- Apply for Authority
- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

Point of Interest Recommendation System Using Sentiment Analysis

Ajay Indian (Department of Computer Science, Central University of Rajasthan, Ajmer, India)
Krishna Kumar Mohbey (Department of Computer Science, Central University of Rajasthan, Ajmer, India)
Kunal Jangid (Department of Computer Science, Central University of Rajasthan, Ajmer, India)

Abstract
Sentiment analysis is one of the promising approaches for developing a point of interest (POI) recommendation system. It uses natural language processing techniques that deploy expert insights from user-generated content such as reviews and feedback. By applying sentiment polarities (positive, negative, or neutral) associated with each POI, the recommendation system can suggest the most suitable POIs for specific users. The proposed study combines two models for POI recommendation. The first model uses bidirectional long short-term memory (BiLSTM) to predict sentiments and is trained on an election dataset. It is observed that the proposed model outperforms existing models in terms of accuracy (99.52%), precision (99.53%), recall (99.51%), and F1-score (99.52%). Then, this model is used on the Foursquare dataset to predict the class labels. Following this, user and POI embeddings are generated. The next model recommends the top POIs and corresponding coordinates to the user using the LSTM model. Filtered user interest and locations are used to recommend POIs from the Foursquare dataset. The results of our proposed model for the POI recommendation system using sentiment analysis are compared to several state-of-the-art approaches and are found quite affirmative regarding recall (48.5%) and precision (85%). The proposed system can be used for trip advice, group recommendations, and interesting place recommendations to specific users.
- keywords
- recommendation system, point of interest, sentiment analysis, neural networks, BiLSTM
1. INTRODUCTION
Individualized suggestions for goods, services, and locations are provided by recommendation systems, which have become an indispensable part of our day-to-day lives. These suggestions are derived from our preferences and actions. One such system is a point of interest (POI) recommendation system, which recommends popular and relevant places based on user interests and location (Acharya et al., 2024). The POI recommendation system using sentiment analysis (SA) has potential applications in various domains, including tourism, hospitality, and marketing. By providing personalized recommendations for the user and emotional preferences, the recommendation system can enhance user engagement, increasing user loyalty and revenue for the business using SA. In conclusion, POI recommendation analysis is a promising approach to providing users with tailored and enhanced travel experiences (Xu et al., 2019). One approach to improving the accuracy of POI recommendation systems is through a method for determining the emotional tone of a passage of text, known as SA. SA can be applied in the context of POI recommendation systems to analyze the sentiments indicated in user reviews of various places like restaurants, hotels, tourist attractions, and more. By using SA, the system can gain insights into the overall satisfaction of users with a particular place and make better recommendations to users based on their preferences. Integration of SA into POI recommendation systems is being done to provide consumers with suggestions that are more accurate and more tailored to their specific needs. By analyzing the sentiments expressed in user reviews, the system can identify highly recommended users and recommend them to users with similar preferences. It can increase user satisfaction and engagement with the recommendation system. In addition, using SA for POI recommendation systems can help businesses improve their products and services based on user feedback. Utilizing user SA, businesses can identify areas for improvement and make adjustments to their products and services to better meet the requirements and expectations of their clientele. According to Mishra et al. (2020), using SA in POI recommendation systems can enhance the accuracy of suggestions, boost user happiness, and offer meaningful feedback to different enterprises.
This study aims to develop a recommendation system for POIs that considers the sentiment of user reviews. The challenge is to provide accurate and relevant recommendations despite the large number of POIs available and the diverse interests of users. To handle this challenge is our research problem, and so this study proposes using SA to determine the sentiment of user reviews about a particular POI to address this challenge. The proposed system will recommend POIs that have positive, negative, or neutral sentiments based on user reviews. The proposed solution uses a bidirectional long short-term memory (BiLSTM) model for SA and an LSTM model for POI recommendation. The proposed POI recommendation system will take input such as the user’s ID, location, and interests, and recommend POIs within a radius of 5 km from the user’s location that matches the user’s interests and has a positive or neutral sentiment. The goal is to develop a personalized POI recommendation system that incorporates the sentiment of user reviews. Based on user choices and reviews, the POI recommendation system employs SA to give POIs tailored to their specific needs. The study aims to contribute the following objectives:
-
Enhance User Experience: Through the provision of more tailored suggestions that are derived from the user’s preferences and the SA of their evaluations, the model that has been developed intends to enhance the user experience significantly. It will make it easier for users to find the most suitable POIs.
-
Increase User Engagement: By providing personalized recommendations, the proposed model aims to increase user engagement and encourage users to use the system more frequently.
-
Improve POI Selection: The proposed model aims to improve the selection of POIs by considering the users’ preferences and analyzing their reviews’ sentiments. It will help users find the most suitable POIs that match their interests and preferences.
-
Increase User Satisfaction: The proposed model aims to increase user satisfaction by providing personalized recommendations that match their preferences and interests. This will make users more likely to recommend the system to others.
-
Improve Business Outcomes: The proposed model aims to improve business outcomes by increasing user engagement and satisfaction, which can lead to increased revenue and customer loyalty for businesses the system recommends.
The proposed study is subsequently organized into five sections. Specific significant studies on SA and POI recommendation systems are reviewed in Section 2. Section 3 explains the proposed approach, covering a summary of the datasets utilized in the study, the proposed SA model, and the POI recommendation model using SA. In Section 4, the results of the suggested models are discussed. Finally, Section 5 concludes the present study by discussing findings and giving some future scope of study.
2. LITERATURE REVIEW
A good recommendation system should have as its primary objective the provision of consumers with a collection of suggested destinations that are a great match for their preferences. People who use location-based social networks (LBSN), often known as LBSNs, might benefit from user recommendations of their favorite local attractions, such as shopping centers and restaurants (Zhang & Chow, 2015). Users can post their positions and share their ideas on interesting regions to visit via LBSNs. The conclusions drawn from these discussions may then be applied to making suggestions to other users. According to Yu et al. (2019), the objective of a recommendation system is to provide consumers with a list of locations and items most closely aligned with their preferences.
According to Ding and Chen (2018), local business social networks are online communities where members can search for particular areas of interest and broadcast their geographical whereabouts through check-ins. LBSNs like Foursquare and Yelp attract attention since they allow finding new locations to add to favorites lists. Therefore, individualized suggestions for POI recommendation are important. It is possible to model people’s unique choices using the wealth of user and POI data found, including check-in data, POI locations, and classifications. The algorithmic procedure for recommending POIs has been through a relatively protracted development period. It starts with collaborative filtering methods and tensor decomposition algorithms and then moves on to using deep learning algorithms to mine the geographical preferences of users. Because of the inherent graph structure of POI data, the development of graph neural networks has led to a change in the focus of a substantial amount of research toward applying graph neural network algorithms for POI recommendations (Ma et al., 2018). Liu et al. (2018) proposed a modified Feature-Scaled Unifying Algorithm system to obtain important POIs from temporal features using non-negative matrix factorization. The results suggested the importance of time in physical space.
An Adversarial Point-of-Interest Recommendation (APOIR) model for examining the distribution of latent user preference for POI recommendation is proposed by Zhou et al. (2019); the recommender (R) and the discriminator (D) are the two main components of APOIR. By maximizing the likelihood that these POIs are expected to be unvisited and possibly fascinating, the recommender makes recommendations based on the distribution learned. The discriminator is responsible for distinguishing between recommended and actual check-ins and providing gradients to provide direction for improving R within a rewarding framework. The two components are co-trained using the same method by playing a minimax game, in which one of the components wants to develop while pushing the other to the maximum. APOIR incorporates geographical and social relationships between POIs into the reward function and optimizes R through reinforcement learning. Compared to state-of-the-art approaches, the suggested strategy achieves considerable performance improvements in four standard criteria. Zhou et al. (2019) contribute to a better understanding of the critical user check-in behavior in POI recommendations. They introduce a novel method for productively learning latent user preferences.
Wang et al. (2019) proposed mine trust-based POIs using modified collaborative filtering — the model of a fusion of temporal and spatial features based on the user’s physical space. Most POI location recommendations made by recent studies employ conventional collaborative filtering recommendation techniques. For instance, a 3-layer network framework POI recommendation approach using LBSN was proposed (Zhang et al., 2019). Additional tags, social and geographic data, and other data are modeled individually and incorporated into a matrix factorization framework. Although this technique is more accurate than previous methods, the performance of recommendations as a whole still needs to be enhanced. According to Yu et al. (2019), a POI recommendation system supported by the semantics of the user’s contextual behavior is proposed.
A continuous POI recommendation approach utilizing latent variables with recurrent neural network was proposed by Lu et al. (2019). Recommending POIs combines the preferences of users and sequential access to POIs. There is still scope for enhancement of the extraction of prospective knowledge despite the method’s better precision than continuous POI. Zhao et al. (2021) proposed mine sentiment-based POIs from the users’ rated data. The approach showed enhanced results. Sun et al. (2020) proposed the long- and short-term preference modeling model to extract users’ long- and short-term preferences for personalized POI recommendations. Dang et al. (2020) presented a detailed study on the SA models using various algorithms like deep neural networks, convolutional neural network, recurrent neural network, term frequency-inverse document frequency or word embedding on the series of datasets. Dai et al. (2019) introduced a new neural network approach to context-aware citation recommendations by combining stacked denoising autoencoders and BiLSTM.
The use of SA in POI recommender systems was examined by Mishra et al. (2020). They pointed out that with the rise of the tourism sector and the Internet, data is available about various POI locations, making it difficult for users to make informed selections. The authors proposed a model that uses review data to select POIs that fit their interests. They use the Sentiment Intensity Analyzer to calculate the mean value of sentiment weightage in the reviews and suggest top places based on the score. User preferences were derived through semantic clustering and the SA of their comments and reviews (Abbasi-Moud et al., 2021). The features of tourist attractions were extracted. The proposed recommendation system was based on contextual information such as weather, time, location, user preferences, and the similarity of tourist preferences to nearby attraction elements.
A deep learning-based POI recommendation strategy in LBSNs is also proposed (Liu & Wu, 2021) to address the challenges of data sparsity and a lack of negative samples that affect many POI recommendation systems. A BiLSTM attention mechanism assigns weights to different parts of the current sequence following the user’s long-term and short-term preferences. Using the user’s past and the current POI sign-in sequence, the suggested method records the whole sequence.
The encoder data is then given into the BiLSTM-Attention algorithm, representing the current POI sign-in sequence based on attention. The decoder then goes over it to provide a Top-N recommendation list. Previous approaches illustrated in Sachin et al. (2020), Murthy et al. (2020), Aman et al. (2020), and Das et al. (2021) have used SA in different perspectives for mining content from text. Dang et al. (2021) proposed an integrated SA and recommender system combination. The results were quite efficient. As explained, SA has varied applications in online advertising (Zhao et al., 2021). Naresh and Krishna (2021) deployed machine learning models for SA, demonstrating the potential of machine learning models.
An LSTM-LSA-based model was presented by Wang et al. (2023) to create a more secure recommendation system for POIs, with privacy serving as the determining criterion. The Stan model, defined by Luo et al. (2021), proposed a POI recommendation model based on a self-attention layer from mining spatiotemporal features-based POIs. It is a key feature for travelers to be able to visit, in the order of their preferred destinations, beginning from the network site, which provides them with advantages such as access to shopping malls and restaurants, among other options. Several factors determine the collection of locations and the choice of those locations, the most important of which are the orders given by consumers to locations, the distance between them, and the total amount of time spent on the trip. A prototype is developed for a system that may be used to fulfill consumers’ visitation requirements and can deliver packages in sequences determined by their locations (Mohbey et al., 2021).
In order to mine user-interested POIs, Hossain et al. (2022) presented the context-aware recency-based attention network model, which used contextual information. In order to examine the connections between social media and its impact on community-based tourism, Khruahong et al. (2022) suggested a BiLSTM model incorporating a Social Media Sensing framework as SA. Effectively illustrating nonlinear and linear relationships between the user and the object is the strength of deep learning (El Alaoui et al., 2022). Data sources like images and texts are mined for their underlying relationships, which are extracted. Learning and training are predicated on refining a process to reduce reconstruction error. Deep learning can take data from any source and transmit it to the output using categorization. This exemplifies deep learning’s primary benefit. Alemayehu et al. (2023) proposed a SA system for the Amharic language.
Based on the literature review, it is clear that the POI suggestion system could use some work because the current systems are not very good at recalling points and being accurate. It is also evident from the review that this improvement can be achieved using SA to develop the POI recommendation model.
3. POI RECOMMENDATION SYSTEM USING SA
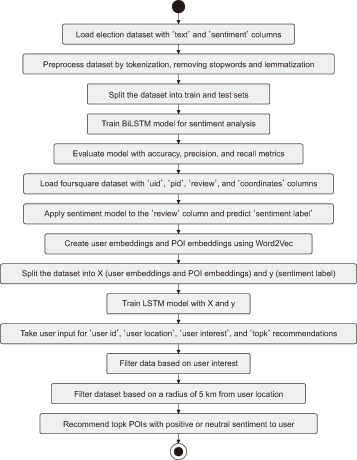
The proposed model aims to address the limitations of the existing models by incorporating SA to provide more personalized and relevant recommendations. Fig. 1 depicts the detailed procedures involved in the proposed POI recommendation model, such as data loading, preprocessing, model training, and user input processing, which leads to the final recommendations. Overall, the proposed model can improve the user experience by providing tailored recommendations, which are more likely to be of interest to the user.
Fig. 1
Procedure involved in proposed POI recommendation system using sentiment analysis. POI, point of interest; BiLSTM, bidirectional long short-term memory.
3.1. Dataset and Data Preprocessing
Two datasets are used in the proposed POI recommendation system using SA: the election dataset for SA and the Foursquare dataset for POI recommendation.
3.1.1. Election Dataset
The election dataset is a labeled dataset that contains a collection of tweets related to General Elections Held in India – 2019.1 The dataset was obtained from Kaggle, and the dataset has two columns: ‘text’ and ‘sentiment,’ and 162,980 rows. The ‘text’ column includes the tweet text, while the ‘sentiment’ column indicates the sentiment polarity of the tweet. The sentiment polarity can be either positive, negative, or neutral. The election dataset is used for training and testing the SA model.
3.1.2. Foursquare Dataset
The Foursquare dataset includes user reviews of different POIs, such as restaurants, cafes, and museums. The dataset was obtained from Git Hub and collected from the Foursquare API. The dataset contains four columns: ‘uid,’ ‘pid,’ ‘review,’ and ‘coordinates.’ The ‘uid’ column represents the user ID who wrote the review; the ‘pid’ column represents the POI ID; the ‘review’ column includes the text of the user review of the ‘pid’; and the ‘coordinates’ column includes the latitude and longitude coordinates of the POI.
The SA model trained on the election dataset is applied to the ‘review’ column to predict the sentiment of each review, and a new column, ‘score,’ is added to the dataset to represent the predicted sentiment. Table 1 shows the unique numbers of users, POIs, check-ins, and reviews of the Foursquare dataset.
Table 1
Foursquare dataset info
| Column | Numbers |
|---|---|
| Number of users | 9,728 |
| Number of point of interests | 12,449 |
| Number of check-ins | 177,142 |
| Number of reviews | 234,793 |
3.1.3. Evaluation Metrics
Evaluation metrics are essential for evaluating the effectiveness and performance of a recommendation model in the context of POI recommendation incorporating SA (Meena et al., 2022). These metrics help evaluate the model’s accuracy, relevance, and quality of recommendations.
By analyzing these metrics, we can determine the effectiveness and accuracy of the models. From the metrics, we can compare different recommendation models. These metrics help understand the model’s strengths and weaknesses and provide insights into areas for improvement and future research.
3.2. Sentiment Analysis Model
Fig. 2 presents the complete data preprocessing and model-building pipeline for a SA model using the Bag of Words (BOW) approach. The steps involved in the design and implementation of the proposed SA model are as follows.
Fig. 2
Schematic diagram of sentiment analysis model. BiLSTM, bidirectional long short-term memory.
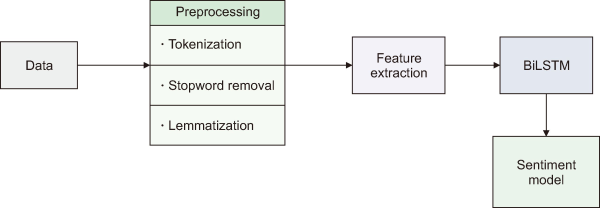
Loading and Cleaning the Election Dataset: The first step is to import all necessary libraries, such as pandas, NumPy, Keras, sci-kit-learn, matplotlib, nltk, etc., and load the election dataset, which contains text and sentiment columns. Any null or missing numbers, duplicate data, and fields that are not needed are taken out of the data to clean it up.
Preprocessing: Some classes of sentiment columns have significantly fewer samples than others. Equalizing the class distribution of the sentiment score column ensures that the model is not biased toward any particular class. It under-samples each sentiment label to the specified number of samples using the resample method of sklearn.utils library. The next step is to tokenize the text data, which involves breaking down the text into a list of individual words or tokens. This process also involves removing special characters, numbers, punctuation, and non-letter characters using regular expressions, and then removing the stop words using the nltk library, which involves eliminating common terms with little or no meaning, such as ‘a,’ ‘the,’ ‘and,’ and so on, and in the last step lemmatization to convert words to their base form is performed.
Feature Extraction: Feature extraction is performed using the BOW approach in the proposed model. It transforms the text data into a token count matrix. The CountVectorizer method of the sklearn.feature_extraction.text library is used to perform the BOW feature extraction.
Splitting the Dataset: The cleaned and preprocessed dataset is divided into 70% train and 30% test sets. The training set is used to train the BiLSTM model, while the test set evaluates the model’s performance.
BiLSTM Model for SA: Input text is first transformed into a fixed-length vector representation by an embedding layer; next, a BiLSTM layer is added to the model to learn about the text’s context and meaning. In conclusion, a dense layer with a softmax activation function is utilized to predict the sentiment of the text. The architecture of the BiLSTM model is shown in Table 2.
Table 2
Architecture of proposed bidirectional long short-term memory model
| Layer (type) | Output shape | Parameter |
|---|---|---|
| Embedding (Embedding) | (None, 50, 32) | 160,000 |
| Conv1d (Conv1D) | (None, 50, 32) | 3,104 |
| Max_pooling1d (MaxPooling1D) | (None, 25, 32) | 0 |
| Bidirectional (Bidirectional) | (None, 64) | 16,640 |
| Dropout (Dropout) | (None, 64) | 0 |
| Dense (Dense) | (None, 3) | 195 |
| Total params: 179,939 | ||
| Trainable params: 179,939 | ||
| Non-trainable params: 0 | ||
The BiLSTM performs both forward and backward evaluations of the input sequence, allowing gathering contextual information from past and future aspects of the input sequence, making the method well-suited for NLP applications such as SA. The BiLSTM model takes preprocessed text data as input and returns a sentiment score that might be positive, negative, or neutral. The model is built with cross-entropy loss and optimized with the Adam optimizer. Various metrics are used to determine the effectiveness of the proposed SA model using the testing set. After testing, the SA model is saved to predict the sentiments of a Foursquare text review as positive, negative, or neutral.
3.3. POI Recommendations Model
In the “POI Recommendation System using sentiment analysis,” the Foursquare dataset contains reviews for different POIs and their corresponding user IDs, POI IDs, and coordinates. Fig. 3 depicts a schematic diagram of the POI Recommendation Model, which includes the system processes. The Foursquare dataset review column is fed into the SA model to predict sentiment scores, which are then used to recommend POIs to users based on their choices.
Fig. 3
Schematic diagram of POI recommendation model. POI, point of interest; LSTM, long short-term memory.
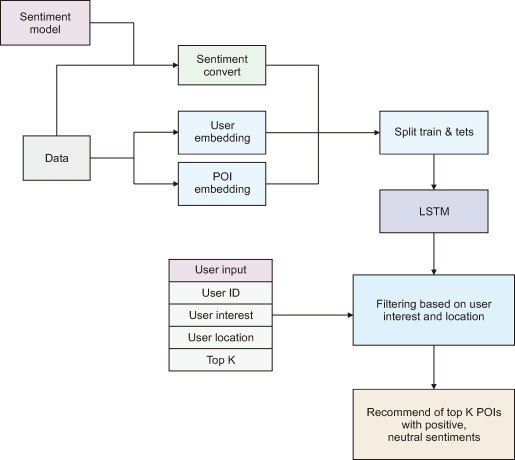
Rows containing null or missing values, duplicate rows, and unnecessary columns are dropped as a part of data preprocessing. The model uses tokenization, removing stop words and other unnecessary words, and lemmatization to preprocess the text review data of the Foursquare dataset. In tokenizing and padding the review data, the function tokenize_pad_sequences() takes in the text data and tokenizes it using the Tokenizer() method from the Keras library. It then converts the tokenized text into sequences of integers using the texts_to_sequences() method of the Tokenizer object. Finally, it uses the pad_sequences() method from TensorFlow.Keras library for padding the sequences with zeros to ensure sequences of the same length. The preprocessed text is then fed into the trained SA model, which predicts the sentiments. The predict_class () function is used to predict the sentiment class of each text entry, which can be negative, neutral, or positive.
The predict_class() function takes in a text as input, tokenizes and pads it using the same Tokenizer and padding method as before, and uses the loaded model to predict the sentiment class of the text. The model takes in a sequence of words, and for each word, it produces an output that is used to predict the sentiment score for the entire sequence. The function returns the predicted sentiment class. The predicted sentiment scores are -1, 0, and 1. Here, 1 represents positive sentiment, 0 represents neutral sentiment, and -1 represents negative sentiment.
Once the sentiment scores are predicted, they are added as a new column in the Foursquare dataset, called “score.” These scores are then used to filter and recommend top-k POIs with positive or neutral sentiment to the user.
To recommend POIs, the user and POI embedding are generated using the cleaned and preprocessed Foursquare dataset. User embeddings are a vector representation of each user based on their interactions with POIs. In contrast, POI embeddings are a vector representation of each POI based on the sentiment scores of the reviews. The embeddings are generated using a Word2Vec technique in the gensim library.
After applying the sentiment model, user and POI embedding are generated to represent each user and POI in a vector space. These embeddings are used as input features (X), and the predicted sentiment (score) is used as the target variable (y) for splitting and training the LSTM model. The dataset was then split 70:30 into train and test sets. Next, the system trains the proposed LSTM model as the architecture shown in Table 3 displays using the embedding and the user’s ratings for the POIs. The trained model predicts the sentiment of POIs based on user and POI embeddings.
Table 3
Proposed architecture of LSTM model for point of interest recommendation system
| Layer (type) | Output shape | Parameter |
|---|---|---|
| Embedding (Embedding) | (None, 100, 32) | 160,000 |
| Conv1d (Conv1D) | (None, 100, 32) | 3,104 |
| Max_pooling1d (MaxPooling1D) | (None, 50, 32) | 0 |
| LSTM (LSTM) | (None, 32) | 8,320 |
| Dropout (Dropout) | (None, 32) | 0 |
| Dense (Dense) | (None, 1) | 33 |
| Total params: 171,457 | ||
| Trainable params: 171,457 | ||
| Non-trainable params: 0 | ||
Then, the test dataset is used and preprocessed by tokenization, removal of unnecessary words, and lemmatization to filter the dataset based on the user’s interests. Further, a dataset is created using the list of keywords related to the user’s interest (a few users’ interests are defined, such as restaurant, museum, mall, library, hotel, educational, and emergency services). The process filters the data by keeping only the rows where the preprocessed “text” column contains keywords related to the particular user’s interest. It then shortens the resulting data. For example, if a user is interested in “restaurants,” we will filter the Foursquare dataset to include data related only to restaurants, cafes, and bars. Similarly, if a user is interested in “museums,” we will filter the dataset only to include data related to museums such as museums, galleries, and historic sites.
This step ensures that the recommended POIs correspond to the user’s interests, making it more likely that the user will visit and appreciate the places. To create the list of keywords related to user interest, we can combine manual curation and automated techniques, such as keyword extraction from users’ previous check-ins or search queries. Applying a filtering mechanism to the dataset according to the user’s interests guarantees that the suggested POIs are directly related to the user’s preferences and desires. This enhances the user’s overall experience and level of satisfaction.
The next step in the recommendation model is to take user input for their ID, location, interests, and the number of top recommendations they want. Based on this input, the system filters the dataset to show POIs that match the user’s interests and are within a certain radius of the user’s location.
After the dataset has been refined based on user interests, it is further filtered based on the user’s location. It ensures that the recommended POIs are within a reasonable distance of the user’s current location. The filtering is done by calculating the distance between the user and the POI’s location using the coordinate information available in the dataset, increasing the likelihood that the user will visit and enjoy the places suggested. The top POIs with positive or neutral sentiments are recommended to the user.
This study aims to give users tailored suggestions based on their interests, geography, and sentiment score. These recommendations can be positive or neutral, considering the sentiment of previous evaluations. Overall, this study blends SA with geographically specific recommendations.
4. RESULTS AND DISCUSSION
This study’s findings about the SA model and POI recommendation model using SA are presented, analyzed, and interpreted in this section to draw meaningful conclusions.
4.1. Sentiment Analysis Model
Table 4 displays the performance metrics of the SA model after 50 training epochs. These evaluation metrics showed that the model is good at categorizing the sentiment of text data (reviews) as positive, negative, or neutral. The model has an accuracy of 0.9952, which means that 99.52% of all reviews in the dataset were correctly classified as positive, negative, or neutral sentiment, a precision of 0.9953, which means that 99.53% of all reviews predicted as positive sentiment were positive, and a recall of 0.9951, which means that 99.51% of all actual positive reviews in the dataset were correctly predicted as positive sentiment by the model, and F1 score of 0.9952, showing that it predicts the sentiment of reviews in the election dataset fairly accurately. The comparative results of the proposed SA model and other state-of-art problems (Alemayehu et al., 2023; Dang et al., 2020; Khruahong et al., 2022) are also presented in Table 4, which clearly shows that the proposed models outperform the others in performance. Further, it is observed that the proposed models outperform others when applied to the other datasets, such as Tweets Airline and Amharic Political.
Table 4
Performance comparison of proposed sentiment analysis model with other state-of-art
| Author | Model | Dataset | Accuracy (%) | Precision (%) | Recall (%) | F1-score (%) |
|---|---|---|---|---|---|---|
| Dang et al. (2020) | Deep learning | Tweets airline | 90.45 | 93.06 | 95.09 | 94.06 |
| Khruahong et al. (2022) | BiLSTM | YouTube comments | 85.78 | 83.25 | 87.01 | 85.08 |
| Alemayehu et al. (2023) | BiLSTM | Amharic political | 85.27 | 85.24 | 81.67 | 83.42 |
| GRU | Amharic political | 88.99 | 90.61 | 89.67 | 90.14 | |
| Proposed method | BiLSTM with BOW | Tweets airline | 98.86 | 98.91 | 98.84 | 98.88 |
| Amharic political | 98.87 | 99.05 | 98.50 | 98.77 | ||
| India election | 99.52 | 99.53 | 99.51 | 99.52 |
A high F1 score suggests that the model has an appropriate balance of precision and recall, which are important for effective SA. Furthermore, the model consistently obtained good accuracy, precision, recall, and F1 score across 50 epochs, implying that the model is stable and does not overfit the data. The model’s improved performance, as shown in Table 4, can be due to implementing a BiLSTM with feature extraction using BOW, a deep learning model capable of properly capturing the sequential information in the review. Furthermore, the elimination of stop words and tokenization of the text data improved the model’s performance by lowering noise and boosting the quality of the input data. Overall, these findings illustrate that the SA model is highly accurate in predicting the sentiment of reviews and may be applied to analyze reviews in other datasets, as shown in Table 4.
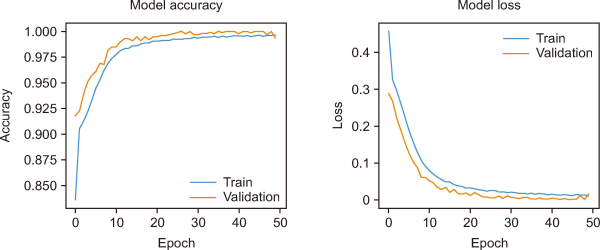
Fig. 4 illustrates the accuracy and loss of the proposed SA model. It shows that our model is working accurately. Validation and training accuracy increase as the epochs increase. Similarly, validation loss and training loss decrease as the epochs increase.
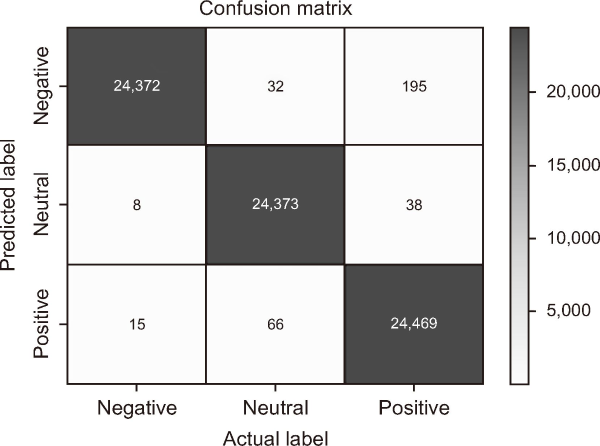
The SA model’s confusion matrix is displayed in Fig. 5. This method may be used to gauge how well the SA model is doing. Results show that 24,372 negative feelings, 24,373 neutral sentiments, and 24,469 good sentiments are all accurately predicted. The dataset also shows that the number of erroneous predictions is relatively low.
4.2. POI Recommendation Model Using SA
The proposed POI recommendation model is subsequently evaluated with the help of a test set that consists of thirty percent of the dataset. The model is trained using the training dataset, while the testing dataset determines the system’s performance.
The POI recommendation model’s output is the recommended POIs based on the user’s input. The recommended POIs are ranked based on the SA of the reviews linked with each POI and are filtered depending on the user’s location and interest. When filtering data based on user interest, the model’s performance may vary according to user input. If the user input is correct or complete, the predictions and accuracy of the recommendations may be improved.
Overall, the POI recommendation model provides a useful feature for users to discover and explore new locations of interest based on their location and SA. If the recommended POIs are relevant and have positive sentiments, they can be considered successful recommendations. Further research can explore ways to improve the model’s performance and accuracy, such as incorporating additional features, using more advanced deep learning models, or optimizing the model architecture. With further improvements and enhancements, the system has the potential to become a valuable tool for users looking to discover new and interesting places to visit.
The recall@k results for the proposed top POI recommendation model are provided in Table 5, along with a comparison to the outcomes of preceding models. The proportion that recall@k calculates out of the entire number of relevant items that might have been suggested is the percentage of relevant things that were recommended out of the total number of relevant items. Even though Zhou et al. (2019) have recall@5, recall@10, recall@15, and recall@20 values of 0.06, 0.10, 0.12, and 0.14, respectively, the recommended model recall@k climbs as k increases and reaches over 50%. Liu and Wu (2021) concluded that the values for recall@5, recall@10, recall@15, and recall@20 are, respectively, 0.19, 0.23, 0.28, and 0.32. Their research obtained this knowledge. For recall@5, recall@10, recall@15, and recall@20, respectively. Wang et al. (2019) obtained the values of 0.27, 0.32, 0.399, and 0.47. These values were recorded in their study. The researchers collected all of these values. Zhang et al. (2019) state that recall@5, recall@10, recall@15, and recall@20 values are 0.09, 0.15, 0.17, and 0.20, respectively. These values may be compared to one another. This set of values was obtained in a related manner. Yu et al. (2019) established that the values for recall@5, recall@10, recall@15, and recall@20 are, respectively, 0.12, 0.16, 0.19, and 0.22. The values Dai et al. (2019) found for recall@5, recall@10, recall@15, and recall@20 are 0.14, 0.17, 0.22, and 0.24, respectively. The researchers collected all of these values. It has been determined by Lu et al. (2019) that the values of recall@5, recall@10, recall@15, and recall@20 are 0.17, 0.24, 0.25, and 0.28, respectively. It was possible to acquire these values. The proposed model performed significantly better in terms of recall@5, recall@10, recall@15, and recall@20 when compared to the research works published by Zhou et al. (2019), Liu and Wu (2021), Wang et al. (2019), Zhang et al. (2019), Yu et al. (2019), Dai et al. (2019), and Lu et al. (2019). This was determined by comparing the suggested model to the research works performed by the authors above. Fig. 6 compares the proposed model and studies for recall@5, recall@10, recall@15, and recall@20.
Fig. 6
Performance of proposed POI recommendation model for recall@k versus top k POI recommendations. POI, point of interest.
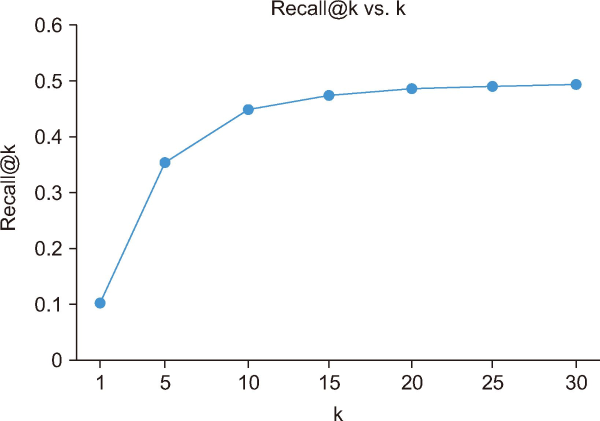
Table 5
Comparison of recall@k of proposed point of interest recommendation model with other state-of art
| Author | Recall@5 | Recall@10 | Recall@15 | Recall@20 |
|---|---|---|---|---|
| Zhou et al. (2019) | 0.06 | 0.10 | 0.12 | 0.14 |
| Liu & Wu (2021) | 0.19 | 0.23 | 0.28 | 0.32 |
| Wang et al. (2019) | 0.27 | 0.32 | 0.399 | 0.47 |
| Zhang et al. (2019) | 0.09 | 0.15 | 0.17 | 0.20 |
| Yu et al. (2019) | 0.12 | 0.16 | 0.19 | 0.22 |
| Dai et al. (2019) | 0.14 | 0.17 | 0.22 | 0.24 |
| Lu et al. (2019) | 0.17 | 0.24 | 0.25 | 0.28 |
| Proposed | 0.35 | 0.45 | 0.475 | 0.485 |
Table 6 shows how the proposed model stacks up against other state-of-the-art recommendations for top POIs in terms of precision@k. Precision@k is a measure that determines the percentage of the top k suggestions that are relevant or wanted by the user. It is evident from Table 6 that the precision@k of the suggested model drops with increasing k and approaches 38% approx. Still, the results for precision@5, precision@10, precision@15, and precision@20 were 0.07, 0.057, 0.049, and 0.043, respectively, according to Zhou et al. (2019). The precision@k values were not observed by Liu and Wu (2021). According to Wang et al. (2019), the various precision values were 0.38 for precision@5, 0.345 for precision@10, 0.326 for precision@15, and 0.288 for precision@20. According to the study by Zhang et al. (2019), the accuracy values for precision@5, precision@10, precision@15, and precision@20 were 0.12, 0.011, 0.01, and 0.005, respectively. Yu et al. (2019) documented precision values of 0.018, 0.02, 0.011, and 0.001 for precision@5, precision@10, and precision@15, respectively. The precise values for precision@5, precision@10, precision@15, and precision@20 achieved by Dai et al. (2019) were 0.028, 0.026, 0.017, and 0.001, respectively. Lu et al. (2019) achieved precision values of 0.045, 0.038, 0.028, and 0.02, respectively, for precision@5, precision@10, precision@15, and precision@20. Concurrently, the suggested POI recommendation models yielded values of 0.85 for precision@5, 0.63 for precision@10, 0.478 for precision@15, and 0.384 for precision@20. Therefore, in terms of accuracy@5, accuracy@10, accuracy@15, and accuracy@20, the suggested model surpassed other state-of-the-art.
Table 6
Comparison of precision@k of proposed point of interest recommendation model with other state-of-art
| Author | Precision@5 | Precision@10 | Precision @15 | Precision@20 |
|---|---|---|---|---|
| Zhou et al. (2019) | 0.07 | 0.057 | 0.049 | 0.043 |
| Wang et al. (2019) | 0.38 | 0.345 | 0.326 | 0.288 |
| Zhang et al. (2019) | 0.12 | 0.011 | 0.01 | 0.005 |
| Yu et al. (2019) | 0.018 | 0.02 | 0.011 | 0.001 |
| Dai et al. (2019) | 0.028 | 0.026 | 0.017 | 0.001 |
| Lu et al. (2019) | 0.045 | 0.038 | 0.028 | 0.02 |
| Proposed | 0.85 | 0.63 | 0.478 | 0.384 |
The graph of the precision@k with the k of the POI Recommendation Model is displayed in Fig. 7. It is observed that the values of precision@k decrease as k increases, and the proposed model has the best precision@k values as compared to other state-of-the-art (Fig. 8). Fig. 9 illustrates the bar graph comparing the results of recall@5, recall@10, recall@15, and recall@20 between the research presented by Zhou et al. (2019), Wang et al. (2019), Zhang et al. (2019), Yu et al. (2019), Dai et al. (2019), and Lu et al. (2019), and the model that proposed.
Fig. 7
Performance of proposed POI recommendation model for precision@k versus top k POI recommendation. POI, point of interest.
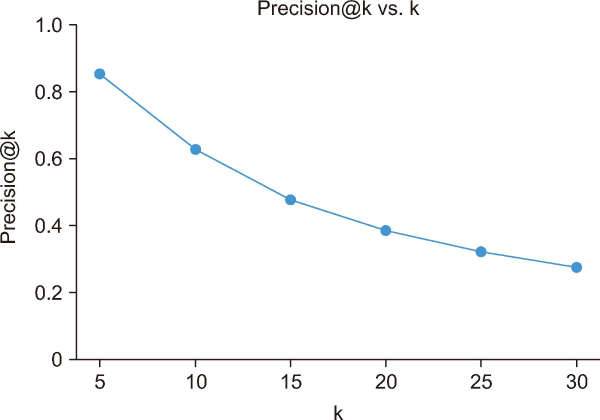
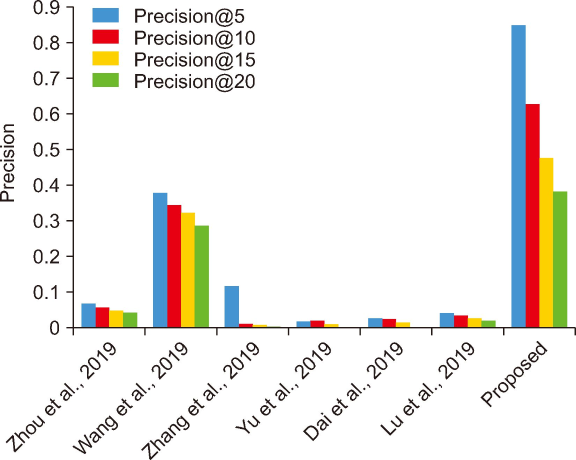
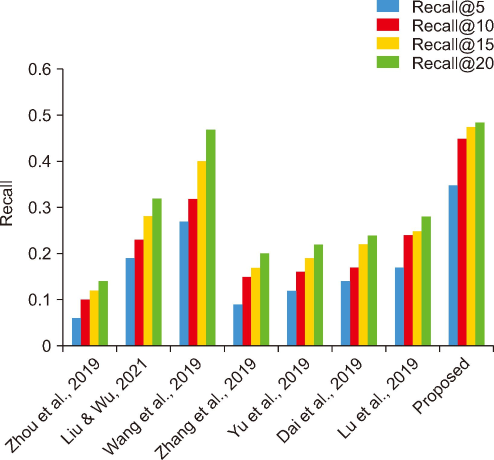
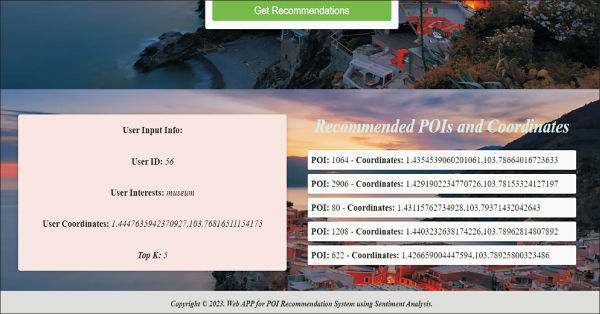
Fig. 10 presents recommended top k POIs with coordinates for a given user using the web application developed for the proposed model.
5. CONCLUSIONS
This study focused on developing a POI recommendation system that effectively integrated the SA model with the POI recommendation model. By integrating these components, the system demonstrated a deeper understanding of user preferences and emotions expressed in their reviews, resulting in a more targeted recommendation process. The system provided a more targeted recommendation process by filtering reviews based on user interests. The LSTM model was utilized to identify long-term dependencies in sequential data, resulting in precise and personalized POI suggestions.
The proposed system effectively generates personalized and relevant user recommendations based on interests, location, and sentiment labels from user-generated text reviews. The proposed system consists of six main steps: data preprocessing, SA using BiLSTM, converting reviews to sentiment labels, POI recommendation modeling using SA model, filtering data based on user interest and location, and designing the user interface. The proposed model leverages the power of SA to understand user preferences and emotions expressed in their reviews, in order to train a recommendation model that employs user embeddings, POI embeddings, and sentiment labels to offer pertinent POIs to the user based on user interests, produce a more targeted recommendation process, and anticipate the sentiment of reviews for different points of interest. In recognizing the sentiment of user reviews, the SA model achieved decent accuracy (99.52%), precision (99.53%), recall (99.51%), and F1-score (99.52%) as compared to other state-of-arts. The POI recommendation algorithm also did well when proposing relevant points of interest to users based on their interests and location, with recall (48.5%) and precision (85%) compared to other state-of-arts. The study demonstrated that the proposed model can effectively generate personalized and relevant POI recommendations, helping users discover new and interesting POIs. It showcases the potential benefits of integrating SA into any recommender system for users and businesses.
Another fact that should be mentioned here is that the SA model is prepared on one dataset (an election dataset). Then, this model was used to develop the proposed POI recommendation model using the Foursquare dataset with LSTM, which gives it more strength to extract the characteristics of two different datasets and inculcate them into a single model. This strength makes it more generalizable and applicable to other datasets and scenarios.
As the proposed model is trained and tested using only two datasets (the election dataset for SA and the Foursquare dataset for POI recommendation), this model will perform optimally for the applications that match the domains of these two datasets. Otherwise, this model might perform sub-optimally for other domains.
Further, the following points/suggestions can be considered for future work: incorporating more data sources, implementing more advanced recommendation algorithms, incorporating more features, personalizing for individual users, extending the radius of filtering, adding negative sentiment scores, incorporating real-time data, and improving scalability to handle large datasets or real-time recommendations. Discovering more customized, relevant, and engaging experiences when discovering new points of interest may be achieved by continuing to expand and enhance POI recommendation systems. Future research paths in this subject can benefit from investigating these topics.
REFERENCES
, , (2021) Tourism recommendation system based on semantic clustering and sentiment analysis Expert Systems with Applications, 167, 114324 https://doi.org/10.1016/j.eswa.2020.114324.
, , (2024) Long-term preference mining with temporal and spatial fusion for point-of-interest recommendation IEEE Access, 12, 11584-11596 https://doi.org/10.1109/ACCESS.2024.3354934.
, , (2023) Amharic political sentiment analysis using deep learning approaches Scientific Reports, 13(1), 17982 https://doi.org/10.1038/s41598-023-45137-9. Article Id (pmcid)
, , , (2019) Attentive stacked denoising autoencoder with Bi-LSTM for personalized context-aware citation recommendation IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 553-568 https://doi.org/10.1109/TASLP.2019.2949925.
, , , (2021) An approach to integrating sentiment analysis into recommender systems Sensors (Basel, Switzerland), 21(16), 5666 https://doi.org/10.3390/s21165666. Article Id (pmcid)
, , , (2020) Sentiment analysis based on deep learning: A comparative study Electronics, 9(3), 483 https://doi.org/10.3390/electronics9030483.
, (2018) RecNet: A deep neural network for personalized POI recommendation in location-based social networks International Journal of Geographical Information Science, 32(8), 1631-1648 https://doi.org/10.1080/13658816.2018.1447671.
, , , , , (2022) Deep GraphSAGE-based recommendation system: Jumping knowledge connections with ordinal aggregation network Neural Computing and Applications, 34(14), 11679-11690 https://doi.org/10.1007/s00521-022-07059-x.
, , , , , (2022) CARAN: A context-aware recency-based attention network for point-of-interest recommendation IEEE Access, 10, 36299-36310 https://doi.org/10.1109/ACCESS.2022.3161941.
, (2021) POI recommendation method using deep learning in location-based social networks Wireless Communications and Mobile Computing, 2021, 9120864 https://doi.org/10.1155/2021/9120864.
, , , , (2019) On successive point-of-interest recommendation World Wide Web, 22(3), 1151-1173 https://doi.org/10.1007/s11280-018-0599-5.
, , (2022) Categorizing sentiment polarities in social networks data using convolutional neural network SN Computer Science, 3(2), 116 https://doi.org/10.1007/s42979-021-00993-y.
, , , , (2020) Text based sentiment analysis using LSTM International Journal of Engineering Research & Technology, 9(5), 299-303 https://doi.org/10.17577/IJERTV9IS050290.
, (2021) Recommender system for sentiment analysis using machine learning models Turkish Journal of Computer and Mathematics Education, 12(10), 583-588 https://turcomat.org/index.php/turkbilmat/article/view/4216.
, , , , (2020) Sentiment analysis using gated recurrent neural networks SN Computer Science, 1(2), 74 https://doi.org/10.1007/s42979-020-0076-y.
, , , , , (2020) Where to go next: Modeling long- and short-term user preferences for point-of-interest recommendation Proceedings of the AAAI Conference on Artificial Intelligence, 34(1), 214-221 https://doi.org/10.1609/aaai.v34i01.5353.
, , (2023) POI recommendation method using LSTM-attention in LBSN considering privacy protection Complex & Intelligent Systems, 9(3), 2801-2812 https://doi.org/10.1007/s40747-021-00440-8.
, , , , , (2019) Trust-enhanced collaborative filtering for personalized point of interests recommendation IEEE Transactions on Industrial Informatics, 16(9), 6124-6132 https://doi.org/10.1109/TII.2019.2958696.
, , , , (2019) A novel next new point-of-interest recommendation system based on simulated user travel decision-making process Future Generation Computer Systems, 100, 982-993 https://doi.org/10.1016/j.future.2019.05.065.
, , , , (2019) Point-of-interest recommendation based on user contextual behavior semantics International Journal of Software Engineering and Knowledge Engineering, 29(11n12), 1781-1799 https://doi.org/10.1142/S0218194019400217.
, , , (2019) Fused matrix factorization with multi-tag, social and geographical influences for POI recommendation World Wide Web, 22(3), 1135-1150 https://doi.org/10.1007/s11280-018-0579-9.
, , , , , , (2021) DEAR: Deep reinforcement learning for online advertising impression in recommender systems Proceedings of the AAAI Conference on Artificial Intelligence, 35(1), 750-758 https://doi.org/10.1609/aaai.v35i1.16156.
- Submission Date
- 2023-10-17
- Revised Date
- 2024-03-05
- Accepted Date
- 2024-03-20
- Downloaded
- Viewed
- 0KCI Citations
- 0WOS Citations