Argonet WEB
- ENGLISH
- ESCI, SCIE, KCI Candidate, SSCI, SSCI, A&HCI, KCI Candidate, A&HCI, KCI, SCOPUS
28권 2호

초록
Abstract
카메라로 촬영한 야외 일반 영상에서 텍스트 이미지를 찾아내고 그 내용을 인식하는 기술은 로봇 비전, 시각 보조 등의 기반으로 활용될 수 있는 매우 중요한 기술이다. 하지만 텍스트 이미지가 저해상도인 경우에는 텍스트 이미지에 포함된 노이즈나 블러 등의 열화가 더 두드러지기 때문에 텍스트 내용 인식 성능의 하락이 발생하게 된다. 본 논문에서는 일반 영상에서의 저해상도 한글 텍스트에 대한 이미지 초해상화를 통해서 텍스트 인식 정확도를 개선하였다. 트랜스포머에 기반한 모델로 한글 텍스트 이미지 초해상화를 수행하였으며, 직접 구축한 고해상도-저해상도 한글 텍스트 이미지 데이터셋에 대하여 제안한 초해상화 방법을 적용했을 때 텍스트 인식 성능이 개선되는 것을 확인하였다.




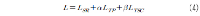







초록
Abstract
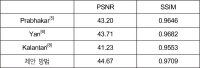
최근 인터넷을 통한 동영상 제공 서비스가 확대됨에 따라 높은 품질의 온라인 컨텐츠에 대한 수요가 급증하고 있다. 그런데 넓은 동적 범위 (dynamic range)를 표현할 수 있는 high dynamic range (HDR) 컨텐츠의 공급은 수요를 따라가지 못하고 있는 실정이다. 따라서 본 논문에서는 HDR 영상 제작의 한 방법으로서, 여러 노출값에서 촬영된 프레임들로 구성된 low dynamic range (LDR) 동영상을 이용해 HDR 영상을 생성하는 방법을 제안한다. 우선, 프레임들 사이에 움직임이 존재하기 때문에 정렬 과정을 통해 이웃 프레임들을 중심 프레임에 맞추어 정렬한다. 이때 내용 (content) 기반의 정렬을 하여 정확도를 높이고, 원래 크기의 입력을 그대로 이용하는 모듈을 함께 사용하여 세부 정보도 잘 살려준다. 그러고 나서 잘 정렬된 다중 프레임들을 합쳐서 하나의 HDR 프레임으로 만들어 준다. 실험을 통해 기존 방법들에 비해 우수한 성능을 보임을 확인하였다.


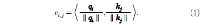










초록
Abstract
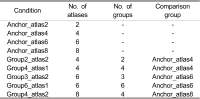
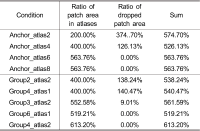
다수의 색상 및 거리 순서쌍으로 구성된 몰입형 영상 압축을 위한 MPEG immersive video (MIV) 표준은 시점 간 중복 영역 제거 후 잔여 영상을 병합하여 높은 압축률을 확보하였다. 비슷한 영역을 표현하는 시점 간 그룹화를 통해 품질 향상 및 선택적 스트리밍 구현이 가능하나, 최근 그룹 기반 MIV 부호화 기술은 활발히 논의되고 있지 않다. 본 논문은 최신 MIV 참조 소프트웨어에서 그룹 기반 부호화 기술을 이식하고, 최적의 그룹 별 시점 및 영상 개수 산출을 위한 실험을 진행하였으며, 출력 영상 내 잔여 영상의 비율을 기반으로 전역적 영상 표현을 위한 최적의 출력 영상 수를 결정하는 기법을 제안한다.






















초록
Abstract
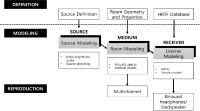
본 논문에서는 가상환경에 위치한 청취자의 움직임에 대응하여 실시간으로 6DoF 공간음향을 제공하는 공간음향 렌더링 시스템에 대해 소개한다. 본 시스템은 MPEG-I Immersive Audio CfP 대응을 위하여 MPEG-I AEP를 개발환경으로 사용하여 구현되었으며 인코더와, 디코더를 포함하는 렌더러로 구성된다. 인코더는 인코더 입력 포맷(EIF) 파일에 포함된 가상공간 장면의 공간적 오디오 파라미터와, SOFA 파일로 제공되는 음원의 지향성 정보 등의 메타데이터를 오프라인으로 부호화하여 비트스트림으로 전달하는 역할을 하며, 렌더러는 전달된 비트스트림을 수신하여 청취자의 위치에 따라 실시간으로 6DoF 공간음향 렌더링을 수행한다. 개발된 렌더링 시스템에 적용한 주요 공간음향 처리 기술로는 음원 효과 및 장애물 효과 처리 기술이 있으며, 그 외 시스템 동작에 필요한 기술로는 도플러 효과 및 음장효과 처리 기술 등이 있다. 개발된 시스템에 대한 성능평가 결과로서 자체 주관평가 결과를 소개한다.




























초록
Abstract
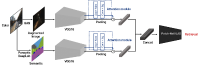
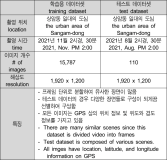
자율주행은 4차 산업의 핵심 기술로 차, 드론, 자동차, 로봇 등 다양한 곳에 응용 가능하다. 그 중 위치 추정 기술은 GPS, 센서, 지도 등을 활용하여, 객체나 사용자의 위치를 파악하는 기술로 자율주행을 구현하기 위한 핵심적인 기술 중 하나이다. GPS나 LIDAR 등의 센서를 이용하여 위치 추정이 가능하지만, 이는 매우 고가이고 무거운 장비를 탑재해야 하며 지하 혹은 터널 등 전파 방해가 있는 곳의 경우 정밀한 위치 추정이 어렵다는 단점이 있다. 본 논문에서는 이를 보완하기 위해 저가의 비전 카메라로 획득한 컬러 영상을 입력으로 하여 관심 영역 추출 네트워크와 영상 분할 지도를 이용한 영상 검색 기술을 제안한다.












초록
Abstract
최근 인공지능 모델을 이용한 얼굴인식, 얼굴 수정 등 다양한 얼굴 작업들이 실생활에도 광범위하게 사용되고 있다. 그러나 모델의 학습에 사용되는 대부분의 얼굴 데이터셋은 사회활동이 활발한 특정 나이에 편중되고, 어린아이나 노인의 데이터가 적은 경향이 있다. 이와 같은 데이터셋 불균형 문제는 모델의 학습에도 좋지 않은 영향을 끼쳐, 아이나 노인같이 데이터가 적은 나이의 사람이 인공지능 모델을 사용할 때 사회활동이 활발한 나이의 사람이 사용할 때보다 성능이 떨어질 수 있고, 이들의 인공지능 모델 사용을 어렵게 할 가능성이 높다. 이를 개선하기 위해 본 논문은 특징 분해를 활용하여 얼굴 영상으로부터 나이를 분류하고 목표 나이로 합성하는 기법을 제안한다. 제안하는 기법은 FFHQ-Aging 데이터셋을 이용한 정량적, 정성적 평가를 통해 기존의 방법보다 더 나은 성능을 보인다.




