- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

Arabic Text Clustering Methods and Suggested Solutions for Theme-Based Quran Clustering: Analysis of Literature

Rosalina Abdul Salam (Faculty of Science and Technology, Universiti Sains Islam Malaysia, Nilai, Negeri Sembilan, Malaysia)
Jaffar Atwan (Prince Abdullah Bin Ghazi Faculty of ICT, AL-Balqa Applied University, Salt, Jordan)
Malik Jawarneh (Faculty for Computing Sciences, Gulf College, Muscat, Sultanate of Oman)

Abstract
Text clustering is one of the most commonly used methods for detecting themes or types of documents. Text clustering is used in many fields, but its effectiveness is still not sufficient to be used for the understanding of Arabic text, especially with respect to terms extraction, unsupervised feature selection, and clustering algorithms. In most cases, terms extraction focuses on nouns. Clustering simplifies the understanding of an Arabic text like the text of the Quran; it is important not only for Muslims but for all people who want to know more about Islam. This paper discusses the complexity and limitations of Arabic text clustering in the Quran based on their themes. Unsupervised feature selection does not consider the relationships between the selected features. One weakness of clustering algorithms is that the selection of the optimal initial centroid still depends on chances and manual settings. Consequently, this paper reviews literature about the three major stages of Arabic clustering: terms extraction, unsupervised feature selection, and clustering. Six experiments were conducted to demonstrate previously un-discussed problems related to the metrics used for feature selection and clustering. Suggestions to improve clustering of the Quran based on themes are presented and discussed.
- keywords
- text mining, Arabic text clustering algorithms, terms extraction, un-supervised feature selection, optimal initial centroid
1. INTRODUCTION
The use of text clustering as an analysis tool for detecting and understanding Arabic text enables people to understand Quran text. Users can start understanding the Quran by going through the words or verses. The Quran consists of thirty chapters and each chapter includes many Quranic verses. Each chapter belongs to more than one theme such as Zakat (alms), Inheritance, Prayers, and others. Verses of each chapter are required to be grouped based on the clustering of themes. Therefore, Arabic text clustering becomes very important as an analysis tool for everyone in understanding the Quran. This is the motivation for clustering the themes of the Quran. The main reason why text clustering has not yet been used to group the Quran text is the degraded poor performance of the three tasks: terms extraction, unsupervised feature selection. Some tasks use text mining, such as sentiment analysis (Touahri & Mazroui, 2021), Twitter topic detection (Mottaghinia et al., 2021), concept map construction (Qasim et al., 2013), and systematic review support (Ananiadou et al., 2009), but it is still of great significance to increase the performance of text clustering. The Quran is an essential guide to the life of all humankind, both Muslims and non-Muslims. It covers all aspects of human life, including biology, information technology, law, social order, politics, business, economics, and individual responsibilities (Rostam & Malim, 2021). In short, the Quran represents a sea of knowledge (Yauri et al., 2013).
The great knowledge incorporated in the Quran stresses the importance of exploring such holy texts using automated applications. In fact, the information technology is a system consisting of a medium, infrastructure, and methods for gaining, transferring, accessing, interpreting, saving, organizing, and using data meaningfully (Azad & Deepak, 2019). People who seek to understand Islam could find easier ways to find answers to their various queries (Abualkishik et al., 2015). However, understanding the Quran requires more than just reading its translation. Hence, making the content of the Quran available to everyone is still a big challenge. Therefore, it is important to take one’s level of experience into account when presenting the content of the Quran.
The aim of this study is to investigate the limitation of text clustering, because there is a need to increase its quality. Although text clustering has been studied for many years, it is still an important research domain and its methods require further improvements (Alghamdi & Selamat, 2019). The rest of the paper is structured as: Sections 2 and 3 provide a review of text clustering and the problems of its application. However, Section 4 presents possible research directions and the proposed solutions for extraction, unsupervised feature selection, and clustering. Finally, Section 5 concludes the paper.
2. TEXT CLUSTERING FOR ARABIC LANGUAGE AND THE QURAN
Text clustering is one of the most commonly used methods for detecting themes or types of documents (Alghamdi & Selamat, 2019). It involves three main processes (Bsoul et al., 2014, 2016a, 2016b): The first process is document pre-processing, which is needed for any type of document such as finance, medical, or law documents. It removes unimportant words and symbols from the documents. The second process is to extract the most important terms and weights from the features of the documents then calculate the similarities among them. Then, feature selection is employed to select the optimal features for the clustering algorithm. The last process is clustering. There are two main types of cluster techniques, hierarchical and partitioning, as shown in Fig. 1. The organization of the paper is shown in Fig. 2. This work focuses on the domain of Quran themes and the main weaknesses of Arabic text clustering.
Fig. 1
Text clustering structure. BOW, Bag of Words; NER, named entity recognition; TFIDF, term frequency–inverse document frequency; DNA, deoxyribonucleic acid; SOM, self-organizing map; AP, affinity propagation.
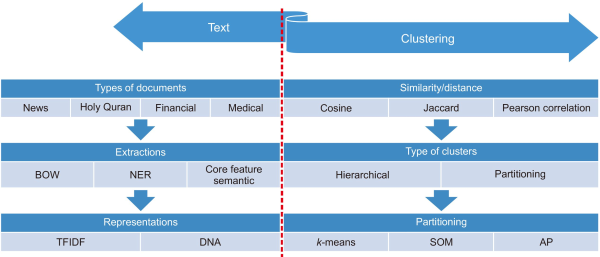
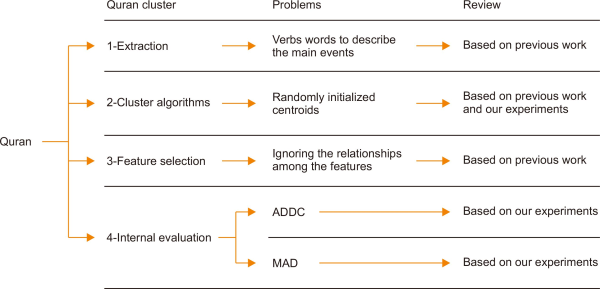
Fig. 2
Organization of the paper. ADDC, average distance of documents to the cluster centroid; MAD, mean absolute difference.
In fact, there are a number of aspects that are involved in understanding the Quran, such as the reasons of revelation, the knowledge of Makkee and Madanee (that is, the places where a chapter “surah” was revealed), the knowledge of the various forms that were revealed, understanding the Quran’s abrogated rulings and verses, the various classifications of its verses, the knowledge of the themes, and the analysis of its grammar (Harrag, 2014). Recently, many studies have explored how Quranic text can be stored, processed, and extracted to further understand its content. The Quranic ontology (Beirade et al., 2021) and other approaches can be found in Raharjo et al. (2020) and Farhan et al. (2020). Other studies have used information retrieval (IR) (Raharjo et al., 2020; Safee et al., 2016) or text classifiers to detect verses or chapters in the Quran (Safee et al., 2016). The main objective of this study is to provide people with better solutions to understand the Quran and to disseminate knowledge using recent methods and technology. Hence, this study focuses on employing Arabic text clustering to cluster the themes of the Quran based on the highest similarity between the verses. In the next section, the process of Arabic text clustering and its limitations are presented in detail.
3. TEXT CLUSTERING PROCESS
This section reviews comprehensive previous related work, namely the three phases of text clustering: terms extraction, unsupervised feature selection, and clustering.
3.1. Terms Extraction
The extraction of Arabic words is one of the processes undertaken in Arabic Cluster (Alghamdi & Selamat, 2019), which functions to extract the most important terms needed to retrieve pertinent information. Consequently, various techniques have been suggested in the literature for such purposes, which are categorized into three main categories: Bag of Words (BOW), Bag of Concepts (BOC), and Bag of Narratives (BON) (Saloot et al., 2016). Several researchers have focused on extracting information from the terms by employing named entity recognition (Mesmia et al., 2018), bag-of-words (BOW) (Hmeidi et al., 2008), n-grams (Al-Salemi & Aziz, 2011), and lemmatization algorithms (Al-Shammari & Lin, 2008; Al-Zoghby et al., 2018). To make the terms extraction stage become effective, researchers used ontology-based extraction (Al-Zoghby et al., 2018), semantic extraction (Al-Zoghby et al., 2018), Arabic word sense disambiguation (Elayeb, 2019; Salloum et al., 2018), semantic word embedding (El Mahdaouy et al., 2018), and semantic relationships (Benabdallah et al., 2017). However, text data often presents challenges because of their high dimensionality and ambiguous or overlapping word senses. Previous studies have proposed various terms extraction methods such as BOW, N-grams, and named entity recognition to address the high dimensionality of the terms. These methods are called syntactic extraction. Overlapping word senses like the semantic words found in Word-Net are called semantic extraction. In this paper, we will discuss syntactic extraction and why researchers are moving towards developing and using semantic extraction.
Al-Smadi et al. (2019) have worked specifically on extraction based on morphological, syntactic, and semantic extract Arabic terms using supervised machine learning, which is founded that the syntactic better than morphological, and semantic. Besides this, Harrag (2014) employed Named entity approach to extract the most important Arabic terms, this approach have limitation in distinguished between two similar sentences. For that limitation Helwe and Elbassuoni (2019) their approach relies only on word embedding from the Arabic name entity to made difference between two similar sentences.
Al-Salemi and Aziz (2011) have assessed the BOW method and three levels of N-gram (3, 4, and 5) for extraction, whereby the outcomes obtained via Naïve Bayes classifier have revealed the BOW to outperform all of the N-gram levels tested. Similarly, Mustafa (2005) has positioned a technique for Arabic text searching in Arabic IR by implementing two methods for information extraction, namely contiguous N-grams and hybrid N-grams; the hybrid N-grams are better than contiguous N-grams and both methods extracted the nouns. Furthermore, Al-Shammari and Lin (2008) have stemmed nouns and verbs by using Educated Text Stemmer (ETS) as the stemmer for the roots of Arabic words. The algorithm is aimed towards noun and verb selection from Arabic documents according to prepositions, as well as certain rules regarding other linguistic elements, such as the definite article “the.”
In their previous work on the second stage of BOC (Al-Smadi et al., 2019; Cambria & White, 2014; Menai, 2014), their models were employed to extract the semantic relations between Arabic words based on the stage of BOW. Al-Smadi et al. (2019) employed morphological, syntactic, and semantic processes as Arabic terms extraction and in their result they mentioned the worst result using semantic extraction. Another problem in terms extraction is that additional non-related words are extracted (Al-Smadi et al., 2019; Al-Zoghby et al., 2018; Menai, 2014); these extra words are termed as highly dimensional features and there is a need to reduce the number of features.
In contrast, using syntactic methods to extract terms can hide the core meaning that is the main meaning of the sentence. This leads to overlapping meanings among different terms such as “bank,” which has ten meanings: for example, a financial institution or sloped land. This overlap in meaning is the main problem of syntactic extraction. Semantic approach can overcome this weakness of syntactic extraction (Al-Zoghby et al., 2018; Elayeb, 2019; Salloum et al., 2018). El Mahdaouy et al. (2018) proposed a word embedding semantic extraction for IR that outperforms BOW. Benabdallah et al. (2017) proposed a method for ontology relation and complex term extraction. In their research a complex term consists of four words. The method was compared with BOW and their proposed method showed an improvement in recall and precision. However, the overall performance of the IR showed that BOW outperformed their method. Table 1 summarizes previous work on terms extraction.
Table 1
Previous works on extraction
| Author | Dataset used | Baseline extraction | Outperform extraction | Domain |
|---|---|---|---|---|
| Al-Shammari & Lin (2008) | Dataset manual | Khoja and Larkey stemmers | Noun with verbs for stemmer | Arabic clustering |
| Al-Salemi & Aziz (2011) | TREC-2002 | N-gram 3, 4, and 5 level | BOW | Arabic classifiers |
| Helwe & Elbassuoni (2019) | Arabic Wikipedia corpus | Name entity and their system | Name entity and their our system are equivalent | Arabic classification |
| El Mahdaouy et al. (2018) | Arabic TREC collection | BOW | Word embedding similarities | Information retrieval |
| Benabdallah et al. (2017) | Dataset manual | Ontology ‘synonym, antonym, hypernym’ and complex extraction | BOW | Marker learning algorithm |
To improve Arabic clustering performance with a reduced number of features and extracting a subset of the disambiguated terms with their relations with high accuracyis highly desirable. Hence, the next sections discuss the extraction of the core features (feature selection) and the clustering problem.
3.2. Unsupervised Feature Selection
Feature selection is a way to alleviate the curse of dimensionality. It reduces dimensionality by eliminating unnecessary and redundant features from the problem, which in turn improves the learning performance. Feature subset selection is a common problem in text clustering (Alweshah et al., 2021; Mafarja & Mirjalili, 2017) because of the high dimensionality of text in documents. Therefore, feature selection is necessary to reduce text dimensionality and to select a reasonable number of high quality features that affect performance. The development of new approaches to handle feature selection and the curse of dimensionality is still an active area of research, particularly for text clustering. The purpose of feature selection includes performance improvement such as accuracy, data visualization and simplification for model selection, and dimensionality reduction to remove noise and irrelevant features (Mafarja & Mirjalili, 2017).
The selection of the features and distribution of the data have a high impact on the performance of clustering algorithms (Abualigah et al., 2016) and text clustering processes such as extraction (Harrag, 2014). The latter tends to obtain local minima rather than the global minimum. The obtained results are often very good, especially when the initial features are fairly far apart. This is because the algorithm can usually distinguish the main category or class in a given data. Moreover, a clustering algorithm’s main process and the quality of extraction methods are both affected by the initial feature selection. Thus, the initial features can enhance the quality of the results (Mafarja & Mirjalili, 2017). For instance, failure of the clustering algorithm to recognize the features of the main category in certain data sets is possible if the features are close or similar. This failure can also occur particularly if the feature selection algorithm is left uncontrolled such as in the filter method (Zhang et al., 2019). The feature selection is split into two parts, filter and wrapper. The filter method ignores feature dependencies (Abualigah et al., 2016; Ahmad et al., 2021; Mafarja & Mirjalili, 2017; Zhang et al., 2019). The wrapper method using optimization as feature selection can introduce a good initial feature selection and leads to a better performance when refining the features and finding the optimal feature selection (Zhang et al., 2019). Table 2 shows the summary of previous work on unsupervised feature selection.
Table 2
Previous work on unsupervised feature selection
| Reference | Dataset used | Baseline algorithm | Outperform algorithm |
|---|---|---|---|
| Tabakhi et al. (2014) | UCI dataset | Laplacian score, Term variance, Random subspace method, Mutual correlation, and Relevance-redundancy feature selection | Ant colony optimization as an unsupervised feature selection |
| Abualigah et al. (2016) | Text dataset | Harmony Search, an unsupervised feature selection and without feature selection | Genetic algorithm an unsupervised feature selection |
| Zhang et al. (2019) | UCI datasets and text data | UFS, and ant colony optimization | Particle swarm optimization an unsupervised feature selection |
| Abualigah et al. (2016) | Text dataset | Genetic algorithm, and Harmony Search | Particle swarm optimization an unsupervised feature selection |
| Abualigah & Khader (2017) | Text dataset | Genetic algorithm, Harmony Search, particle swarm optimization | Hybrid particle swarm optimization an unsupervised feature selection |
However, only a few studies use optimization as unsupervised feature selection. Tabakhi et al. (2014) employed ant colony optimization as an unsupervised feature selection method for classifiers and used the absolute value (Bharti & Singh, 2014) as the similarity to optimize between features. The efficiency and effectiveness of the ant colony optimization was better than other feature selection methods used for English classifiers. Abualigah et al. (2016) employed a genetic algorithm for feature selection and used the mean absolute difference (MAD) (Bharti & Singh, 2014) as the similarity between features. They compared their proposed method with k-means clustering without feature selection and showed that their proposed method increases the performance of English text clustering. Subsequently, Zhang et al. (2019) have implemented particle swarm optimization unsupervised feature selection combined with filter approach; they compared the proposed approach with filter approach and the PSO. Their results mentioned that the particle swarm optimization with filter approach was better than others and reduced the number of features in English clustering. In contrast, employing the particle swarm optimisation (PSO) for feature selection by Abualigah et al. (2016) employed particle swarm optimization (PSO) for feature selection using MAD (Bharti & Singh, 2014). Their results showed that the proposed feature selection method outperforms other feature selection methods such as genetic and harmony search algorithms for English clustering. Finally, Abualigah and Khader (2017) employed a hybrid of a PSO algorithm and genetic algorithm for feature selection using MAD (Bharti & Singh, 2014). Their results showed that the proposed feature selection method outperforms PSO and other methods for English clustering. The main gap related to the previous work is the fitness function used, that is, the internal evaluation. The fitness function used by previous work does not have a relation between the internal evaluations metric, MAD, and the external evaluations metric, the F-measure. Theoretically the best score of the internal method should get the best score of the external method. However, in the experiments that we conducted and from the previous work, this does not happen.
The Arabic datasets used and BOW were applied as an extraction method using harmony search feature selection (HSFS) and then harmony search clustering (HSClust) to evaluate the F-measure. This was the first work that employed multi-objective optimization for two problems with the objective functions of MAD and best average distance of documents to the cluster centroid (ADDC), using HSClust with the best parameters from HSFS (Forsati et al., 2013) for Arabic clustering. The number of features are represented by the recommended algorithm in which all the features collection is codified in a vector of length m, where m represents the feature number, as demonstrated in Table 3. Every component of such vector is regarded as a label where the features are dropped or chosen. Table 3 shows the representation of features for three different solutions with their cost function of MAD. Solution 3 gave the highest score. In this example, twelve features {1, 2, 5, 9, and 11} are chosen while the others {3, 4, 6, 7, 8 10, 12} are dropped and so forth.
Table 3
Representation of features
| Solutions | Features (m) | MAD cost function | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| Solution 1 | 1/S | 1/S | 0/N | 0/N | 1/S | 0/N | 0/N | 0/N | 1/S | 0/N | 1/S | 0/N | 0.59 |
| Solution 2 | 0/N | 0/N | 1/S | 1/S | 0/N | 1/S | 1/S | 1/S | 0/N | 1/S | 1/S | 0/N | 0.55 |
| Solution 3 | 1/S | 1/S | 0/N | 1/S | 0/N | 0/N | 1/S | 0/N | 1/S | 1/S | 1/S | 0/N | 0.66 |
On the other hand, the Harmony Search (HS) as a cluster employs certain representations to code the document. All of the partition clusters, along with a vector of length n that denotes the number of documents, are presented in Table 4. For this vector, every element acts as the label that a single document belongs to. For instance, if the total number of clusters is represented by K, then each solution vector’s element gives an integer value that falls in the range of [K]={1,…, K}. In this example the cost function of ADDC was used. Four documents {2, 3, 8, and 10} originate from the cluster that has been assigned Label 1. The cluster assigned as Label 3 includes three documents {1, 7, 12} and the same goes for the other groups. The best score for ADDC cost function is the lowest value. The Pseudo code of harmony search as a feature selection is shown in Fig. 3 and the Pseudo code of harmony search as cluster is shown in Fig. 4.
Table 4
Representation of clusters as groups from 1 to 5
| Solutions | Documents (n) | ADDC cost function |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| Solution 1 | 3 | 1 | 1 | 4 | 5 | 2 | 3 | 1 | 4 | 1 | 4 | 3 | 0.11 |
| Solution 2 | 2 | 3 | 4 | 5 | 4 | 5 | 2 | 3 | 3 | 2 | 5 | 1 | 0.33 |
| Solution 3 | 1 | 3 | 2 | 3 | 3 | 4 | 1 | 2 | 1 | 4 | 3 | 2 | 0.29 |


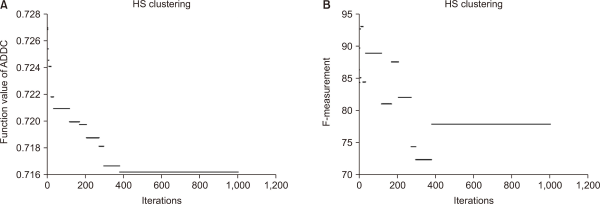
The Arabic dataset was taken from (Al-Salemi & Aziz, 2011); more details about the dataset are in Section 4.1. Fig. 5 shows the results of 1,000 iterations for HSFS: each iteration uses new feature selections and uses HSClust to evaluate the F-measure. Based on our experiment, the internal MAD cost function is used as a metric that is the best one, and has the highest value. However, it does not represent the highest F-measure value. For instance, at iteration 1 the MAD metric in HSFS was around 0.102 and the value of F-measure is around 0.84. In contrast, at iteration 560, the MAD metric in HSFS was around 0.167, which is better than at iteration 1, but the F-measure value was 0.56, which is worse. The same experiment was conducted for ADDC as shown in Fig. 6. The internal ADDC metric that is the best one and has the lowest value does not represent the highest F-measure value.
Fig. 5
Comparison of (A) MAD and (B) the F-measure using harmony search for feature selection and clustering. MAD, mean absolute difference.
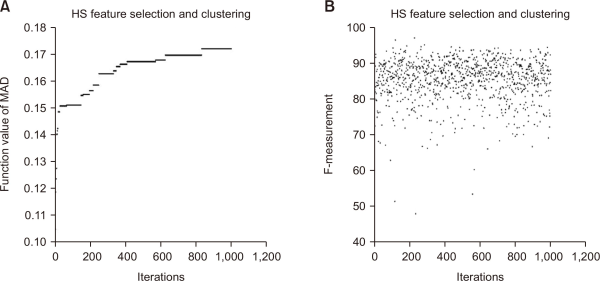
Fig. 6
Comparison of (A) ADDC and (B) the F-measure using harmony search for clustering. ADDC, average distance of documents to the cluster centroid.
3.3. Clustering Algorithms
The clustering process (Mehra et al., 2020) is comprised of grouping objects based on similarity. Such a method includes two essential kinds of clustering, namely, partitioning and hierarchical. The approaches of hierarchical clustering are believed to be better; nevertheless, at the start of the clustering process, they cannot usually recognize documents which are expected to be misclassified (Yahya, 2018). In addition, the complexity of time of hierarchical approaches is quadratic in terms of the number of objects of data (Wu et al., 2018). The approaches of partitioning clustering are better due to their fairly low computational complexity that enables them to deal with quite big datasets (Wu et al., 2018). The k-means approach has a crucial role in partitioning clustering (Bsoul et al., 2016), and it also has been utilized in partition-based clustering with linear time complexity (Wu et al., 2018). Furthermore, Hartigan (1981) stated that the essential aim of the k-means algorithm is that the documents mean assigned to such a cluster is used to symbolize each of the k clusters. Such a mean is named the cluster centroid. However, the k-means algorithm does not have sensitivity to the initialization and a priori clusters are needed. Moreover, the primary centroids play an essential role in the performance of clustering and might lead the algorithm to be stuck in a locally optimum solution (Selim & Ismail, 1984).
A number of researchers have conducted empirical research on the algorithms of clustering on different data sets while others have carried out research to identify the number of clusters or best clusters. One instance of identifying the best cluster is Dai et al. (2010a), which streamlined agglomerative hierarchical clustering by considering the significance of a document title. When the term existed in the title, it was assigned as a higher weight. The findings of their studies revealed that the proposed approach was efficient in clustering documents related to financial news. Nevertheless, some studies have investigated clustering themes. For instance, Bação et al. (2005) utilized self-organizing maps (SOMs) in order to cluster images “IRES,” for clustering data (as opposed to the clustering of text), and compared their approach with k-means. It was revealed that the SOM performance is better than that of k-means.
Other studies like Shahrivari and Jalili (2016) have made a comparison among complete single pass cluster, k-means, and others cluster algorithms in a data set. The findings of these studies revealed that k-means is more efficient than the other algorithms. Besides this, Bouras and Tsogkas (2010) utilized clustering approaches such as maximum, single, and centroid linkage hierarchical clustering, k-medians, regular k-means, and k-means++. The results of their study revealed that using k-means does not only produce the best results in terms of the internal metric of the clustering index function, but also provides better results on the experimentation of real users.
Other studies have also made a comparison among single-pass algorithms, k-means, and other algorithms for news topics clustering. For example, Jo (2009) found that k-means performed better than single-pass clustering. Besides this, Dai et al. (2010a) examined hybrid algorithms for clustering and presented a two-layer text clustering method which can detect the themes of retrospective news employing affinity propagation (AP) clustering. Furthermore, initial layer text clustering studies utilized AP clusters so as to produce the number of groups. Subsequently, they used common agglomerative hierarchical clustering to produce the final themes of news. Finally, such studies adopted classic k-means and usual agglomerative hierarchical clustering (AHC) as comparative approaches. The results showed that the proposed approach obtained the highest precision, followed by AP clustering, k-means clustering, and AHC, respectively. In terms of recall, it was revealed that the proposed approach as well as k-means achieved the highest results followed by the AHC as well as AP clustering approaches.
Velmurugan and Santhanan (2011) also made a comparison among three clustering algorithms on a geographic map data set. The findings of their study revealed that k-means was better with small data sets; k-medoids was better with huge data sets, and fuzzy c-means obtained qualitative results, which fell between those of k-means as well as k-medoids. Dueck and Frey (2007) also proposed AP clustering that could automatically produce many clusters. In fact, AP performs better than k-means in terms of precision, based on the findings of Dai et al. (2010a). However, an assessment of F-measure showed that k-means performs better than AP due to the fact that it has better recall. In addition, Qasim et al. (2013) made a comparison among four clusters utilizing 65 documents as a dataset. The findings of this study revealed that the best clustering approach is AP and then spectral, hierarchical, and ordinary k-means, respectively. Table 5 provides a summary of the studies on clustering.
Table 5
Previous work on cluster algorithms
| Reference | Dataset used | Baseline algorithm | Outperform algorithm |
|---|---|---|---|
| Dai et al. (2010a) | Financial news | AHC | Enhance AHC |
| Bação et al. (2005) | IRIS | k-means | SOM |
| Shahrivari & Jalili (2016) | KDD | Scalable, complete k-means | k-means |
| Bouras & Tsogkas (2010) | Web | Single, maximum, centroid AHC, and k-medians, k-means++ | k-means |
| Dueck & Frey (2007) | News | k-means, AHC, AP | APAHC |
| Velmurugan & Santhanan (2011) | Geographic map | Fuzzy c-means | k-means, k-medoids |
| Qasim et al. (2013) | 65 documents news | Spectral, Hierarchical and K-means | AP |
Furthermore, Silhouette Width (SW) (Alghamdi & Selamat, 2019; Campello & Hruschka, 2006) can be used to detect the numbers of clusters. A higher value of SW justifies better discrimination among clusters. Nevertheless, the biggest values of SW justify the best clustering (number of cluster). Numbers ranging between 2 and 10 are used to obtain the number of optimal cluster. When two clusters are recognized, the best SW value reached is 0.1710, but it is not helpful to discover the trend of two categories of crime because the number of clusters is insufficient to be analyzed. Thus, they utilized four clusters instead of two clusters.
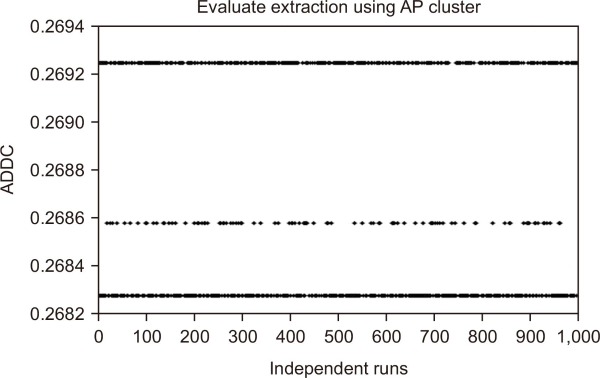
Qasim et al. (2013) used AP clustering method to generate an optimal number of clustering and grouped 65 documents as datasets. However, they did not compare SW and Bisecting k-means with other algorithms, and they did not used big datasets to show the performance of AP on bigger datasets than 65 documents. We did three experiments to address the problem related to three clustering algorithms, namely: Spherical k-means, AP, and k-means cluster. The results of experiments for Arabic clustering are shown in Figs. 7, 8, and 9 and it illustrated the problem of local optima. The results showed that 1,000 independent runs can produce either good or bad performance. The performance of the k-means algorithm is mainly affected by the specified clusters number as well as the random selection of primary cluster centers as revealed in the previous experiments. The means of Spherical k-means were worse than AP and k-means while AP outperform the Spherical k-means and k-mean as illustrated in Table 6. Nevertheless, it does not work on huge data as noticed in Fig. 10. Thus, the present study focuses on dealing with the latter issue by proposing efficient algorithms so as to generate results that are less reliant on the selected primary cluster centers, and thus are more stabilized. Most of the existing work utilized Harmony Search optimization as clustering. Such studies are mainly conducted for English. However, similar studies have not been conducted for Arabic.
Table 6
Experiment to compare between five cluster algorithms using internal evaluation
| Cluster algorithm | Best case | Worst case | Different |
|---|---|---|---|
| HSCLust | 0.7815 | 0.783 | 0.002 |
| HKM | 0.4 | 0.4 | 0 |
| K-means | 0.401 | 0.478 | 0.077 |
| SPK-means | 0.484 | 0.522 | 0.038 |
| AP | 0.26825 | 0.26925 | 0.001 |
Fig. 7
BOW extraction using k-means for 1,000 independent runs. BOW, Bag of Words; ADDC, average distance of documents to the cluster centroid.
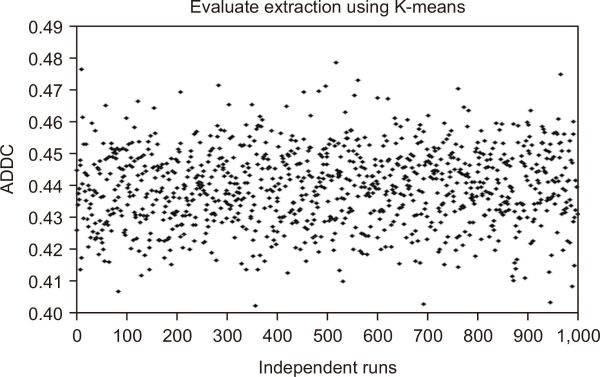
Fig. 8
BOW extraction using spherical k-means for 1,000 independent runs. BOW, Bag of Words; ADDC, average distance of documents to the cluster centroid.
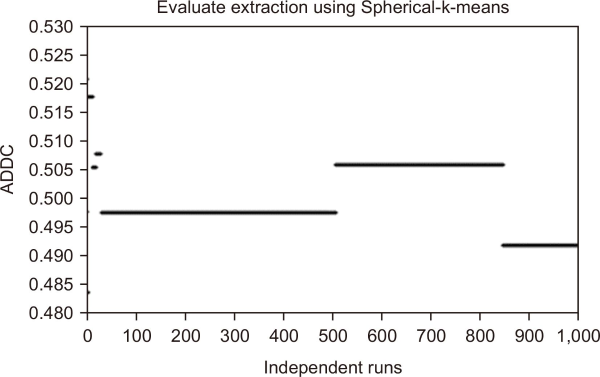
Fig. 9
BOW extraction using affinity propagation for 1,000 independent runs. BOW, Bag of Words; ADDC, average distance of documents to the cluster centroid.
The choice of the primary cluster centers as well as the data distribution has a great effect on k-means and other algorithms. Therefore, it could get stuck in local search rather than global search. The achieved results are usually very good in most cases, particularly when the centroids of initial centers cluster are sufficiently selected far apart, where it would be usually possible to differentiate the major clusters in a certain data set. Moreover, the essential processes of k-means apart from the final partition of the dataset quality are both influenced by the cluster centroids initialization. Therefore, the first points have a great role in the quality of results. For example, the failure of the k-means algorithm to recognize the main clusters features in a certain data set is possible if they are similar or close and particularly if the k-means algorithm is left unsupervised. In addition, to be less reliant on initialization of a certain dataset, and to improve the performance of k-means algorithm, it is important to incorporate the k-means algorithm with an optimization. This will allow better initial clustering centroids, improve the number of the clustering centroids refinement, and recognize the centers of optimal clustering (Gbadoubissa et al., 2020; Mehra et al., 2020).
Meta-heuristics optimization, is widely known to be effective. There are two types of popular meta-heuristics optimization, namely, single-solution based meta-heuristics, also known as trajectory methods, and population-solution based meta-heuristics. Single-solution based meta-heuristics start with a single initial solution and navigate the search space as a trajectory. The main trajectory methods include simulated annealing, Tabu search, the Greedy randomized adaptive search (GRASP) method, variable neighborhood search, guided local search, iterated local search, and their variants. In contrast, population-solution based meta-heuristics do not handle a single solution but rather a set of solutions that is a population. The most widespread population-based approaches are related to evolutionary computation and swarm intelligence (SI). Darwin’s theory of evolution provided the concepts needed for evolutionary computation algorithms, because it includes recombination and mutation operators, which allow a population of individuals to be modified by exploiting simple analogues of social interaction, rather than purely individual cognitive abilities. The main aim of SI is to create computational intelligence. The use of nature-inspired meta-heuristic algorithms has been widely adopted in several domains, including computer science (Kushwaha & Pant, 2021), data mining (Grislin-Le Strugeon et al., 2021), texture (Paci et al., 2013), agriculture (Cisty, 2010), computer vision (Connolly et al., 2012), forecasting (Kaur & Sood, 2020), medicine and biology (Arle & Carlson, 2021), scheduling (Guo et al., 2009), economy (Zheng et al., 2020), and engineering (Sayed et al., 2018).
Through the literature it was found that existing clustering algorithms are still inadequate for the Quran themes clustering. Mainly, this is due to the Arabic clustering. In text clustering, similarity measures for documents are utilized and many terms, or features, are specified for each document. In contrast, distance measures between points in a space are used by data mining. The dissimilarity between text mining and data mining has also been mentioned by Hearst (1999). Note that data mining uses non-textual data as opposed to text mining, which utilizes textual data (Guo et al., 2009). However, a few works involve optimization as clustering. Mahdavi and Abolhassani (2009) employed harmony search as an English clustering technique and merged it with k-means on diverse datasets. They found the best ADDC measure to be harmony k-means, when compared with harmony search clustering, k-means, genetic k-means, the Mises-Fisher generative model-based algorithm, and PSO clustering. Forsati et al. (2013) generated three versions of harmony search with k-means and evaluated 13 scenarios to choose the best parameters related to harmony search for English clustering. The best proposed method was related to the combination of k-means with harmony search as cluster. Other works used other type of meta-heuristics. Cagnina et al. (2014) employed Practical Swarm Optimization as English clustering method on short text datasets and compared it with k-majorClust, CLUDIPSO, k-means, and CHAMELEON as a local search clustering. The best algorithm was an improved version of PSO.
In general, existing methods are summarized in Table 1 for the extraction of Arabic clustering and Table 6 for English text clustering, respectively. The limitations are as follows:
-
(1) Syntactic extraction is not adequate for extracting information from Quran themes. Semantic meanings are useful for Quran themes. As an example: Extracting nouns and verbs with their semantic meanings, where events have nouns to describe locations, names, themes, dates, and events also have verbs to describe themes, types, and reasons while simultaneously avoiding the extraction of unimportant features (Atwan et al., 2014).
-
(2) k-means can be the best clustering algorithm (Jain, 2010). However, in the case of Quran themes, it is not sufficient. k-means with a hybrid method with harmony search or spherical k-means could be considered. Furthermore, other researchers have provided a solution by integrating with other algorithms such as SW (Alghamdi & Selamat, 2019; Campello & Hruschka, 2006) to determine the number of clusters. However, their findings for SW (Alghamdi & Selamat, 2019; Campello & Hruschka, 2006) and integrated algorithms (Dai et al., 2010b) showed that their approach can be further improved in determining the correct number of clusters.
-
(3) Internal evaluations of ADDC for clustering and internal evaluation of MAD for unsupervised feature selection are acceptable to measure optimal centroids and optimal features. However, our experiments in Sections 3.2 and 3.3 showed that the F-measure of this internal evaluation needs to be increased for Arabic text clustering. This can be seen in the experiments shown in Fig. 5 and Fig. 6.
-
(4) All the clustering-based works solved the challenges of clustering documents by enhancing part of the process, where the output of each stage affects the accuracy of the next stage (Atwan et al., 2014). Section 4.2 shows the disadvantages of k-means clustering where it can affect the evaluation of the extraction methods. In our study this is discovered in Arabic clustering. Therefore, there is a need to evaluate the extraction methods using optimization algorithms that are less dependent on initial centroids. However, existing works do not used optimization-based clustering for Arabic text clustering to evaluate Arabic text extraction. The focus of our research is on the Arabic optimization clustering and optimization as feature selection for Arabic clustering. This is similar to work that has been done in English optimization clustering and optimization as a feature selection for English clustering.
-
(5) In addition, previous approaches do not employ multi-objective optimization as feature selection and as clustering using the same algorithm. In other words, it is necessary to employ an optimization method to simultaneously solve two problems: feature selection and clustering.
As stated before, there are three processes involved in Arabic clustering, from the low-level process of clustering up to the high-level process of extracting terms from the Quran themes. As demonstrated in our experiments in Section 4.2, we managed to identify the weakness of extracting information from the Quran themes when addressing the problem of the k-means clustering algorithm. In addition, it is very important to extract words such as nouns and verbs with their semantic meaning related to the themes within the Quran, whereby themes or types in the Quran have nouns to describe information such as names, themes, dates, and locations, while verbs can be used to describe information such as themes, types, and reasons.
Based on the limitations discussed, we can conclude that existing methods for detecting and identifying Arabic text clusters have weaknesses, either with respect to the method of extraction, unsupervised feature selection, and clustering algorithm, or the method of internal evaluation. These are such as ADDC for clustering and MAD for unsupervised feature selection. The problems are related to clustering algorithms and the need to verify the effectiveness of a clustering algorithm by evaluating the extraction process. Therefore, results of previous methods should often be suboptimal (Aouf et al., 2008) and the problem is related to extracting the most important terms for Quran themes (El Mahdaouy et al., 2018). In addition, experiments on Arabic clustering need to be conducted to show the effect of optimization methods such as harmony search on extraction method performance for both Arabic as well as English.
In this study, all the weaknesses mentioned are shown through experiments in the next section; furthermore, we propose solutions to assist the detection and identification of the groups of themes of the Quran using Arabic text optimization for feature selection and clustering.
4. PROPOSED QURAN THEME CLUSTERING APPROACH
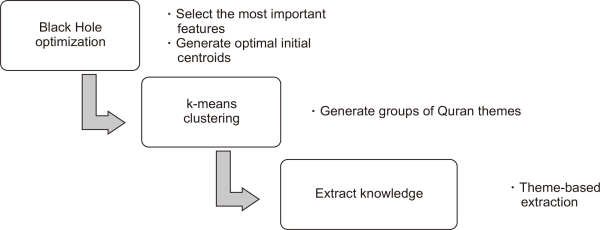
This section consists of three subsections, each containing a future direction to be employed for Quran theme clustering. The first section suggests the establishment of new real-text Dataset. The dataset for this study were taken from Al-Salemi and Aziz (2011). The second section recommends extracting the most important terms, as discussed in Sections 2 and 3.1, with respect to the semantic meaning of nouns and verbs. Section 4.2 describes the selection of the most important features using the black hole (BH) method. In addition, we use the BH method to cluster the data to assign the optimal initial centroids for Quran themes. Using this concept, we propose multi-objective optimization for text clustering, especially for Arabic text clustering.
4.1. Data Collection and Performance Measure
In the conduced experiments, unedited, modern, and unmarked Arabic text was utilized, consisting of a sample of almost 1,680 documents gathered from a number of Arabic online resources. The initial dataset is comprised of four categories, namely, economics, art, sport, and politics articles. Each includes documents collected from Al-Salemi and Aziz (2011). Table 7 provides a summary of the dataset along with features number of every category, as well as the total of 13,464 words. However, the second dataset includes a set specifically designed to assess the extraction of Arabic text for three domains, namely, Arabic classifiers, Arabic clustering, and Arabic IR created as part of TREC 2001. The set has 383,872 Arabic documents, mostly newswire dispatches issued by Agence France Press between the years 1994 and 2000. Ground truth and standard TREC queries have been created for such collection: 25 queries were considered as part of TREC 2001, and the collection of queries has matching relevance judgments produced utilizing the technique of pooling. Based on this, part of TREC 2001 is defined for classifiers and clustering as revealed in Table 8, which include ten classes along with the number of words (a total of 19,508 words) as well as the number of related documents.
Table 7
Details of dataset for cluster and classifier domains taken from Al-Salemi and Aziz (2011)
| Categories | # DOCUMENTS | # features |
|---|---|---|
| Art | 420 | 2,951 |
| Economics | 420 | 3,859 |
| Politics | 420 | 3,172 |
| Sport | 420 | 3,482 |
Table 8
Description of document dataset categories taken from TREC 2001
| Classes | # documents | # features |
|---|---|---|
| 1 | 383 | 1,457 |
| 2 | 315 | 2,013 |
| 3 | 246 | 1,277 |
| 4 | 222 | 2,607 |
| 5 | 174 | 1,402 |
| 6 | 179 | 1,683 |
| 7 | 393 | 2,733 |
| 8 | 321 | 2,169 |
| 9 | 242 | 1,086 |
| 10 | 556 | 3,081 |
4.2. Proposed Term Extraction Method
As mentioned in Section 3.1 regarding the weakness of extraction methods, we suggest using Word-Net for noun and verb extraction to extract information that provides the most important features for describing specific Quran themes and their semantic meaning. This can be done by identifying whether a term could be a verb or noun by examination of the stemmed feature that exists in the Arabic Word-Net verb or noun database, as shown in Fig. 11. Quran themes could be identified and detected by looking at nouns as well as verbs along with their semantic meaning. In addition, the redundant terms extracted as nouns and verbs would be removed. In contrast, the problems related to the clusters used to evaluate the extraction methods, as mentioned before, lead us to verify this new problem experimentally.

As noted before, Table 1 shows a summary of the research for extractions. The main gap in this process is the evaluation, which uses clustering search that depends on the initial cluster centroids of each cluster’s group. Previous researchers have used independent runs of Arabic text clustering and then taken the average; however, that is not sufficient. In fact, they did not consider the effect of clustering algorithms on extraction to make the comparisons impartial and fair to prove this. BOW has been applied as extraction method using spherical k-means, AP, and k-means. To evaluate the four clusters, we used ADDC as the evaluation metric. Figs. 7, 8, and 9 show the results of 1,000 runs for spherical k-means, AP and k-means, and clustering, which have different results, either positive or negative. Good results are close to zero and this happened to all of them. However, the results of k-means showed that k-means are very dependent on initial cluster centroids. The dependency is less with spherical k-means and followed by AP. It can be seen that the worst result of k-means was close to the best result of spherical k-means. Moreover, AP’s results were better than the others, but on pairs of dataset there were “two classes of the dataset.” However, on big dataset, this is not possible. The AP method needs an impractically large memory to normalize the dataset, and this experiment is shown in Fig. 10.
4.3. Black Hole Optimization as Unsupervised Feature Selection and Clustering Method
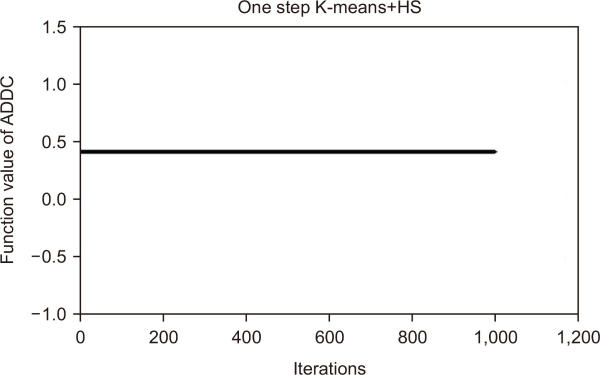
In the last two decades, many meta-heuristic methods have been used for data mining, including simulated annealing (Güngör & Ünler, 2007), Tabu search (Kharrousheh et al., 2011), genetic algorithms (Liu et al., 2012), ant colony optimization (Niknam & Amiri, 2010), the neural gas algorithm (Qin & Suganthan, 2004), honey bee mating optimization (Fathian et al., 2007), differential evolution (Das et al., 2007), PSO (Izakian & Abraham, 2011), artificial bee colony optimization (Karaboga & Ozturk, 2011), gravitational search (Hatamlou et al., 2012), binary search (Hatamlou, 2012), firefly optimization (Senthilnath et al., 2011), big bang–big crunch (Hatamlou et al., 2011), harmony search k-means (Forsati et al., 2013), and BH optimization (Hatamlou, 2013). However, in this study we conducted an experiment to show the weaknesses of harmony search with k-means proposed for English clustering by Forsati et al. (2013). We used the best parameter settings obtained by Forsati et al. (2013), and the pseudo code of harmony search as a cluster with k-means shown in Figs. 3, 4, and 12. Comparisons of the results of harmony search clustering (Fig. 13) and one-step k-means (harmony k-means) are shown in Fig. 14, where the combined method was better than harmony search clustering. This can be seen in both Fig. 13 and Fig. 14. However, results shown in Figs. 7, 8, 9, and 13 showed that k-means clustering at times can produce better results than harmony k-means. Therefore, another optimization method can be proposed to overcome this weakness.

Fig. 13
Harmony search for 1,000 iterations using BOW extraction. BOW, Bag of Words; ADDC, average distance of documents to the cluster centroid.
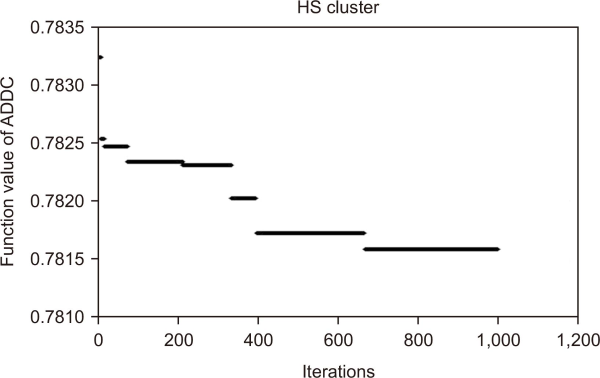
Fig. 14
One step k-means+harmony search for 1,000 iterations using BOW extraction. BOW, Bag of Words; ADDC, average distance of documents to the cluster centroid.
To address the weakness of harmony search, we suggest employing BH optimization as a cluster (Hatamlou, 2013) for Quran themes clustering. Owing to its few common features with other population-based methods, the BH optimization algorithm is in fact a population-based method. A population of candidate solutions to a given problem is generated and placed randomly within the search space, as in other population-based algorithms that utilize certain mechanisms to gradually improve the population to obtain the optimal solution. In genetic algorithms, for instance, mutation and crossover operations help to achieve gradual improvements. By moving the candidate solutions around in the search space, this progress can be achieved in PSO using the best locations found so far, which are updated when the candidates reach better locations. However, by shifting all the candidates towards the best candidate at each iteration, namely, as in BH, and considering newly generated candidates in the search space instead of those candidates included within the current set of the BH, the population in the BH algorithm can grow. First, to solve the BH problem, researchers tend to utilize benchmark functions (Zhang et al., 2008). However, a new mechanism, known as the BH, has been introduced into PSO because of the method suggested in Zhang et al. (2008). A new particle is created randomly near the best particle at each iteration in this method. After this, the algorithm updates the locations of the particles either using PSO or a new mechanism that is mainly based on two randomly created numbers. To summarize, PSO has paved the way for this method. BH is a new particle used to augment the convergence speed of the PSO and limit the convergence to local optima. Moreover, a BH can attract other particles under certain conditions. The theme horizon of the BH and the destruction of stars (candidates) has not been tackled in this approach, but such optimization has been treated in Hatamlou (2013). The best candidate at each iteration in the BH algorithm is considered to be a BH; however, all the remaining candidates are considered to be normal stars. A BH is not randomly created; it is created by one of the real candidates of the population. After this, depending on their current location and a random number, all the candidates are shifted towards the BH. The suggested BH algorithm is beneficial mainly because of its simple structure and easy implementation. Moreover, it is free from parameter tuning issues (Hatamlou, 2013).
The main notion of utilizing the BH for feature selection is basically to generate an area of space features which have a big amount of concentrated mass. Thus, the potential of a nearby object feature escaping its gravitational pull for significant features is reduced. Therefore, it is believed that anything falls into a BH, among them light, which is eternally gone from the universe. The recommended BH algorithm begins with employing a primary population of candidate solutions to an objective function which is estimated for them as well as to an optimization problem. Therefore, the best candidate is selected in each iteration as the BH whereas the others comprise the normal features or normal stars. Subsequently, the process of initialization is complete, and the BH begins with pulling the stars around its feature. If the resemblance between the BH centroid and star (feature) is high, it will be swallowed by the significant features of BH and is gone everlastingly. In this case, a fresh star (candidate solution) is created randomly and put in the search space, followed by a new search. The steps involved are as follows:
-
Loop based on the number of BHs that will be assigned.
-
For each star “feature,” evaluate the objective function for each BH using MAD.
-
Select the best stars “features” that have the best fitness value as the BH important features for all BHs.
-
Change the location of each star “features” according to xi(t+1)=xi(t)+rand×(xBH–xi(t)) ... i=1, 2, 3, ..., N
-
If a star “feature” reaches a location with higher similarity than the BH, exchange their locations.
-
If a star “feature” crosses the theme horizon of the BH, replace it with a new star “feature” in a random location in the search space.
-
When a termination criterion (a maximum number of iterations or a sufficiently good fitness) is met, exit the loop.
In the above equation, xi(t) and xi(t+1) are the i-th star of the locations at iterations t and t+1, respectively. In addition, xBH is the location of the BH in the search space. Variable Rand is a random number in the interval [0, 1], and N is the number of stars (candidate solutions).
BH has been proposed as feature selection and currently we are introducing BH as clustering. The BH as cluster started with a fresh star (candidate solution). The candidate solution is created randomly and put in the search space, followed by a new search. The steps involved are as follows:
-
Loop based on the number of BHs that will be assigned.
-
For each star “number of group,” evaluate the objective function for each BH using ADDC.
-
Select the best stars “number of group” that have the best fitness value as the BH of each documents/versus belongto theme/group for all BHs.
-
Change the location of each star “number of group” according to xi(t+1)=xi(t)+rand×(xBH–xi(t)) ... i=1, 2, 3, ..., Number of groups
-
If a star “number of group” reaches a location with higher similarity than the BH, exchange their locations.
-
If a star “number of group” crosses the theme horizon of the BH, replace it with a new star “number of group” in a random location in the search space.
-
When a termination criterion (a maximum number of iterations or a sufficiently good fitness) is met, exit the loop.
Fig. 15 shows the proposed method using BH as feature selection, which is then followed by employing BH as a cluster for Quran themes clustering. The possibility of a nearby object that is the Quran theme document escaping its gravitational pull (i.e., that of the clusters) is minimized. The proposed BH with the combination of k-means are shown in Fig. 16. The proposed BH as a feature selection reduced the unimportant features and the proposed BH as a cluster will select the optimal initial centroid of each theme.

5. CONCLUSION
The ultimate aim of this paper was to employ Arabic text clustering to cluster Quran themes into clusters. Hence, this study reviewed the necessary improvements to Arabic text clustering, and suggested possible research directions for improving Arabic text clustering with respect to extraction, feature selection, and clustering. In this review paper, the limitations related to Arabic text clustering were discussed and the limitations of existing works were demonstrated and presented through our experiments. For instance, the k-means algorithm finds the best clusters compared to other algorithms as shown in Figs. 7, 8, 9, and 10. But the k-means weakness is in the initial centroids. Therefore, we proposed to use BH as a cluster to create the optimal Initial centroids. Next, we examined the weakness of term extraction methods and conducted a number of experiments to demonstrate the problems identified in existing approaches. For this problem we suggested using nouns and verbs with their semantic meaning as a new extraction method for Quran theme clustering. This can provide better performance compared to the current approach.
We identified a new problem related to extraction depending on the clustering algorithm used, and for that we suggest the use of BH as feature selection and as clustering to evaluate the proposed extraction. We also noted the limitations of using AP clustering on a big dataset, and our suggestion is to use BH as feature selection. For the dataset we have generated and published real Quran theme dataset and Arabic text dataset, which are freely available online.1
REFERENCES
, , , , , , , (2008, June 30-July 2) Proceedings of the 2008 International Conference on Service Systems and Service Managament Institute of Electrical and Electronics Engineers Review of data mining clustering techniques to analyze data with high dimensionality as applied in gene expression data, 1-5,
, , (2016) Document clustering approach to detect crime World Applied Sciences Journal, 34(8), 1026-1036 https://doi.org/10.5829/idosi.wasj.2016.34.8.109.
, , (2018) Improving Arabic information retrieval using word embedding similarities International Journal of Speech Technology, 21(1), 121-136 https://hal.archives-ouvertes.fr/hal-01706531.
, , (2020) Survey of automatic query expansion for Arabic text retrieval Journal of Information Science Theory and Practice, 8(4), 67-86 https://doi.org/10.1633/JISTaP.2020.8.4.6.
, , , (2016) A systematic review analysis for Quran verses retrieval Journal of Engineering and Applied Sciences, 11(3), 629-634 https://doi.org/10.36478/jeasci.2016.629.634.
- Submission Date
- 2021-05-04
- Revised Date
- 2021-09-22
- Accepted Date
- 2021-10-10
- 457Downloaded
- 1,414Viewed
- 0KCI Citations
- 0WOS Citations