore how scientific knowledge was transformed into common ordinary knowledge. He explored how common thinking and common knowledge are grounded in everyday life, and he provided a context to respond to criticisms that the diffusion of scientific information could be regarded as a devaluation of scientific knowledge (Moscovici & Marková, 1998). Moscovici’s social representation can be interpreted as the way in which individuals and groups view the world to place a meaning to their understanding of reality, which includes their own value system. They can then adapt that knowledge, and define their interpretation of it, because they now own that information within their own social group. This can also be viewed as a reflection of restructured reality which becomes a socially elaborated and shared knowledge base where the concurrence of commonly constructed reality can be communicated to a social whole (Jodelet, 1989).
Moscovici’s concept of social representation is allied with Lévy-Bruhl/Vygotsky’s which takes a dialectic and dynamic perspective of the dichotomy between society and individual minds. This is a sharp distinction from Durkheim’s collective representation. The social representation approach emphasizes the interdependence of culture and individual minds, their codevelopment, and the interdependence between thinking and speaking (Moscovici & Marková, 1998). Social representations maintain that there are no distinctions between subject and object and that these are not regarded as separate: “An object is located in a context of activity since it is what it is because it is in part regarded by the person or the group as an extension of their behavior” (Moscovici, 1973, p. xi). This abandonment of duality leads to an objective reality which is represented and reconstructed by individuals or groups and replaced in their cognitive systems. This represents a major departure from other approaches of methodological individualism in social psychology and epistemology (Farr, 1996; Wagner, 1999; Abric, 2001).
A structural analysis approach by Abric (1976, 1987, 1993, 2001) and others (Flament, 1984, 1994; Hammond, 1993; Moliner, 1995) to social representations is an effort to develop a theoretical extension to social representations theory. Using a structural approach has allowed researchers to combine elements of social representation to include opinions, beliefs, and attitudes toward any given social object where those elements are organized around one or more central cores which give the representation its meaning (Abric, 1976). According to Abric (1993), the internal organization of social representations consists of the central core and peripheral elements which have their own specific but complementary roles toward each other. The central cores constitute a system of a social representation which represents what is “marked by the collective memory of the group and the system of norms to which it refers” (p. 75). The central system is rigid, stable, and not very sensitive to the immediate context. It signifies the importance of the representation. In contrast, the peripheral system is functional, more flexible, and supports “the heterogeneity of the group” (p.76). The periphery also allows adaptation to reality and permits “content differentiation” (p. 76). Most of the time, the central cores remain steady while some of the peripheral elements undergo transformation. It functions as a bumper, which puts an interface between the core system and the reality it faces (Flament, 1994). With these dual systems, a social representation tends to be adaptive to evolution to allow transformation of socio-cognitive modification to changes/situations.
To identify and scrutinize the internal organization of social representations, Abric (2001) further examined the characteristics between core and periphery elements. As evidence of its central core, he proposed three values: symbolic, associative, and expressive. The symbolic value provides essential information about the representation, and “cannot be questioned without affecting the signification of the presentation” (p. 45). Associative value can be presented as a “higher degree of connection” (p.46) among elements as a direct link to the referent representation. Expressive value, defined by Abric, is one which is “very much present in the discourses and verbalizations concerning the object of the representation” (p. 46). Empirical verification of this approach is supported by numerous studies on various social objects and beliefs across different subject areas of social science (Verge, 1992; Guimelli, 1993; Abric, 1994; Flament, 1994; Moliner, 1995; Wagner et al., 1996; Tafani, 2001).
In particular, several studies have used the three values defined by Arbric and have operationalized this using measurable variables for social objects and beliefs. Wachelke and Lin (2008) studied young people’s social representation on aging and the centrality of a ‘wisdom’ element in its representation through normal and non-normative data collection. The symbolic value related to the social representation on aging was measured by questioning items which explained the relationship between the symbolic value of a negative connotation of elements such as ‘isolation’ and a positive element such as ‘wisdom.’ Pawlowski and her colleagues (2007) explored the topic of job stress and burnout in IT professionals through semi-structured interviews. In their study, the authors identified the relationship between stressors, burnout, employee, and outcomes through a social representations map and core-periphery analysis. Jung’s (2009) recent methodology paper further exploited a structural analysis approach to examine the social representations of electronic health records (EHRs) by applying similarity analysis (Falment, 1986; Pawlowski, 2007) and a coreperiphery model (Borgatti & Everett, 1999) for associative values. The results of this study demonstrated the core and periphery structure of 22 topics of social representations of EHRs as well as addressing key methodological issues.
3. RESEARCH METHODS
3.1. Study participants
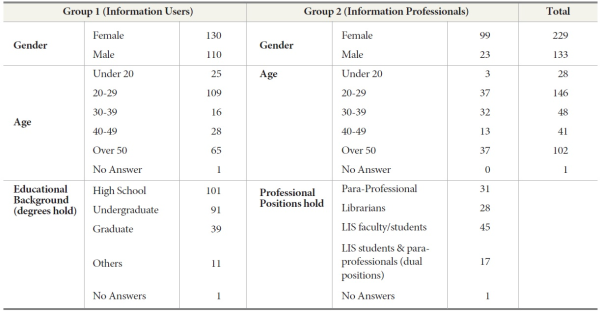
This study explored user-defined (or user-based) relevance with two groups of individuals: information users (Group 1) and information professionals (Group 2). A total of 367 individuals voluntarily participated in this study. These were convenience samples of individuals ranging from 19 to over 60 years of age. Group 1 (user group; G1 hereafter) consists of 244 information users (110 male and 134 female) who were recruited from three public libraries in a metropolitan area and one university library in a southeastern U.S. state. Group 2 (information professional group; G2 hereafter) consists of 123 information professionals such as librarians and para-professionals (23 male and 99 female) from the same three public libraries previously mentioned. Saracevic (2007b) pointed out the necessity of studying diverse populations beyond students for a better understanding of relevance to extend generalizations. Additionally, such an approach can affirm the importance of using individuals confronting real situations where relevance decisions reflect issues of importance to users. Data from public and academic libraries might also create a more accurate setting for the social construction view of users.
Questionnaires were distributed at the lobbies of those libraries and participants were asked to fill these out at the sites. Participation in the study was voluntary.

Summary of study participants (G1 vs. G2)
3.2. Free word association as data collection method
Questionnaires employing a free word association technique were used to identify users’ construction of their relevance judgment criteria. The free word association method is used in the fields of education (Hovardas & Korfiatis, 2006), and psychology and sociology (Doise, et al., 1993; Wagner, et al., 1996; Schmitt, 1998) to draw out an individual’s attitudes, beliefs, and conceptual structure. A stimulus word or phrase is given and participants are usually asked to freely associate what ideas come to their mind. This can provide a relatively unrestricted access to mental representations of the stimulus terms. In this study, each participant was asked to list three words or phrases without any specific order that came to their mind when they read descriptions of relevance and relevance criteria (See Appendix).
3.3. Data analysis
Collected data were analyzed in three stages. In the first stage, content analysis was used in order to delineate words/phrases from word associations of the two groups’ responses to the stimulus phrase. This allows for data reduction and refinement, which results in the identification of major categories of relevance. The second stage of analysis was the structural analysis of word associations, which involved the measurement of weighted frequency, sum of similarity, and coreness. These three parameters revealed the facets of relevance and how those facets are constructed. The last stage of analysis was the comparison of the two groups’ social representations through cross tabulation in terms of associative and expressive values of the structural analysis.
3.3.1 Content analysis
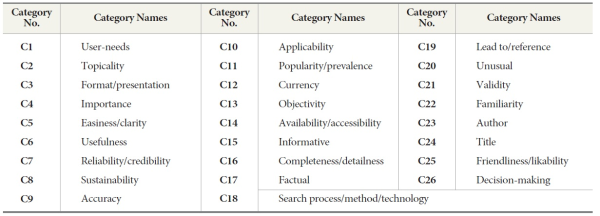
Word associations from 234 information users (G1) and 123 information professionals (G2) were analyzed using content analysis in order to identify major categories of relevance. Objective and systematic analysis from free word association through content analysis makes inferences about users’ view on relevance (Stemler, 2001; Weber, 1985). Coding was done by two coders to assess similarities and differences between the two groups. Inter-coder reliability was assessed to evaluate coder consistency. Both coders are researchers in information science and each developed coding schemes independently. The resulting major categories emerged from the words/phrases which were provided by study participants using free word association. The initial thirty-six categories were identified as major concepts, which were further refined and collapsed resulting in the final twenty-six categories. Coders did not use an a priori list of categories, and those that were developed emerged from the coding procedure. For example, credibility, reliability, and quality were all later integrated into the category of ‘reliability/credibility.’ Decision-making, analysis, and selection which represent users’ judgment processes are included in the category ‘decision-making.’ Both coders analyzed category names of the coding scheme to reach agreement between their respective assignment of terms based on definition of concepts and the corresponding category names that each serves or represents (Weber, 1985). This final process might be viewed as a measure of face validity.
Cohen’s Kappa was calculated to ensure inter-coder reliability. For G1, 637 items (directly from study participants) were coded and yielded 713 codes due to items with multiple codes. For example, items such as “source is reliable and updated” and “info that is correct and from a respected source” were assigned two code numbers. A total of 655 out of 713 codes were in agreement between the two coders (Consistency = .92, Cohen’s Kappa = .90). For G2, 364 items were coded and this yielded 409 codes. A total of 341 out of 409 codes were in agreement between the two coders (Consistency = .83, Cohen’s Kappa = .82). These levels of reliability are considered ‘substantial.’ Inappropriate items were treated as ‘uncodable’ and these were not used in later analyses.
3.3.2 Structural analysis
In this stage of data analysis, similarity analysis (Flament, 1984; Jung, et al., 2009), core/periphery model analysis (Borgatti & Everett, 1999; Jung et al., 2009), and weighted frequencies were computed in order to identify the core and periphery structure of social representations by the two groups on relevance. As evidence for the central core (Arbric, 1993; 2001) of social representations, its characteristics are presented as associative value and expressive values.
The associative value in this current study includes: (1) a similarity sum arrived at using similarity analysis; and (2) a coreness measurement calculated using core/periphery analysis. Similarity analysis involved the construction of an inter-attribute similarity (IAS) matrix, which reflects the proximity of each pair of items by each participant. Jaccard’s similarity coefficient was used as a proximity measure to indicate the degree of occurrence of a pair of items. Then, each item’s proximity to the rest of the items was added to produce a sum of similarity, which indicates the level of an item’s association or closeness to other items. The coreness of each item is another indicator of associative value and core/periphery analysis was performed using UCINET 6 (Borgatti et al., 2002). UCINET 6 is software that analyzes social network data by providing a variety of analytic methods to include centrality measures, core-periphery measures, role analyses, and graph theory.
For the expressive value, instead of counting a simple frequency of each item, weighed-frequency (salience) of occurrence of each item was counted to measure how categories are salient. The majority of study participants responded to three items in their questionnaires. In order to ensure the equality of measurement, the frequencies of each item were calculated on the basis of the number of users’ responses. For example, if one participant’s response yielded three codes then each code had a frequency of one-third; if a participant yielded four codes then each code had a frequency of one-fourth. All twenty-six categories ended up with weighted frequencies using this method.
These three indicators—sum of similarity, weightedfrequency, and coreness—served as a structural analysis parameter to depict how the concept of relevance is constructed by the two groups. In this current study, there was no attempt to measure symbolic value, which, by definition, “cannot be questioned without affecting the significance of the representation” (Arbric, 2001). It is assumed that one of the best ways to verify this value is to conduct a longitudinal study to see if the value is consistent over a specified time.
3.3.3 Visualization of the two social representations with the maximum trees
Two groups, G1 and G2, were compared by constructing the maximum trees of the similarity of the representation in order to illustrate any differences among them. The notion of maximum tree for social representation was proposed by Flement (1986) in order to present the relationship among words/concepts based on the similarity coefficient. As Flement (1986) and Abric & Vacherot (1976) suggest, maximum trees were constructed using the pair-wise similarity
Emerged categories of relevance from word association (no specific order)
coefficient from the Inter-Attribute Similarity (IAS) Matrix for the two groups respectively. The notion of maximum tree originated from graph theory, which indicates “all elements are linked together and there is only one way to go from the one element to another” (Doise et al, 1993, p.33) with minimum spanning links among all nodes (Pawlowski et al., 2007).
4. RESULTS
4.1. Identified categories of relevance from emergent coding of word association
An emergent coding process was employed to achieve data reduction of free word association from the two groups of participants’ responses. This also allowed for the identification of various facets of the concept of relevance. Table 2 summarizes those categories, which constitute concepts of relevance previously identified in the earlier study (Ju & Gluck, 2011), which demonstrated the coding process in detail. Both groups yielded the same set of categories, though the organization of these categories is not quite similar.
These categories reflect a more comprehensive list of facets of relevance than those identified in previous studies. Rather than giving participants set definitions and sub-topics involving relevance judgments, participants were asked instead to respond with three words/phrases which were then parsed into a collective and shared social representation.
4.2. Internal Structure of Relevance: Core vs. Periphery
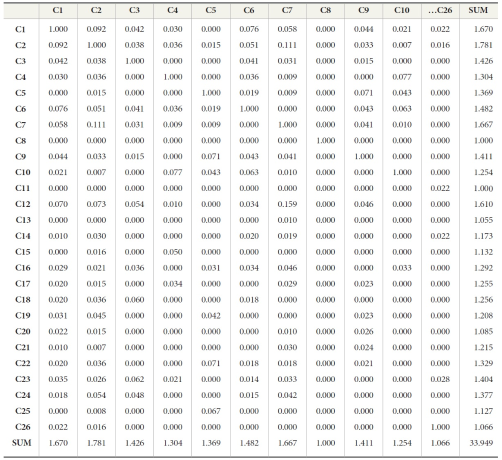
The internal structure of relevance was depicted in terms of three parameters: sum of similarity, coreness, and weighted frequency in order to identify the central core concepts and the periphery concepts. Table 3 shows the sum of similarity of each concept (category) of relevance that was identified from this stage of content analysis. Each cell indicates a Jaccard’s similarity coefficient of corresponding pairs of concepts. Pairs of concepts were made on a basis of every possible
A sample part (C1 to C10) of Inter-Attribute Similarity (IAS) Matrix from Group 2
Note: The rest of this matrix is available upon request.
response from each respondent, and Jaccard’s similarity coefficients were calculated accordingly. The coefficient shows how proximate those two items are with the sum of each item’s proximity, which indicates the levels of proximity to the rest of the concepts as indicated by SUM in the table. A higher number means higher proximity.
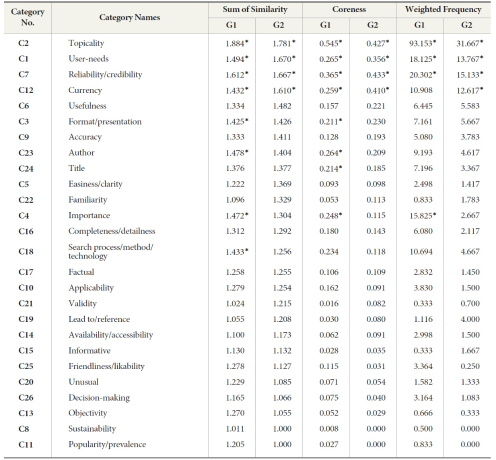
In order to set the threshold point between the core and the periphery for the twenty-six concepts based on sum of similarity shown in Table 3, the analysis included Ward’s Hierarchical Clustering Analysis (HCA) via SPSS. Table 4 illustrates the core and periphery status of the two participant groups. Concepts of Topicality (C2), User-needs (C1), Reliability/credibility (C7), Format/presentation (C3), Author (C23), Importance (C4), and Search process/method/technology (C18) are identified as core concepts for the information user group (G1). Similarly, Topicality (C2), User-needs (C1), Reliability/credibility (C7), and Currency (C12) were identified as core concepts for information professionals (G2).
Borgatti and Everett’s core/periphery model (1999)
Core and periphery in terms of Associative values (Sum of similarity and Coreness) and Expressive values (Weighted frequency)
Note: * indicates a core.
analysis was applied to calculate coreness of twenty-six concepts. Coreness indicates the strength of the relationship between two concepts as expressed by a function of the closeness of each to the center. The structured matrix for coreness is expressed as δij = cicj where c is a vector value that represents a degree of coreness of each node. In this algorithm, a high value for a pair of concepts means that both concepts have a value of high coreness. A middle value means one is high in core and the other is periphery, while a low value means both are peripheral. This could be interpreted to mean that “the strength of tie between two actors is a function of the closeness of each to the center, or perhaps the gregariousness of each actor” (Borgatti & Everett, 1999, p. 387). Topicality (C2), User-needs (C1), Importance (C4), Reliability/credibility (C7), Format/presentation (C3), Author (C23), and Title (C24) are identified as the core for G1. Only four concepts are identified as the core for G2, which include Topicality (C2), User-needs (C1), Importance (C4), and Reliability/credibility (C7).
For weighted frequency, each of the twenty-six categories yielded frequencies according to their occurrences from each participant’s response as a unit for ensuring measurement equality. Ward’s Hierarchical Clustering Analysis (HCA) was employed to determine if the weighted frequency of G1 and G2 fell into two clusters respectively. As seen in Table 4, information users (G1) view Topicality (C2), User-needs (C1), Importance (C4), and Reliability/credibility (C7) as

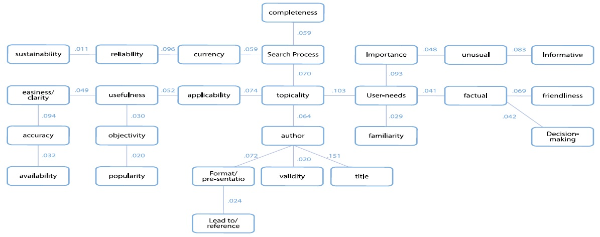
Visualization of the Social Representation of Information Users (G1)

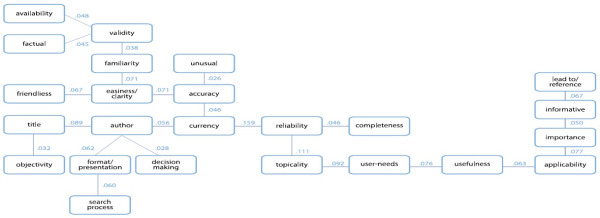
Visualization of the Social Representation of Information Professionals (G2)
relevance criteria that they would apply. In contrast, information professionals (G2) rely more on Currency (C12) instead of Importance (C4) as their relevance criteria, which are more specific criteria. This indicates that there are key definable differences at the naming level in the relevance framework of information users when compared to information professionals.
4.3. Comparison of social representations from the two social collectives
Figures 1 and 2 illustrate the maximum trees for G1 and G2 respectively. Maximum trees were developed from the similarity coefficient of all categories (C1- C26) from the Inter-Attribute Similarity (IAS) Matrix (Table 3) by using the nearest neighbor algorithm. In this case, weighted frequency, sum of similarity, and coreness are also used for comparison and for breaking ties between two categories to construct trees (Jung, 2010).
In both figures, linkage values are based on the similarity values. Figure 1 illustrates the relationship of all 26 categories while only 24 categories are shown in Figure 2. The omitted categories, Sustainability (C8) and Popularity/prevalence (C11) in Figure 2 do have zero similarity values with other categories. Therefore, those two categories are excluded from the trees. These maximum trees only demonstrate the relationship among nodes (in this case, category) through linkage values, but the position of each node in the representation does not reflect any real/actual locations (Pawlowski et al., 2007; Jung, 2010).
The figures do reflect the core differences in the ways the concepts are linked: their direction and the strengths of the relationships. One premise underlying this could be that information users have a different pattern than information professionals based on the very training that professionals receive. The professionals are taught to impose a logical structure over the search process and use logical (often Boolean) components to create and construct a search reality. Information users, on the other hand, have similar search concerns without such a framework. They may approach relevance without the planning or evaluative framework embedded in the search processes of professionals. Without the overlay of logic, the users enter into a more fluid environment and their concept of relevance emerges from themselves with strong links to the content of the information they search. In short, the prospect of “search” may be an exploratory event for a user in contrast to a methodology for a professional.
If the professional can visualize the way in which the query terms are linked to document representations then it might be expected that such searches are overly structured in that the user can impose some control over the results. On the other hand, if the end-user views the search as an exploration into an unknown world of potential results then the user may be less likely to ascribe what might occur at the time of query formation. The professional would be expected to have expectations that certain social representations should occur between query and result and this can provide motivation to explore many more “hits” than endusers whose lower expectations provides less motivation to explore a long list of results.
5. DISCUSSION
In this study, the authors sought to examine the meaning and the structure of the concept of relevance from information users’ perspectives and to compare them to information professional perspectives to reify ‘user-defined relevance’ in information science. A theoretical approach to addressing this research question was constructed on social representations theory which studies the shared views of a large number of people about social objects and concepts/beliefs. Specifically, structural analysis proposed by Abric (1993; 2001) was used to materialize the social representations of two groups related to information with users and profe- ssionals positioned into three specific parameters. The three parameters—weighted frequency, sum of similarity, and coreness—were used to identify and isolate how the two groups of individuals view ‘relevance.’
5.1. Facets of the concept of relevance
We attempted to identify the emergent concepts (facets) of relevance from information users and information professionals. What is the meaning of relevance in the context of information seeking and judgment? Public library users and academic library users were recruited for the information user group while librarians, para-professionals, LIS students and faculty were recruited for the information professional group. Participants were not given tasks to make relevance judgments, but were instead asked to respond with three words/phrases that encapsulate relevance and relevance judgments when assessing information. The underlying assumption is that everyone has experience seeking information, and that individuals select information using their own relevance criteria for online and offline materials, as part of everyday life. In addition, it is assumed that through shared experiences in groups, individuals develop relevance criteria which are shared social representations. The elicited concepts about relevance/relevance judgment from information users were refined through content analysis into 26 categories (concepts). First, a coding scheme was developed for the information user group. The same process was used to develop a coding scheme for information professionals. After comparing major identified categories from both groups, it was decided to use the same coding scheme for both groups. The list of categories identified in this study is comprehensive of the facets of relevance as reported in related studies (Schamber, 1991; Park, 1993; Barry and Schamber, 1998; Hirsh, 1999; Toms et al., 2005). The identification of categories which emerged from users created a social definition of the possible facets of relevance concepts. Data was reduced by coding and assigning names for each category. For the category names, two coders who have knowledge in relevance studies in the field of information science tried to gather all word elicitations directly from study participants and to select category names to represent those elicitations best. In that sense, only face validity was ensured. Future studies might consider other forms of validity by analyzing each category name and its representativeness. In this current study, additional data led to measures of the core-periphery structure of relevance.
5.2. Core-periphery facets of relevance
This study revealed the structure of relevance in terms of core and periphery facets (elements). Previous relevance studies attempted to identify and enumerate all concepts (or categories) related to relevance/relevance criteria, but no systematic attempts were made to quantify distances among those concepts. We tried to go beyond those ‘categories’ identified in previous studies. In this study, we measured the structure of those concepts based on distances among attributes (sum of similarity), how often those concepts appear in users elicitation (weighted frequency), and how close those concepts are gathered around the center (coreness). With this approach, relevance and its concepts can be viewed on how they are organized and how those concepts are structurally weighted through core-periphery status in identifying the core concepts and the peripheral concepts. The findings of a coreperiphery analysis show that Topicality, User-needs, Reliability/credibility, and Importance are configured as core concepts for the information user group, while Topicality, User-needs, Reliability/credibility, and Currency are the core concepts for the information professional group. Topicality is a widely perceived notion related to relevance as identified in previous research. Similar or associated topics, subjects, contents, and words are all listed under Topicality. Importance includes “high priority” or “important.” Importance itself is a very vague notion but this word was reported frequently from study participants (fourth highest within the user group) and it did not align itself to be merged into a broader category. Reliability and Currency may clearly be considered as being core status.
A noticeable and interesting category is User-based. Since the paradigm shift to user based approaches in system design and related fields has been introduced in the information science community, many information professionals are knowledgeable about ‘user-centered’ or ‘user-based’ processes. Consequently, seeing User-based as the top core concept is not a surprise. Even though the category name itself is very broad, its measures of high similarity, frequency, and coreness reflect the fact that users expect that their information needs should be met. How information is presented (Format/Presentation) and who is the author (Author) are periphery but close to the core status in terms of the sum of similarity and coreness for the user group. Researchers who emphasize situation dominance in relevance research might raise a question regarding how the facets may vary over different situations or contexts. Previous studies cited earlier (Schamber, 1991; Barry, 1994; Park, 1992; Wang, 1997, for examples) were done under the specific scenarios or contexts given to study participants. Under the realms of social representations theory, however, researchers attempt to investigate talks and activities of members of a community which is related to a social phenomenon or object in whatever social context they encounter in their life, rather than focusing on a particular setting. We collected and analyzed all categories (facets) which directly came from our study participants to depict the object’s (relevance) representations arching over those participants. For example, the IAS Matrix of Table 3 revealed how much these categories are proximate to each other in the space of a specific concept (relevance). All 26 categories collected from G1 (244 participants) could be collapsed into a single space of a concept. Each cell in the matrix indicated the distance from each other in their respective row and column. Altogether, each C (concept) in the Table 3 represents its relationship to other Cs in the space of the concept of relevance. This type of depiction also shows that relevance is multi-faceted.
5.3. Differences or commonalities between the two social collectives
We tried to graphically depict the concepts of relevance examined in order to determine whether there are any differences between the two (G1 and G2) social representations of relevance. The graphical depiction of relationships between those concepts, both core and periphery, reveals how those concepts are closely related in terms of similarity. As indicated in the maximum tree of information users (G1: Figure 1), it is noticeable that the strongest tie is Topicality which is closely related with User-needs (similarity value= .103) and Importance (.093). Topicality is also related moderately with Applicability (.074), Search Process/ method /technology (.070), and Author (.064). Author is closely related with Title (.151). Reliability/credibility is linked with Currency (.096), and Easiness/clarity with Accuracy (.094). Based on these patterns, it is assume that information users tend to think that relevance is really what users perceive of their own needs; their emphasis is on information important for their topic. They also tend to connect reliability and credibility of information to the currency of information.
For information professionals (G2: Figure2), Reliability/credibility is highly related with Currency (.151) and with Topicality (.092). Topicality is related to User-needs (.092) which, in turn, are related to Usefulness (.076). Similar to G1, the information professionals assess relevance topicality based on a userneed coupled with how useful the information is. Title and Author are also related (.089). All other connections show somewhat weak relationships but this also affirms that the two groups do not produce any other major differences. They appear to function as a social collective with shared meanings for the concept of relevance.
6. CONCLUSIONS
The authors of this study attempted to draw a conceptual map of the elements of the concept of relevance. A wide range of information users and information professionals were participants in this study. The categories developed here show significant overlaps with previous studies (Barry, 1994; Schamber, 1991; Park, 1992, 1993; Wang, 1997; Maglaughlin & Sonnenwald, 2002). The focus of this current study is, however, to depict and quantitatively analyze how the different elements of the concept are structured beyond identifying categories of relevance. Our findings reveal the core concepts (elements) and the periphery concepts of relevance and their relationship to one another in terms of coreness, similarity, and weighted frequency. Figures 1 and 2 depict the differing relevance realities among the two groups and it shows that though their focal points are similar, they are sequenced differently. It is the strength of the links between pairs of concepts that reveal differences in how information users may balance their relevance concerns compared to that of information professionals. The findings of this current study do not reveal the implications this may have for the final relevance decisions members of each group may make. That final point was not part of the design of this study but offers a hypothesis for the next investigation: there may be significant differences in the underlying information seeking styles of end users in the ways in which they frame the relevance criteria applicable to personal information retrieval. It might also account for what had been considered fatigue in examining the results obtained from a search: professionals expect that query terms will link to document representations while endusers did not expect such relationships, thus resulting in examination of far fewer results. It appears to us that information professionals frame their concepts in a more logical and predicable way than information users. We hope these findings contribute to reveal another aspect of relevance, as well as provide insights to enhance our understanding of information retrieval in order to improve information systems by accounting for differences in information seeking styles.
APPENDIX
QUESTIONNAIRE
I. Please answer the question below.
When you search information from databases, printed library materials (e.g. books or articles), or the Web (such as Google), you follow clues to information you hope will be relevant to your needs. In other words, you make judgments according to your own relevance priorities (relevance criteria) to select item(s) to pursue.
In the context of information searching/finding from online or printed materials, what does the phrase “relevance criteria” mean to you? List three (3) words/ phrases that come to your mind (in any order).
1)________________________________________
2)________________________________________
3)________________________________________
II. About Yourself:
1. Age:
2. Gender:
3. Residency: City___________________________
4. Education:
-
a) High School Diploma
-
b) Undergraduate Degree
-
c) Graduate Degrees (Masters’ and/or PhD)
-
d) None of the above
-
e) Other: ________________
5. When you examine an item (web site, cataloging record, book, newspaper or magazine article) that you consider to be a possible source for the information you seek, what part do examine first to determine the item’s relevance? (For example: title, authors, abstract, first paragraph of item description) ?
6. You are (a) librarian (professional) ___________