- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

Vol.9 No.1
Abstract
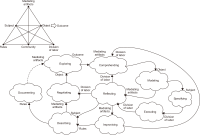
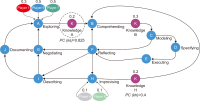
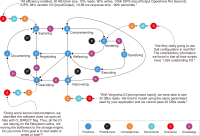
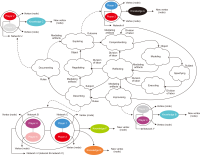
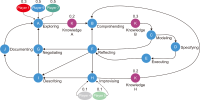
This study introduces novel research using Practice Context Models supported by Knowledge Networks and Percolation Theory with the aim to contribute to knowledge management in Proof-of-Concept (PoC) activities. The authors envision this proposal as a potential instrument to identify network structures based on a percolation (propagation) threshold and to analyze the importance of nodes (e.g., practitioners, practices, competencies, movements, and scenarios) during the percolation of knowledge in PoC activities. After thirty months immersed in the natural PoC habitat, acting as observers and practitioners, and supported by an ethnographic exercise and a designer-research mindset, the authors identified the production of meaning in PoC activities occurring in a hermeneutic circle characterized by the presence of several knowledge networks; thus, discovering the ‘natural knowledge’ in PoC as a spectrum of cognitive development spread throughout its network, as each node could produce and disseminate certain knowledge that flows and influences other nodes. Therefore, this research presents the use of Practice Context Models ‘connected’ to Knowledge Networks and Percolation Theory as a potential and feasible proposal to be built using the attribution of values (weights) to the nodes (e.g., practitioners, practices, competencies, movements, scenarios, and also knowledge) in the context of PoC with the aim to allow the players (e.g., PoC practitioners) to have more flexibility in building alliances with other players (new nodes); that is, focusing on those nodes with higher value (focus on quality) in collaboration networks, i.e., alliances (connections) with the aim to contribute to knowledge management in the context of PoC.
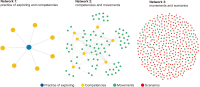
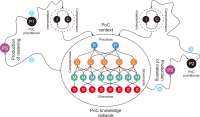

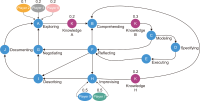
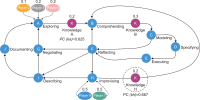
Abstract
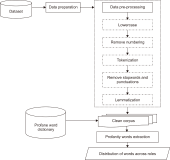
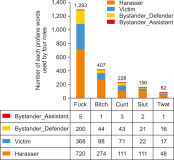
The popularity of social networking sites (SNS) has facilitated communication between users. The usage of SNS helps users in their daily life in various ways such as sharing of opinions, keeping in touch with old friends, making new friends, and getting information. However, some users misuse SNS to belittle or hurt others using profanities, which is typical in cyberbullying incidents. Thus, in this study, we aim to identify profane words from the ASKfm corpus to analyze the profane word distribution across four different roles involved in cyberbullying based on lexicon dictionary. These four roles are: harasser, victim, bystander that assists the bully, and bystander that defends the victim. Evaluation in this study focused on occurrences of the profane word for each role from the corpus. The top 10 common words used in the corpus are also identified and represented in a graph. Results from the analysis show that these four roles used profane words in their conversation with different weightage and distribution, even though the profane words used are mostly similar. The harasser is the first ranked that used profane words in the conversation compared to other roles. The results can be further explored and considered as a potential feature in a cyberbullying detection model using a machine learning approach. Results in this work will contribute to formulate the suitable representation. It is also useful in modeling a cyberbullying detection model based on the identification of profane word distribution across different cyberbullying roles in social networks for future works.

Abstract
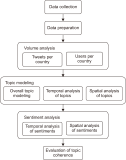
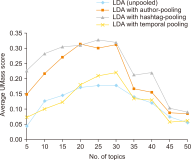
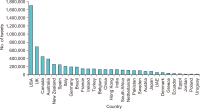
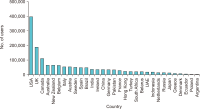
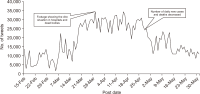
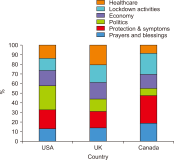
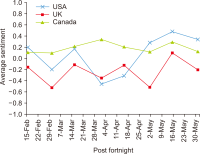
The study reported in this paper aimed to evaluate the topics and opinions of COVID-19 discussion found on Twitter. It performed topic modeling and sentiment analysis of tweets posted during the COVID-19 outbreak, and compared these results over space and time. In addition, by covering a more recent and a longer period of the pandemic timeline, several patterns not previously reported in the literature were revealed. Author-pooled Latent Dirichlet Allocation (LDA) was used to generate twenty topics that discuss different aspects related to the pandemic. Time-series analysis of the distribution of tweets over topics was performed to explore how the discussion on each topic changed over time, and the potential reasons behind the change. In addition, spatial analysis of topics was performed by comparing the percentage of tweets in each topic among top tweeting countries. Afterward, sentiment analysis of tweets was performed at both temporal and spatial levels. Our intention was to analyze how the sentiment differs between countries and in response to certain events. The performance of the topic model was assessed by being compared with other alternative topic modeling techniques. The topic coherence was measured for the different techniques while changing the number of topics. Results showed that the pooling by author before performing LDA significantly improved the produced topic models.



Abstract
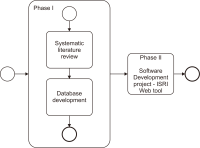
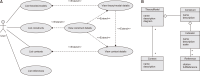
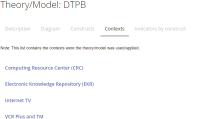
This paper presents the ISRI (Information Systems Research Indicators) Web tool, publicly and freely available at isri.sciencesphere.org. Targeting Information Systems (IS) researchers, it compiles and organizes IS adoption and use theories/models, constructs, and indicators (measuring variables) available in the scientific literature. Aiming to support the IS theory development process, the purpose of ISRI is to gather and systematize information on research indicators to help researchers and practitioners’ work. The tool currently covers eleven theories/models: DeLone and McLean’s IS Success Model (D&M ISS); Diffusion of Innovations Theory (DOI); Motivational Model (MM); Social Cognitive Theory (SCT); Task-Technology Fit (TTF); Technology Acceptance Model (TAM); Technology-Organization-Environment Framework (TOE); Theory of Planned Behavior (TPB); Decomposed Theory of Planned Behavior (DTPB); Theory of Reasoned Action (TRA); and Unified Theory of Acceptance and Use of Technology (UTAUT). It also includes currently over 400 constructs, nearly 2,500 indicators, and about 60 application contexts related to the models. For the creation of the tool’s database, nearly 580 references were used.





Abstract
Political weblogs are as diverse as political viewpoints are. In the period of Prime Minister Yingluck Shinawatra, several political crises occurred, such as opposition to the Amnesty Act, the constitutional amendment, and the anti-government protests. Remarkably, during this time, social media were used as a platform for political expressions. This study employed a content analysis method to explore twenty-nine Thai political weblogs established during the period of Prime Minister Yingluck Shinawatra’s administration. At the time, the most prominent Thai political weblogger was Nidhi Eawsriwong. Not surprisingly, the Pheu Thai Party and the Democrat Party were the most frequently appearing political parties in these weblog’s posts. Most contents in these posts were related to government protesters by the People’s Democratic Reform Committee (PDRC) and the coup d’état. The purposes of writing such weblogs were to express feelings and thoughts about Thai politics and to provide political information to the general public. The findings from this investigation revealed two significant uses of Thai political weblogs: the communication media for political expressions and viewpoints (a safe online space for political engagement and participation), and vital sources for Thai political information and news (social narratives).
Abstract
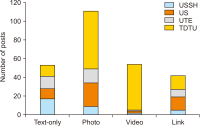
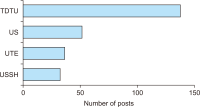
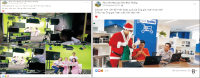
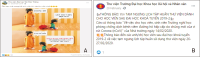
This study explores Facebook use in Vietnamese academic libraries by analysing libraries’ posts on their Facebook pages and library users’ interaction with those posts. A total of 260 posts on four academic libraries’ Facebook pages were examined using the content analysis method. The findings reveal that Facebook was mainly used to encourage reading and to transmit announcements. Most of the academic libraries published one post a week. The photo was the most frequent media type of libraries’ posts and gained a higher level of interaction than other posts. According to the research results, the user engagement was low, and the user interaction with libraries’ posts generally was in the form of reaction. The findings can help better understand Facebook use in Vietnamese academic libraries and may assist libraries in creating a plan for using Facebook more effectively.