- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI
 ISSN : 2287-9099
ISSN : 2287-9099
Vol.6 No.4
Abstract
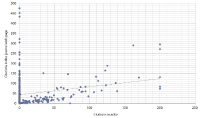
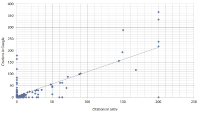
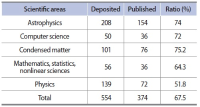
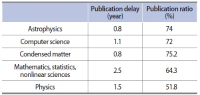
This article shows an approach to the study of two fundamental aspects of the prepublication of scientific manuscripts in specialized repositories (arXiv). The first refers to the size of the interaction of “standard papers” in journals appearing in the Web of Science (WoS)—now Clarivate Analytics—and “non-standard papers” (manuscripts appearing in arXiv). Specifically, we analyze the citations found in the WoS to articles in arXiv. The second aspect is how publication in arXiv affects the citation count of authors. The question is whether or not prepublishing in arXiv benefits authors from the point of view of increasing their citations, or rather produces a dispersion, which would diminish the relevance of their publications in evaluation processes. Data have been collected from arXiv, the websites of the journals, Google Scholar, and WoS following a specific ad hoc procedure. The number of citations in journal articles published in WoS to preprints in arXiv is not large. We show that citation counts from regular papers and preprints using different sources (arXiv, the journal’s website, WoS) give completely different results. This suggests a rather scattered picture of citations that could distort the citation count of a given article against the author’s interest. However, the number of WoS references to arXiv preprints is small, minimizing this potential negative effect.
Abstract
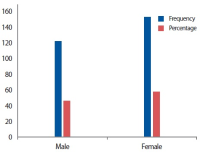
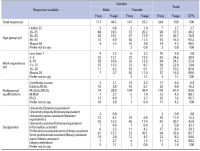
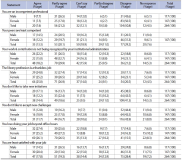
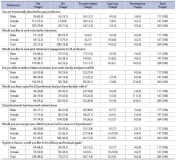
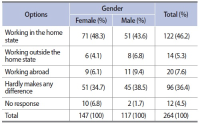
This study assesses the psychological aspects which influence job satisfaction among library and information science professionals. The study is based on primary data collected from the library and information science professionals working in the higher education institutions of Jammu and Kashmir, India. In all 264 responses were collected, comprising 44.3% male respondents and 55.7% females. The majority, 74.2% of respondents, are under 45 years of age, while 67.4% of respondents have a master’s degree in library and information science. Of the total respondents, 7.6% conceded to being incompetent, while 13.3% viewed their peers as incompetent. The majority, 25% of respondents, replied that the library profession is a thankless job and 70.8% of respondents viewed that they are emotionally attached to their profession, while at the gender level, compared to 75.5% females, 65% of male respondents admitted to being emotionally attached to their profession. The encouraging part is that 26.5% of respondents replied that they love doing their job beyond office hours and 75.8% of respondents replied that they would not seek voluntary retirement, while 41.7% of respondents showed willingness to continue working as library and information science professionals postretirement, if engaged.

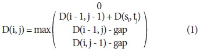
Abstract
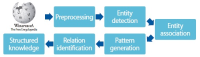
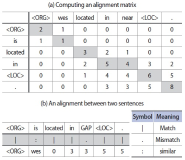
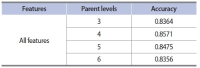
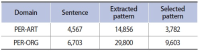
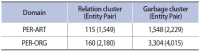
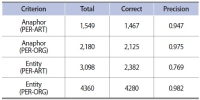
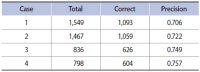
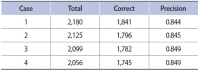
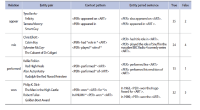
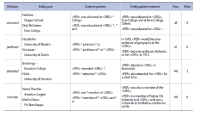
Wikipedia is composed of millions of articles, each of which explains a particular entity with various languages in the real world. Since the articles are contributed and edited by a large population of diverse experts with no specific authority, Wikipedia can be seen as a naturally occurring body of human knowledge. In this paper, we propose a method to automatically identify key entities and relations in Wikipedia articles, which can be used for automatic ontology construction. Compared to previous approaches to entity and relation extraction and/or identification from text, our goal is to capture naturally occurring entities and relations from Wikipedia while minimizing artificiality often introduced at the stages of constructing training and testing data. The titles of the articles and anchored phrases in their text are regarded as entities, and their types are automatically classified with minimal training. We attempt to automatically detect and identify possible relations among the entities based on clustering without training data, as opposed to the relation extraction approach that focuses on improvement of accuracy in selecting one of the several target relations for a given pair of entities. While the relation extraction approach with supervised learning requires a significant amount of annotation efforts for a predefined set of relations, our approach attempts to discover relations as they occur naturally. Unlike other unsupervised relation identification work where evaluation of automatically identified relations is done with the correct relations determined a priori by human judges, we attempted to evaluate appropriateness of the naturally occurring clusters of relations involving person-artifact and person-organization entities and their relation names.
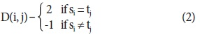
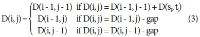
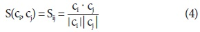
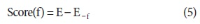
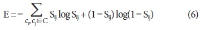
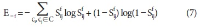


Abstract
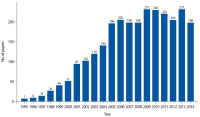
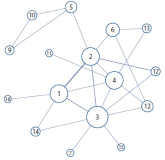
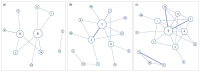
While the body of research on metadata has grown substantially, there has been a lack of systematic analysis of the field of metadata. In this study, we attempt to fill this gap by examining metadata literature spanning the past 20 years. With the combination of a text mining technique, topic modeling, and network analysis, we analyzed 2,713 scholarly papers on metadata published between 1995 and 2014 and identified main topics and trends in metadata research. As the result of topic modeling, 20 topics were discovered and, among those, the most prominent topics were reviewed in detail. In addition, the changes over time in the topic composition, in terms of both the relative topic proportions and the structure of topic networks, were traced to find past and emerging trends in research. The results show that a number of core themes in metadata research have been established over the past decades and the field has advanced, embracing and responding to the dynamic changes in information environments as well as new developments in the professional field.




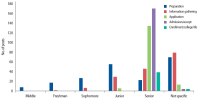
Abstract
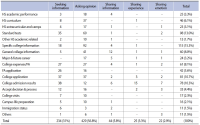
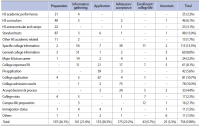
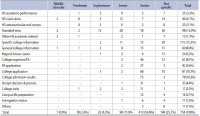
This study aims to understand the information needs of Korean immigrant mothers in the United States for their high school children’s college preparation. A content analysis was conducted for the messages posted to a “motherhood” forum on the MissyUSA website. In total, 754 posts were analyzed in terms of a child’s grade, college preparation stage, type of post, and topic of post. The study found that there is a range of information needed at different stages in a child’s education. Many of the demonstrated information needs showed similarities to those of other immigrant groups, but there were also community-specific themes, such as an emphasis on STEM (science, technology, engineering, and math) and standardized tests. The forum was mainly used for factual questions, not emotional support. We concluded that the findings of the study would help researchers in understanding immigrant information needs for the college application process and how information professionals and educators could combine the needs of different ethnic groups to create customized services for them.