JOURNAL OF INFORMATION SCIENCE THEORY AND PRACTICE
- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

2권 4호
초록
Abstract
The description of preserved resources is one of the requirements in digital preservation. The description is generally created in the format of metadata records, and those records are combined to generate information packages to support the process of digital preservation. However, current strategies or models of digital preservation may not generate information packages in efficient ways. To overcome these problems, this research proposed an internal structure of information packages in digital preservation. In order to construct the internal structure, this research analyzed existing metadata standards and cataloging rules such as Dublin Core, MARC, and FRBR to extract the core elements of resource description. The extracted elements were categorized according to their semantics and functions, which resulted in three categories of core elements. These categories and core elements were manifested by using RDF syntax in order to be substantially applied to combine metadata records in digital preservation. Although the internal structure is not intended to create metadata records, it is expected to provide an alternative approach to enable combining existing metadata records in the context of digital preservation in a more flexible way.






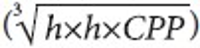
초록
Abstract
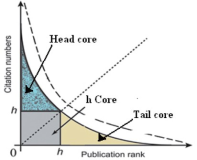
This study examines the foremost concerns related to most noted research performance index. The most popular and widely acceptable h-index underestimates the highly visible scientist, the middle order group, due to citation distribution issues. The study addresses this issue and uses 'Corrected Quality Ratio' (CQ) to check the implicit underpinnings as evident in h-index. CQ helps to incorporate the aspects of a good research performance indicator. This simple revision performs more intimately and logically to gauge the broader research impact for all groups and highly visible scientists with less statistical error.







초록
Abstract
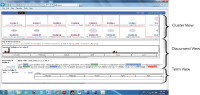
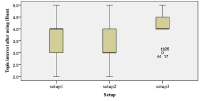
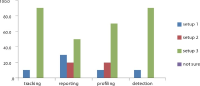
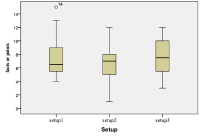
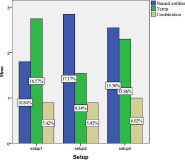
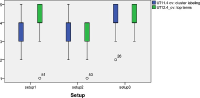
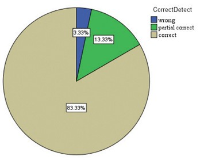
The proliferation of many interactive Topic Detection and Tracking (iTDT) systems has motivated researchers to design systems that can track and detect news better. iTDT focuses on user interaction, user evaluation, and user interfaces. Recently, increasing effort has been devoted to user interfaces to improve TDT systems by investigating not just the user interaction aspect but also user and task oriented evaluation. This study investigates the combination of the bag of words and named entities approaches implemented in the iTDT interface, called Interactive Event Tracking (iEvent), including what TDT tasks these approaches facilitate. iEvent is composed of three components, which are Cluster View (CV), Document View (DV), and Term View (TV). User experiments have been carried out amongst journalists to compare three settings of iEvent: Setup 1 and Setup 2 (baseline setups), and Setup 3 (experimental setup). Setup 1 used bag of words and Setup 2 used named entities, while Setup 3 used a combination of bag of words and named entities. Journalists were asked to perform TDT tasks: Tracking and Detection. Findings revealed that the combination of bag of words and named entities approaches generally facilitated the journalists to perform well in the TDT tasks. This study has confirmed that the combination approach in iTDT is useful and enhanced the effectiveness of users' performance in performing the TDT tasks. It gives suggestions on the features with their approaches which facilitated the journalists in performing the TDT tasks.












초록
Abstract
The present discourse lasts around, information pollution, causes and concerns of information pollution, internet as a major causality and how it affects the decision making ability of an individual. As, information producers in the process to not to lose the readership of their content, and to cater the information requirements of both the electronic and the print readers, reproduce almost the whole of the printed information in digital form as well. Abundant literature is also equally produced in electronic format only, thereon, sharing this information on hundreds of social networking sites, like, Facebook, Twitter, Blogs, Flicker, Digg, LinkedIn, etc. without attributions to original authors, have created almost a mess of this whole information produced and disseminated. Accordingly, the study discusses about the sources of information pollution, the aspects of unstructured information along with plagiarism. Towards the end of the paper stress has been laid on information literacy, as how it can prove handy in addressing the issue with some measures, which can help in regulating the behaviour of information producers.
초록
Abstract
The exponential growth of information on the web far exceeds the capacity of present day information retrieval systems and search engines, making information integration on the web difficult. In order to overcome this, semantic web technologies were proposed by the World Wide Web Consortium (W3C) to achieve a higher degree of automation and precision in information retrieval systems. Semantic web, with its promise to deliver machine understanding to the traditional web, has attracted a significant amount of research from academia as well as from industries. Semantic web is an extension of the current web in which data can be shared and reused across the internet. RDF and ontology are two essential components of the semantic web architecture which support a common framework for data storage and representation of data semantics, respectively. Ontologies being the backbone of semantic web applications, it is more relevant to study various approaches in their application, usage, and integration into web services. In this article, an effort has been made to review the research work being undertaken in the area of design and development of ontology supported information systems. This paper also briefly explains the emerging semantic web technologies and standards.