- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI
 ISSN : 2287-9099
ISSN : 2287-9099
Vol.7 No.2
Abstract
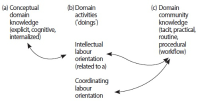
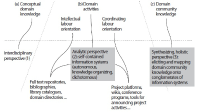
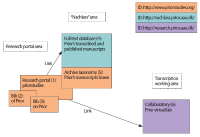
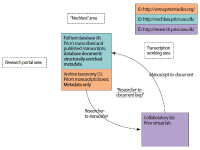
The paper explores how information science knowledge can be used systematically in digital, interdisciplinary research settings and gives a conceptual analysis of the relationship between information science knowledge as donor and other research as receiver in an interdisciplinary project environment. The validity of the approach is demonstrated by the author’s work on the project “The Primacy of Tense: A. N. Prior Now and Then.” The study proposes a hybrid approach, combining analysis and synthesis. The analytical component identifies information systems, assigns an information system type to them, and accesses the information science knowledge associated with that type. The synthetic part focuses on the connections between information systems according to the receiver discipline’s practices. The paper makes explicit the actions of experienced information professionals, thereby making their expertise accessible to others. The analytical and synthetic strategies are explained by linking them to two modes of researchers in the receiver discipline, how they act as researchers and what they know about it. The paper offers information professionals concrete assistance with identification of the appropriate strategy for accessing professional knowledge and taking appropriate actions and development decisions.

Abstract
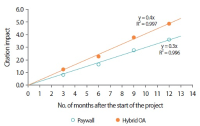
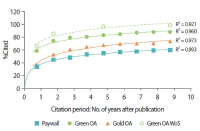
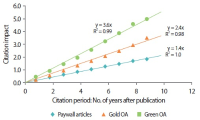
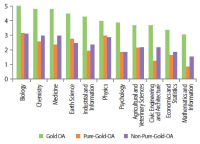
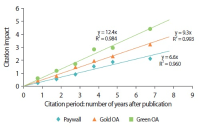
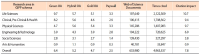
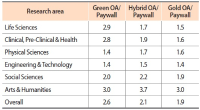
We report results of selection-bias-free approaches to the analysis of the impact of open access (OA) models on citation metrics. We studied reference groups of Gold and Green OA articles and the group of non-OA (Paywall) articles with the new functionality of the Web of Science Core Collection database, the InCites platform of Clarivate Analytics, and the Dimensions database of Digital Science. For each reference group we obtained the values of the percent of cited articles and citation impact and their dependence on the depth of the citation period. Different research fields were analyzed in two schemas of the InCites platform. We report the higher values and growth rates of the citation metrics: citation impact and %Cited, in the OA reference groups over the Paywall group. The Green OA articles demonstrate the highest values of citation metrics among all the OA models. Dependence of the value of citation impact on citation period follows linear law with R2 values close to 0.9–1.0. The overall annual growth rates of citation impact of the Green OA, Gold OA, and the Paywall articles, k equal, respectively, 3.6, 2.4, and 1.4 in Dimensions and 4.6, 3.6, and 2.3 in the Web of Science Core Collection. We suppose that earlier results reported for the articles in pure OA journals vs. articles in Paywall journals were affected by the high citation impact of the Green and Hybrid OA articles that could not be elucidated in the Paywall journals at that time.


Abstract
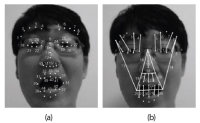
A convolutional neural network (CNN) has been widely used in facial expression recognition (FER) because it can automatically learn discriminative appearance features from an expression image. To make full use of its discriminating capability, this paper suggests a simple but effective method for CNN based FER. Specifically, instead of an original expression image that contains facial appearance only, the expression image with facial geometry visualization is used as input to CNN. In this way, geometric and appearance features could be simultaneously learned, making CNN more discriminative for FER. A simple CNN extension is also presented in this paper, aiming to utilize geometric expression change derived from an expression image sequence. Experimental results on two public datasets (CK+ and MMI) show that CNN using facial geometry visualization clearly outperforms the conventional CNN using facial appearance only.
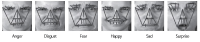

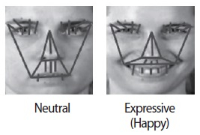



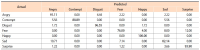

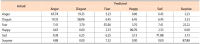
Abstract
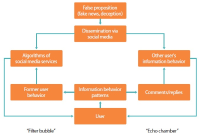
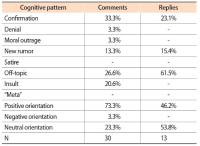
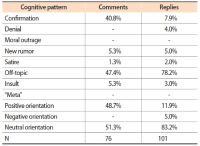
Although fake news has been present in human history at any time, nowadays, with social media, deceptive information has a stronger effect on society than before. This article answers two research questions, namely (1) Is the dissemination of fake news supported by machines through the automatic construction of filter bubbles, and (2) Are echo chambers of fake news man-made, and if yes, what are the information behavior patterns of those individuals reacting to fake news? We discuss the role of filter bubbles by analyzing social media’s ranking and results’ presentation algorithms. To understand the roles of individuals in the process of making and cultivating echo chambers, we empirically study the effects of fake news on the information behavior of the audience, while working with a case study, applying quantitative and qualitative content analysis of online comments and replies (on a blog and on Reddit). Indeed, we found hints on filter bubbles; however, they are fed by the users’ information behavior and only amplify users’ behavioral patterns. Reading fake news and eventually drafting a comment or a reply may be the result of users’ selective exposure to information leading to a confirmation bias; i.e. users prefer news (including fake news) fitting their pre-existing opinions. However, it is not possible to explain all information behavior patterns following fake news with the theory of selective exposure, but with a variety of further individual cognitive structures, such as non-argumentative or off-topic behavior, denial, moral outrage, meta-comments, insults, satire, and creation of a new rumor.
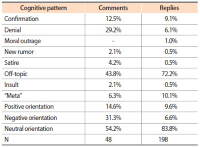
Abstract
A theory of public knowledge is offered for the purposes of defining more clearly its role in information systems and classification schemas. Public knowledge is knowledge intended to be available for use in a public system. It is knowledge accessible to the public or knowledge in the public arena as opposed to the other seemingly multitudinous ways to describe knowledge. Furthermore, there are many different public arenas or small worlds. Public knowledge, irrespective of these different arenas, has four important overlying characteristics: It is consensual, it does not imply complete truth or certainty, it is autonomous, and it has a constant renewal of old knowledge with new knowledge. Each of these attributes has been culled from a study of the works of Patrick Wilson, Karl Popper, and John Ziman.