JOURNAL OF INFORMATION SCIENCE THEORY AND PRACTICE
- P-ISSN : 2287-9099
- E-ISSN : 2287-4577
- Publisher : 한국과학기술정보연구원
- CCL :


6개 논문이 있습니다.
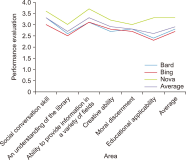
The purpose of this study is to investigate the possibility of using chatbots as a school library educational tool. In order to achieve the purpose of the study, 116 librarian teachers first investigated the types and contents of education conducted in the school library setting and the perception of chatbots there. In addition, 15 librarians (five elementary, five middle, and five high school) were asked to complete a structured questionnaire after using Google’s Bard, Microsoft’s Bing, and OpenAI’s Nova to find out if it is possible to use chatbots in school library education. As a result, user and reading education chatbots were found to be common in school libraries, and 99% of librarians knew about them in some detail. However, the average chatbot performance by area was 2.9 out of 5 (2.6 points being the lowest). Nevertheless, chatbots are being developed utilizing deep learning methodologies and have excellent performance, and are very effective for content-based library education through problem-solving activities.
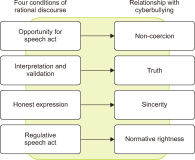
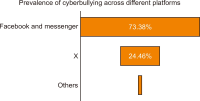
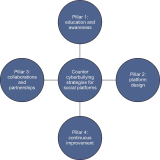
This qualitative study explores cyberbullying among college students through Habermas’s Theory of Communicative Action to examine the dissonance between online interactions and principles of rational discourse. Cyberbullying is a pervasive issue in digital communication that undermines logical, evidence-based conversation, fostering environments where misinformation, manipulation, and harm thrive. By analyzing case studies from three universities, the research identifies the characteristics, dynamics, and emotional impacts of cyberbullying on victims, highlighting the role of social media platforms in facilitating these negative interactions. The findings reveal significant challenges to authentic and equal online conversations, driven by power imbalances and a lack of genuine communication, leading to psychological distress, erosion of self-esteem, and changes in behavior among victims. The study underscores the potential of social media design and policy interventions to mitigate cyberbullying, emphasizing the need for educational programs, technological solutions, and community support to promote a safer, more respectful digital environment. Key themes include the dynamics of cyberbullying, the suppression of rational discourse, the psychological and emotional consequences of inauthentic communication, and strategies for resilience and recovery. The research contributes to understanding cyberbullying’s complexities and suggests a multifaceted approach to addressing it, aligning with Habermas’s ideal of communicative rationality to foster healthier online communities. Future research should further explore the intersection of technology design, user behavior, and regulatory policies to combat cyberbullying effectively.

The information retrieval (IR) process often encounters a challenge known as query-document vocabulary mismatch, where user queries do not align with document content, impacting search effectiveness. Automatic query expansion (AQE) techniques aim to mitigate this issue by augmenting user queries with related terms or synonyms. Word embedding, particularly Word2Vec, has gained prominence for AQE due to its ability to represent words as real-number vectors. However, AQE methods typically expand individual query terms, potentially leading to query drift if not carefully selected. To address this, researchers propose utilizing median vectors derived from deep median networks to capture query similarity comprehensively. Integrating median vectors into candidate term generation and combining them with the BM25 probabilistic model and two IR strategies (EQE1 and V2Q) yields promising results, outperforming baseline methods in experimental settings.
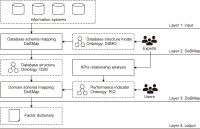
Strategy monitoring is essential for business management and for administrators, including managers and executives, to build a data-driven organization. Having a tool that is able to visualize strategic data is significant for business intelligence. Unfortunately, there are gaps between business users and information technology departments or business intelligence experts that need to be filled to meet user requirements. For example, business users want to be self-reliant when using business intelligence systems, but they are too inexperienced to deal with the technical difficulties of the business intelligence systems. This research aims to create an automatic matching framework between the key performance indicators (KPI) formula and the data in database systems, based on ontology concepts, in the case study of Prince of Songkla University. The mapping data schema with ontology (MapDSOnto) framework is created through knowledge adaptation from the literature review and is evaluated using sample data from the case study. String similarity methods are compared to find the best fit for this framework. The research results reveal that the “fuzz.token_set_ratio” method is suitable for this study, with a 91.50 similarity score. The two main algorithms, database schema mapping and domain schema mapping, present the process of the MapDS-Onto framework using the “fuzz.token_set_ratio” method and database structure ontology to match the correct data of each factor in the KPI formula. The MapDS-Onto framework contributes to increasing self-reliance by reducing the amount of database knowledge that business users need to use semantic business intelligence.





This study aimed to develop a digital thesaurus dedicated to cataloging the traditional common culture of the Greater Mekong Subregion. The process followed a meticulous seven-step methodology, including scoping, vocabulary collection, knowledge structure analysis, relationship delineation, related word adjustments, list validation, and evaluation. Leveraging principles from knowledge organization, thesaurus construction, and digital platform development, the TemaTres web application emerged as the primary tool for constructing this thesaurus. The study’s results showed that 2,042 principal words related to the traditional common culture of the Greater Mekong Subregion were compiled and classified into terms for each of the seven deep levels. Each term was accompanied by essential metadata, including broader and narrower terms, related terms, cross-references, and scope notes. This rich dataset empowered semantic search capabilities across diverse applications and web services, providing access to knowledge pertaining to the traditional common culture of the Greater Mekong Subregion and contributing to a deeper understanding of this cultural domain.


This study aims to assess the maturity of Korean open access (OA) journals using the OA infrastructure provided by the Korea Institute of Science and Technology Information, and develop necessary strategies for future improvement. The assessment model consists of three dimensions, 12 items, and 24 sub-items. The importance of the three dimensions (A: OA policy establishment and disclosure, B: OA sustainability, and C: Journal openness quality) was differentiated by the Analytic Hierarchy Process, and the maturity stages were divided into five levels (Entry, Growth1, Growth2, Maturity1, and Maturity2). The assessment was carried out twice for 100 academic journals. The results indicated that the proportion of journals at or above the Growth1 level increased by 11% to reach 83% during the second assessment phase, which could be owing to the learnings of the first assessment. Following expert consultations on the assessment results, three support measures were identified to activate OA. The first includes OA promotion and education activities, which involve creating standard regulations and guidelines, and advancing educational activities for societies that are either preparing for or currently implementing OA. The second involves providing support for technical aspects, such as identifiers, XMLization, and copyright management, through peer review and OA publishing platforms. The third includes collaborative activities to enhance journal evaluations and the recognition criteria for researchers’ achievements in OA journals, and fostering cooperation with national and research and development institutions for financial support.