- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

Vol.9 No.4

Abstract
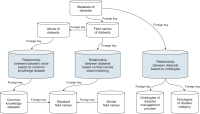
Library communities face many problems and limitations in describing alternative format materials based on the traditional MAchine Readable Cataloging (MARC) structure. To address these problems, this research proposes an XML-based descriptive metadata framework that establishes general but fundamental bibliographic aspects of various alternative format materials by providing core elements that are essential in describing these materials. Different from existing bibliographic structures, the proposed metadata framework can represent a fundamental descriptive structure by establishing four upper-level categories, 17 core elements, and 10 sub-elements in a hierarchical structure optimized to alternative format materials. By using this principal descriptive structure, the proposed metadata framework can guide different institutions in the creation of bibliographic records for these materials in a consistent way. It is also expected to address the difficulties in describing alternative format materials in library communities and enhance the information accessibility of individuals with various types of disabilities. In addition, the proposed metadata framework is an alternative approach which functions as a mediator between heterogeneous characteristics of alternative format materials and the existing bibliographic structures in library communities.


Abstract
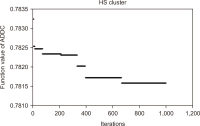
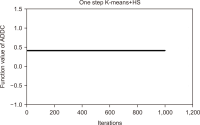
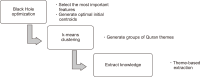
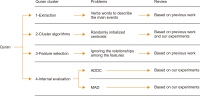
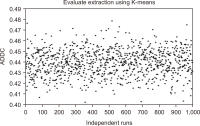
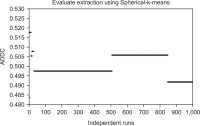
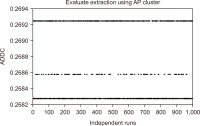
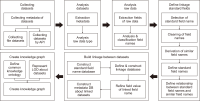
Text clustering is one of the most commonly used methods for detecting themes or types of documents. Text clustering is used in many fields, but its effectiveness is still not sufficient to be used for the understanding of Arabic text, especially with respect to terms extraction, unsupervised feature selection, and clustering algorithms. In most cases, terms extraction focuses on nouns. Clustering simplifies the understanding of an Arabic text like the text of the Quran; it is important not only for Muslims but for all people who want to know more about Islam. This paper discusses the complexity and limitations of Arabic text clustering in the Quran based on their themes. Unsupervised feature selection does not consider the relationships between the selected features. One weakness of clustering algorithms is that the selection of the optimal initial centroid still depends on chances and manual settings. Consequently, this paper reviews literature about the three major stages of Arabic clustering: terms extraction, unsupervised feature selection, and clustering. Six experiments were conducted to demonstrate previously un-discussed problems related to the metrics used for feature selection and clustering. Suggestions to improve clustering of the Quran based on themes are presented and discussed.







Abstract
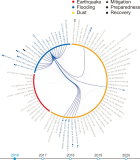
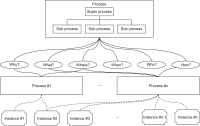
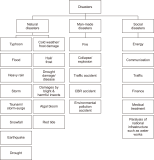
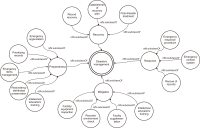
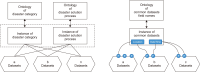
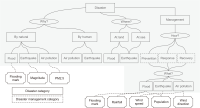
In a situation where there are multiple diverse datasets, it is essential to have an efficient method to provide users with the datasets they require. To address this suggestion, necessary datasets should be selected on the basis of the relationships between the datasets. In particular, in order to discover the necessary datasets for disaster resolution, we need to consider the disaster resolution stage. In this paper, in order to provide the necessary datasets for each stage of disaster resolution, we constructed a disaster type and disaster management process ontology and designed a method to determine the necessary datasets for each disaster type and disaster management process step. In addition, we introduce a method to determine relationships between datasets necessary for disaster response. We propose a method for discovering datasets based on minimal relationships such as “isA,” “sameAs,” and “subclassOf.” To discover suitable datasets, we designed a knowledge exploration model and collected 651 disaster-related datasets for improving our method. These datasets were categorized by disaster type from the perspective of disaster management. Categorizing actual datasets into disaster types and disaster management types allows a single dataset to be classified as multiple types in both categories. We built a knowledge exploration model on the basis of disaster examples to ensure the configuration of our model.


Abstract
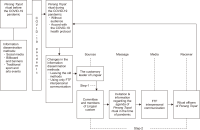
This study aims to unravel the shift in the customary method of disseminating information about the ritual of Perang Topat (literally translated as “rice-cake war”) as carried out by the custom community of Kemaliq Lingsar in the West Lombok Regency of Indonesia during the COVID-19 pandemic. Grounded in the ethnography of communication research methodology, this study examines the process of the cultural ritual during the 2020 period of the pandemic and compares it to the ones held in 2018 and 2019 (before the current pandemic). Drawing on findings from observations, in-depth interviews, and documentation, it was revealed that the traditional or custom-oriented community of Kemaliq Lingsar abandoned all three prominently used methods of disseminating the information of the Perang Topat ritual that had been used prior to the pandemic, and that they were replaced by a strategy with solely face-to-face (FTF) interpersonal communication carried out by visiting the homes of the target participants of the cultural event. This method was relevant to the current viral crisis because it enabled the committee to minimize the number of spectators which might potentially violate COVID-19 health protocols. This finding also reinforces the hypothetical statement that interpersonal communication via FTF is effective in disseminating information in a limited manner and empowering the emotional bond between the individuals who share relationships and similar interests. The findings of the present study can be a reference for any events where physical distancing must be strictly imposed and require a limit to the number of participants during the pandemic.



Abstract
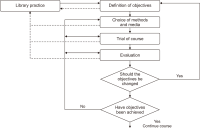
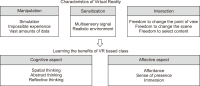
Virtual Reality (VR) is one of the core components of the fourth industrial revolution as a technology that makes the virtual world feel as if it is real. VR is being used in various fields such as entertainment, advertisement, education, medical care, training, sports, and tourism, as well as providing contents for such things as games and videos. Libraries are already looking for ways to utilize VR from various angles, such as operating experiential programs. The purpose of this thesis is to develop and propose a VRbased library user education program. In order to achieve the purpose of the study, we analyzed previous studies from a theoretical perspective to find a way to construct a user education program, and also to derive possible implications based on examples of countries such as the United States and Korea that are already introducing and applying VR technology to library services. Therefore, the user education program proposed in this study can be used as a basic building block when many libraries want to develop VR-based programs in the future.
Abstract
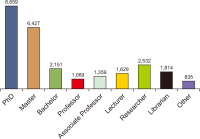
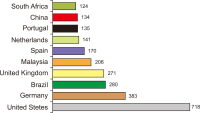
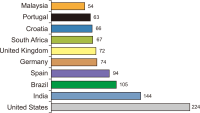
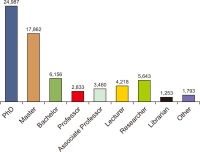
Mendeley reader count is good evidence of the early impact of scientific output since it appears before citations. This paper aims to scope and compare Mendeley readers of Library and Information Science (LIS) articles published from India and China. Mendeley readership data for the highly cited 1,000 articles in Web of Science are extracted using Webometric Analyst for both countries and are analysed using Excel and SPSS. The findings reveal that LIS articles that are published from China got more readers as compared to LIS articles published from India with an excess of 97 readers per paper on Mendeley. The occupational status of readers tells that PhD students are the top readers for both the countries’ publications, followed by masters students. Discipline-wise readership shows that readers were spread across 29 different fields, with the highest readers from business, management and accounting, followed by computer science for both countries’ publications. Location-wise readership depicts that the top engaged readers are from the United States for both the countries’ publications. Finally, the study reports a positive association between citations and Mendeley bookmarks, justifying that Mendeley readership can be used to measure the early research impact of LIS scholarship in both countries.