- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

Topic Modeling Approach on Twitter Data Relevant to Political Changes During the COVID-19 Pandemic

K. S. Ranasinghe (Department of Economics and Statistics, Sabaragamuwa University of Sri Lanka, Belihuloya, Sri Lanka)
R. A. H. M. Rupasingha (Department of Economics and Statistics, Sabaragamuwa University of Sri Lanka, Belihuloya, Sri Lanka)

Abstract
The COVID-19 pandemic has affected various sectors of society, including politics. The political changes have had both positive and negative impacts on people’s lives. Different public discussions happened during that situation on social media. It is essential to understand those discussions to prepare for the same kind of situation in future. Therefore, this study aims to identify the topics discussed on Twitter regarding this influence. During March 2020 and December 2021, 10,658 Tweets were gathered through the Twitter application programming interface and preprocessed using Python libraries. After feature extraction using the bag-ofwords method, both probabilistic latent semantic analysis (PLSA) and latent Dirichlet allocation (LDA) were used as topic modeling methods. As a result of the analysis, 15 topics by LDA and 25 topics by PLSA were extracted during the study and then grouped into five key themes: Government responses for managing the COVID-19 Pandemic, Government decisions for COVID-19, Public response to government measures for COVID-19, Social influence, and Vaccination. Through a comparative evaluation of the LDA and PLSA topic modeling techniques, the research identifies LDA as the superior method, providing more accurate and coherent results.
- keywords
- COVID-19, political changes, topic modeling, Twitter, public opinion
1. INTRODUCTION
Epidemics are not new to humans. Humanity has already been affected by major epidemics such as Ebola, the bird flu virus, and the H1N1 influenza pandemic (Lim, 2021). However, the coronavirus disease (COVID-19) has caused more impact than any other virus because humans have low immunity to fight this virus. COVID-19 is a lung infection resulting from the SARS-CoV-2 virus (World Health Organization, n.d.). The virus’s origin is still unidentified, but it is believed to have originated in Wuhan, China in December 2019. Since then, the disease has spread rapidly worldwide, becoming a global pandemic. The COVID-19 pandemic spread globally, devastatingly affecting health, socioeconomics, and the environment. Its impact resulted in economic and social changes and trends. The political role is given special consideration in this situation. COVID-19 pressures political structures worldwide, whether dictatorial or democratic, to provide adequate emergency epidemic control. Global leaders have taken critical actions to control the virus’s spread. They have increased investment in healthcare infrastructure and resources and implemented social distancing measures, such as lockdowns and restrictions on public gatherings, to slow the spread of the virus. In addition, there has been a tendency to use technology for everyday tasks. For example, many companies use online shopping and delivery services, and schools adopt remote work and education activities to reduce the risk of exposure to the virus. The government has given guidelines for these solutions.
The pandemic has also affected political parties, with many elections and political events postponed or cancelled due to public health concerns. During this epidemic, the policy decisions taken by political leaders should be sufficient to solve the crisis and strengthen the confidence of the community and followers. Both positive and negative impacts of the COVID-19 epidemic have been observed within politics. Hence, it is essential to analyze people’s ideas about the changes that have taken place in politics since the pandemic situation.
In the global community, opinion analysis and research on social media have become increasingly important topics among researchers because of the vast amount of information representing social opinion that can be easily accessed and specialized. Moreover, performing comparative analyzes on data from various countries may aid in making relevant global comparisons (Howoldt et al., 2023). Social media analysis is essential for politicians because it provides beneficial insights into public opinion and sentiment. Understanding public opinion, identifying key issues that are important to their constituents, targeting specific groups of voters based on their interests and behaviors, and measuring the effectiveness of their campaigns to help politicians respond quickly to crises and manage their reputations are some reasons that social media analysis is essential for politicians. To achieve this, Twitter has launched a newly developed track called the “Academic Research Product Track” (Parack, 2021). Twitter is a public platform that is visible to everyone. Therefore, it is a widely-used microblogging platform and a quick and straightforward platform to send short messages and share tweets, GIFs, article links, videos, and other media, and users can successfully spread political opinions and general information among their networks.
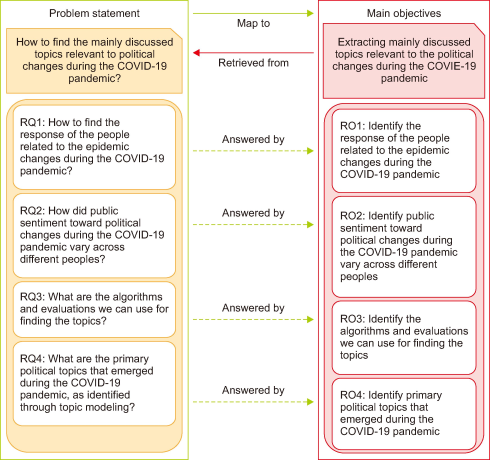
Accordingly, the main problem of this research is identified as “How can the topics that were discussed in relevance to political changes during the COVID-19 pandemic be found?” Based on this, the main objective of this study is to extract the topics discussed as most relevant to political changes during the COVID-19 pandemic using a topic modeling approach. This analysis helps to gain a deeper understanding of uncovering hidden themes of political changes. Fig. 1 shows the graphical representation of the mapping of research questions and objectives in this study.
Fig. 1
Mapping of the research question and research objectives. COVID-19, coronavirus disease; RQ, research questions; RO, research objectives.
We used topic modeling as a methodology to identify patterns of political behavior related to the identified research questions. Topic modeling is one of the natural language processing (NLP) techniques used to extract data and identify topics or themes in a collection of text documents (Manthiramoorthi, n.d.). It involves using algorithms to automatically identify patterns and clusters of words that frequently occur together in the text. The main objective of this research is to extract topics relevant to the political changes during the COVID-19 pandemic. This gives a better understanding of how political parties have adapted and responded to the pandemic in terms of their policies and actions. The results help to compare and contrast the political changes and responses to the pandemic across different regions and countries. The relevant parties can evaluate the effectiveness of different political strategies and responses to the pandemic based on public reactions and feedback on social media. They can apply those changes in future pandemic situations and make better political plans for their future campaigns in the country.
The study’s remaining sections are structured as follows: The second section describes the literature review. The third section explains the methodology. The fourth section explains the results and discussion. Finally, section five describes the conclusion of our research.
2. LITERATURE REVIEW
2.1. Social Media and Politics
Various research papers observe that media and political information or news influence public opinion widely. Because of this, social media has become an increasingly important topic among researchers. Social media analysis is essential for politicians because it provides valuable insights into public opinion tracking and measuring. Candidates create systems for monitoring and evaluating online activity, such as communication on Facebook, Instagram, and Twitter, and compare it with their conventional ones. Understanding public opinion, identifying key issues that are important to their constituents, targeting specific groups of voters based on their interests and behaviors, and measuring the effectiveness of their campaigns to help politicians respond quickly to crises and manage their reputations are some reasons social media analysis is essential for politicians (Mameli et al., 2022).
Meduru et al. (2017) realised that there is a connection gap between citizens and their government. As a result of this communication gap, policy decisions implemented directly or indirectly by the government may fail. Further research suggests using the Vader Lexicon to analyze opinions using Twitter feeds for political analysis. The use of Twitter to frame the COVID-19 virus was investigated using four methods by leaders of the “Five Eyes” intelligence-sharing group, which includes the United States, the United Kingdom (UK), Australia, New Zealand, and Canada. It has been suggested that implementing a new algorithm utilizing the benefits of several algorithms can increase the accuracy of the algorithms so that they can be effectively used in forecasting.
A sentiment-based classifier using machine learning and a “Fuzzy Set and Rough Set approach” for predicting the results of the 2019 presidential election of Sri Lanka, using tweets from September 1 to November 10, 2019 (two months before the election) for both “Gotabaya Rajapaksa” and “Sajith Premadasa,” was also developed by Perera and Karunanayaka (2022). This study reveals flaws and limits in sentiment-based classifiers regarding political tweets associated with this 2019 presidential election case study. It has been suggested that implementing a new algorithm utilizing the benefits of several algorithms can increase their accuracy, so that they can be effectively used in forecasting. Howard and Parks (2012) suggest that communication researchers are uniquely positioned to analyze the relationship between social media and political transformation in terms of both causes and effects. In Bermingham and Smeaton (2011), when considering the Irish General Election, the case study to investigate the potential of modelling political sentiment through social media data mining, discovered that social analytics using both volume-based measures and sentiment analysis is predictive. Several observations are related to monitoring public sentiment during an election campaign, such as examining a variety of sample sizes, periods, and methods of qualitatively exploring the underlying factors. This could involves investigating how politicians’ mistakes on social media platforms affected people’s opinions of Twitter communication and their responses to other politicians’ tweets (Lee et al., 2020). These results highlighted that political gaffes made by politicians on social media may, ironically, improve the success of their efforts by creating a sense of genuine dialogue.
In a study of presidential elections in Egypt, users from different cultures and backgrounds on social networks such as Facebook and Twitter focused on a large number of textual comments that reflected their views in various situations (Elghazaly et al., 2016). The study used support vector machine (SVM) and Nave Bayesian to classify the Arabic text. The comparison showed that the Nave Bayesian technique has the best accuracy and lowest error rate. The study by Bose et al. (2019) further demonstrate how data twitter can be used and how the national research council Emotion Lexicon can be used to analyze politics. According to the 14th Gujarat Legislative Assembly elections of 2017 in India, a dataset of Twitter messages related to the election was used to predict the chances of party victory. Then, the sentiment was analyzed as positive, negative, and neutral, and the results were summarized.
2.2. COVID-19 Pandemic and Politics
The COVID-19 pandemic has had a significant impact on politics around the world. In some countries, the pandemic has led to political instability and unrest, mainly because governments have been slow to respond to the crisis, and the lack of management and information received by the health sector has led to social unrest. Summarizing these facts, politics has been tested through several variable aspects during the epidemic period. Palmer (2021) investigates the political attitudes and behavior of residents of states in the United States. The data set consists of demographic factors on education, race, age, and social trust, with tested policy specifications, social trust, and relationship with policy outcomes. Statistical diagnostic methods were used to examine outliers’ distribution and the possible influence and impact to uncover essential failings within all models. The analyzes’ assumptions have been meticulously interpreted using data.
Rieger and Wang (2022) examined data from 57 countries between March 20 and April 22, 2020 on how various factors such as education, actual stringency level, media freedom, and death rate affect judgments of government policy responsiveness and how people perceive government responses. Survey evidence shows that conspiracy theorists tend to take government counterattacks to be harsh. Purushothaman and Moolakkattu (2021) look at previous studies, press reports, and press releases by government agencies to gather the necessary data from India. The research questions investigated in their article are government response to the pandemic, containment measures, government consolidation of power and international status-seeking, and foreign policy related to the impact of the pandemic and vaccination diplomacy. Montiel et al. (2021) have mapped the political rhetoric of national leaders and characterized global changes during the COVID-19 pandemic. For this, the main rhetorical stories in the publicly available speeches of 26 countries were used as a sample. Lipscy (2020) proposes a broad investigation centered on causes, reactions, and transformations. The COVID-19 pandemic hence highlights the need for more scholarly attention to the political crisis. International relations have focused on military crises, neglecting non-militarized crises such as pandemics. To understand crises, researchers must examine the threat, uncertainty, and time pressure that impact political and economic outcomes. Another paper discusses predicting responses using political-related blogs as primary data. Yano et al., (2009) examined 40 blog sites from November 2007 to October 2008, and the latent Dirichlet allocation (LDA) topic model was used to generate the topics. This provides a qualitative discussion model on a novel comment prediction task, which uses models to predict which blog users will comment on a given post.
2.3. Methodological Review
Different methods are utilized for evaluating social media data and political facts. To evaluate public opinion on the central UK government during the first phase of the COVID-19 epidemic, structural topic modeling was used to extract topics from 4,000 free-text survey responses collected between October 14 and November 26, 2020 (Wright et al., 2022). Overall, they classified answers as positive or negative using sentiment analysis. Specifically, Bogdanowicz and Guan (2022) identified the 12 most popular topics in our dataset from April 3 to April 13, 2020, such as politics, health care, community, and economy, and discussed their growth and changes over time. While macro-level growth has been experienced over time, it is clear that micro-level changes in topic composition have also been exhibited. The research by Rathnayaka and Rupasingha (2023) outlined the sentiment analysis on Twitter data, focusing on the COVID-19 pandemic and political changes’ impacts on people’s lives. Their work employed both machine learning and deep learning techniques, specifically SVM, artificial neural network, and long short-term memory for the categorization of tweets into positive, negative, and neutral sentiments.
Guo et al. (2016) examine two big data text analysis methods: lexicon-based analysis, the most popular automated analysis approach in social science research, and unsupervised topic modeling (LDA analysis). Analyzing 77 million tweets about the 2012 United States presidential election, the study provides a starting point for scholars to evaluate the effectiveness and validity of journalism and various computer-based methods. Notably, the study by Guo et al. (2016) revealed that the two methodologies significantly produced different results. The LDA-based analysis, in particular, was able to read more tweets and reveal deeper subtleties of the conversation. The LDA-based analysis was also determined to be more valid than the dictionary-based technique based on human coder ratings. The LDA-based analysis is cost-effective since it requires little human labor. This demonstrates that, in general, LDA-based analysis outperforms other computer-based approaches.
Olbrich and Yamshchikov (2018) have chosen probabilistic LDA topic modeling to develop political space, which is widely used in NLP, with a particular focus on developing unsupervised text analysis methods. As LDA can generate meaningful political spaces, new dimensions of political discourse can be identified. Because of the qualitative nature of working with textual data, it is evident that the evaluation of the LDA model’s findings is both quantitative and qualitative. This paper introduces probabilistic latent semantic analysis (PLSA) and LDA as Twitter user opinion extraction methods. It is unrelated to the COVID-19 pandemic and politics, but provides a comprehensive explanation regarding topic formatting (Gandhi, 2021). It utilizes Dirichlet priors for the document-topic and word-topic distributions, allowing for better generalization.
Probabilistic topic models have recently received much attention because of their performance in various text-mining tasks such as retrieval, summarization, categorization, and clustering (Lu et al., 2011). In recent years, probabilistic topic modeling has been frequently applied to research topic modeling to focus on finding hidden topics in large documents.
The comparison summary with previous studies is discussed in Table 1 (Bermingham & Smeaton, 2011; Bose et al., 2019; Elghazaly et al., 2016; Lee et al., 2020; Montiel et al., 2021; Palmer, 2021; Purushothaman & Moolakkattu, 2021; Rathnayaka & Rupasingha, 2023; Rieger & Wang, 2022; Wright et al., 2022; Yano et al., 2009).
Table 1
Summary of comparison with previous studies
| Reference | Data | Methodology | Objective | Limitation/difference |
|---|---|---|---|---|
| Bermingham & Smeaton (2011) | Twitter data | Sentiment analysis through SVM algorithm | Irish general election as a case study for investigating the potential to model political sentiment through Twitter data | Targeted only the Irish general election and limited to one nation; only conducted sentiment analysis |
| Lee et al. (2020) | Total of 450 adults via email through an online survey in South Korea | Statistical analysis | How politicians’ Twitter blunders might affect individuals’ beliefs about the nature of Twitter communication, and subsequently, their reactions to other politicians’ tweets | Only conducted a statistical analysis; limited to one country |
| Rathnayaka & Rupasingha (2023) | Twitter data | SVM, ANN, and LSTM algorithms | Sentiment analysis on twitter data relevant to politics during COVID-19 | Only conducted sentiment analysis |
| Elghazaly et al. (2016) | Twitter data targeting presidential elections in Egypt | SVM and Naïve Bayesian algorithm | Political sentiment analysis using Twitter data | Limited to one election-related data and country; only conducted sentiment analysis |
| Bose et al. (2019) | Twitter messages related to recent 14th Gujarat Legislative Assembly Election | NRC Emotion Lexicon, ParallelDots AI APIs | Predicting the chances of winning party by utilizing public opinion | A few numbers of data used (1,000); only conducted an emotion analysis; limited to one country |
| Palmer (2021) | Through survey | Statistical models (regression analysis) | Measuring the political attitudes and behavior in a pandemic: factors affecting compliance with COVID-19 policies | Only conducted a statistical analysis; a few number of data used |
| Rieger & Wang (2022) | Online survey | Statistical analysis (structural equation model) | Study people’s perceptions of government reactions during the pandemic | Only conducted a statistical analysis |
| Purushothaman & Moolakkattu (2021) | Press reports and press releases by government agencies | A descriptive and analytical approach | Analysis of the politics of the COVID-19 pandemic in India | Only conducted a statistical analysis; limited to one country |
| Montiel et al. (2021) | Publicly available speeches | Principal component analysis, LDA algorithm | Maps political rhetoric by national leaders during the COVID‐19 pandemic | Research depends on the public speeches of the politicians |
| Wright et al. (2022) | Survey response data | LDA algorithm | Analyzing public opinion about the UK government during COVID-19 | Limited to one country |
| Yano et al. (2009) | Online political blog post | LDA algorithm | Predicting response to political blog posts with topic models | A few numbers of data; not relevant to the pandemic situation |
2.4. Research Gap
Considering the COVID-19 pandemic, we determine the most frequently discussed political themes on Twitter. The critical point is that we could not find any studies focused on the COVID-19 pandemic and political changes that applied a topic modeling approach to extract the relevant topics. The proposed approach is mainly targeted to fill this research gap. Some other relevant research is limited to one country and uses relatively small data sets. When considering the source of data acquisition, some studies collected data from weblogs, Google forms, and polls conducted in different countries. According to the literature, using public opinion platforms such as social media to get accurate ideas is better. It provides opportunities for learning about and comprehending people, their potential, hobbies, and viewpoints.
Due to the ease of obtaining and accessing data, attention has been drawn to Twitter. Hence, the study’s main focus was on the analysis of tweets using standard topic modeling methods. It is capable of correctly studying changes in politics during the COVID-19 epidemic. The literature-identified LDA and PLSA topic models were more efficient and accurate for the proposed approach. As a result, the entire globe has become the subject of research, obtaining data far more extensively than with prior data collection methods. LDA and PLSA algorithms are projected to discover these study fields.
3. METHODOLOGY
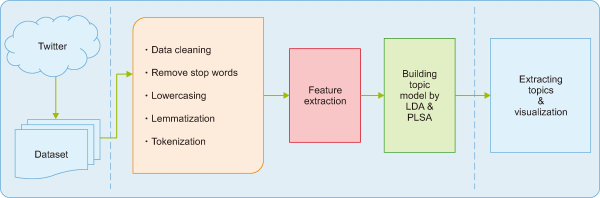
The primary objective of this research is to compare topic modeling strategies with their outcomes. We examine the research strategy, data collecting and pre-processing, feature extraction, and implementation of the data analysis method as part of the research methodology by topic modeling approach. Finally, topics are analyzed using two topic modeling approaches, LDA and PLSA. Fig. 2 explains the architecture of the proposed approach.
Fig. 2
Architecture of the proposed approach. LDA, latent Dirichlet allocation; PLSA, probabilistic latent semantic analysis.
3.1. Data Collection
Twitter social media was used to collect data relevant to the world’s political changes during the COVID-19 pandemic. Tweets were collected during March 2020 and December 2021, the peak period of the COVID-19 pandemic, and 10,658 tweets were collected through the Twitter application programming interface. First, a Twitter application development account was registered to scratch tweets from Twitter. In the Postman workspace, we made a fork through workspace and sent a fetch request to search the entire archive by providing values for several variables (query=COVID-19, political changes, date=20200301000, toDate=20200630000, and maxResults=100). Comma separated values formatting was used in the data set. Fig. 3 shows a portion of the data set. The keywords used are “COVID-19,” “Political changes,” and “Government decisions.” Data were downloaded in JavaScript Object Notation format by sending a fetch request. Our keywords were chosen to reflect a global focus rather than being specific to any particular country or region. However, the collection process was primarily focused on English-language tweets.

3.2. Data Pre-Process
Data pre-processing is modifying or removing data before use to ensure or improve performance. This phase of the data mining process is essential. The data was pre-processed using Python libraries with NLP techniques to prepare the data suitable for the analysis. First, we import some required libraries such as “re, pandas, numpy, gensim, spaCy, pyLDAvis.” These modules are available for performing text preprocessing, topic modeling, visualisation, and plotting tasks in the subsequent code. For example, spaCy and Natural Language Toolkit (NLTK) are NLP libraries that provide various functionalities, such as tokenization, part-of-speech (POS) tagging, and dependency parsing. Gensim is a popular Python library for topic modeling analysis. The NumPy library provides support for mathematical operations on arrays and matrices. pyLDAvis is used for visualization. After this, the following mandatory steps are proceeding.
3.2.1. Data Cleaning
This step aims to clean and normalize the text data in the “tweet” column by performing several pre-processing steps. Also, as this study considers tweets in the English language only, therefore we installed the “spaCy” NLP library that loaded a pre-trained English language model called “en_core_web_sm” and removed other language tweets from the data set.
3.2.2. Prepare the Stop Words
The NLTK library can retrieve a list of English stop words using the “stopwords.words(‘english’)” function call. It provides a collection of typical English terms. Stop words consist of pronouns and articles, including “the,” “is,” and “and.” The “stop_words.extend([...])” statement is used to add additional stop words to the existing list.
3.2.3. Lowercasing
This step is generally taken to strengthen the stability of text analysis. From Python, “text.lower()” converts all the uppercase letters in the text to lowercase.
3.2.4. Lemmatization
Lemmatization is the process of reducing words to their base or root forms (lemmas) to normalize the text. It involves removing the inflectional endings from the words and returning the base form of the word. It groups different forms of words as one single form of the word. By default, it keeps only nouns, adjectives, verbs, and adverbs. It uses the spaCy library to tokenize each sentence in the texts and then lemmatizes each token based on its POS tag (“allowed_postags=[‘NOUN’, ‘ADJ’, ‘VERB’, ‘ADV’]”).
3.2.5. Tokenization
Tokenization is the process of obtaining a token from tweets. At this point, a longer paragraph is converted to tokens. The example shows individual words separated by spaces in a text document, which are referred to as tokens. The NLTK library has a Tweet Tokenize module that can be used to extract tokens from tweets where all words are punctuated. Sentences are pre-processed using the “gensim.utils.simple_preprocess” function before being entered into the “sent_to_words” function. The “deacc=True” argument is given to the simple pre-process method to ensure that punctuation marks are removed from the tokens. The following Table 2 explains the example tweet for the above pre-processing steps.
Table 2
Example for pre-processing steps
| Example | |
|---|---|
| Tweet before the preprocess | @WhiteHouse @realDonaldTrump This is what a responsible government official says:Gov. Ralph Northam of Virginia on his decision to issue a stay-at-home order for the state. He’s making his decisions on the response to Covid-19 based on science and data |
| Data cleaning | WhiteHouse realDonaldTrump This is what a responsible government official says Gov Ralph Northam of Virginia on his decision to issue a stay at home order for the state making his decisions on the response to COVID 19 based on science and data |
| Prepare the stop words | WhiteHouse realDonaldTrump This what responsible government official says Gov Ralph Northam Virginia his decision issue stay home order state making his decisions response COVID 19 based science data |
| Lowercase | whitehouse realdonaldtrump this what responsible government official says gov ralph northam virginia his decision issue stay home order state making his decisions response covid 19 based science data |
| Lemmatization | whitehouse realdonaldtrump responsible government official say decision issue stay home order state make decision response covid base science data |
| Tokenization | [“whitehouse” “realdonaldtrump” “responsible” “government” “official” ‘say” “decision” “issue” “stay” “home” “order” “state” “make” “decision” “response” “covid” “base” “science” “data”] |
3.3. Feature Extraction
Feature extraction in the LDA topic model is the process of identifying the most important words or phrases for a better understanding of the context (Blei et al., 2003). After cleaning and normalizing the data, we need to convert it into numerical representations for modeling: that is, converting unstructured data into a structured numerical format. This study used Bow to convert into a numerical representation. The bag-of-words model is a way of representing modeling text with algorithms. The code “[id2word.doc2bow (text) for text in texts]” represents this process. The “doc2bow” counts the occurrence frequencies of each distinct word, and “id2word” maps the word_id to a unique word in the corpus using the Gensim library.
3.4. Applying Topic Models
To identify the key themes and topics about political behavior that occurred during the COVID-19 pandemic, this study used LDA and PLSA topic modeling analysis. PLSA and LDA are both topic modeling algorithms used to analyze large collections of documents. The analysis will highlight the most significant changes in political speech as well as people’s opinions on these changes. Here, we examine which method of analysis provided the most accurate information.
The existing techniques, LDA and PLSA, were used to obtain more accurate results effectively and efficiently. The literature-identified LDA and PLSA topic models were more efficient and accurate than other methods for the proposed approach. They are successful methods, and each document is viewed as a mix of multiple distinct topics. The advantage of the LDA technique is that one does not have to know in advance what the topics will look like. LDA automatically provides topics based on patterns in the data. PLSA provides a clear probabilistic interpretation of the relationship between documents and topics. The proposed approach primarily relies on such established techniques such as LDA and PLSA when considering these advantages.
3.4.1. LDA Topic Modeling
LDA is a topic modeling technique that represents the relationship between multiple documents in a corpus. This technique allows a set of observations to be explained by unobserved groups that define why some parts of the data are similar (Alamoodi et al., 2022). It uses a Bayesian approach and assumes a Dirichlet prior over the topic distributions. Fig. 4 shows the algorithm.
Fig. 4
Latent Dirichlet allocation algorithm. M, number of documents in the corpus; N, number of words in the document; α, Dirichlet parameter (controls per-document topic distribution); θm, document topic distribution; Zm,n, word topic assignment; Wm,n, observed word; φk, topic-word distribution; β, Dirichlet parameter (controls per-topic word distribution).
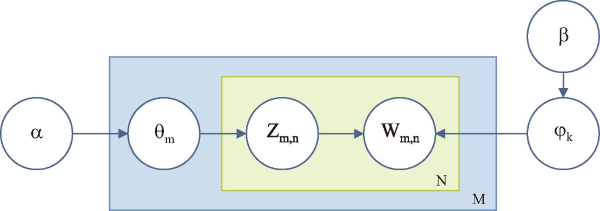
The variable names are defined as,
M is the number of documents in the corpus.
N is the number of words in the document.
K is the number of topics.
α is Dirichlet parameter (controls per-document topic distribution).
θm is document topic distribution.
Zm,n is word topic assignment.
Wm,n is observed word.
φk is topic-word distribution.
β is Dirichlet parameter (controls per-topic word distribution).
LDA estimates the proportion of words in a document assigned to a certain topic, and then finds the fraction of words assigned to a topic across all texts. These themes are then qualitatively examined to validate their content relevance.
3.4.2. PLSA Topic Modeling
PLSA is a generative model that assumes each document is formed from a mixture of latent themes. Each word in a document is generated with a specific probability by one of these topics. PLSA aims to estimate the probability distributions for each document’s subjects and terms. It is a topic modeling technique for data analysis with applications in information retrieval and filtering, NLP, machine learning from text, and other fields. The PLSA algorithm generated hidden topics based on the importance of words and the similarity of topics in a document (Khotimah & Sarno, 2019). Fig. 5 shows the algorithm.
Fig. 5
Probabilistic latent semantic analysis algorithm. d, number of documents in the corpus; w, number of words in the document; z, number of topics; P(d), probability of selecting a specific document (d) from the entire document collection; P(z/d), topic (z) is present in the selected document (d) with probability; P(w/d) is word (w) is drawn from the topic (z) with probability in a given topic.
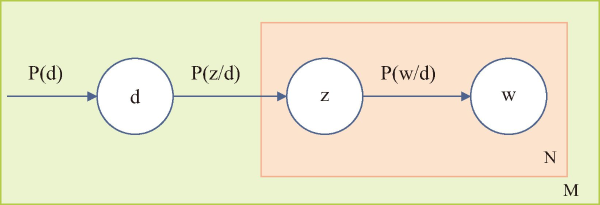
The variable names are defined as,
d is number of documents in the corpus.
w is number of words in the document.
z is number of topics.
P(z/d) is topic (z) is present in the selected document (d) with probability.
P(w/d) is word (w) is drawn from the topic (z) with probability in a given topic.
4. RESULTS AND DISCUSSION
Here, we discuss the extracted topics relevant to the political changes in the COVID-19 pandemic using topic modeling techniques. This evaluation used Microsoft Windows 10 Pro (Microsoft Corp. Redmond, WA, USA) on a personal computer with an Intel(R) Core(TM) i5-4590 CPU @ 3.30GHz, 4 Core(s) Processor, and 8GB RAM. Python was used as a programming language to implement topic modeling algorithms.
4.1. LDA Visualization Analysis
The LDA visualization analysis used the “LDAvis” R package (Sievert & Shirley, 2014) for the visualization, which is intended to explore LDA topic models by varying the weights of top-ranked topic words. Inter-topic distance map is a web-based interactive visual representation of topics computed using LDA. This is the most often used visualizing library.
The topics are plotted on an inter-topic distance map by default; the x and y axes here are labeled “PC1” and “PC2” (principal components 1 and 2). Fig. 6 shows that 15 topics were chosen, and bubbles represented the topics with their frequencies. The size of each bubble indicates the frequency of that topic, and the distance between the bubbles reflects the semantic similarity between topics. The topic format will be successful if it uses large, evenly-spaced bubbles that do not overlap. Fig. 6 shows that topics 2, 7, 9, and 15 are clustered independently, and others overlap event topics. In considering overlapping topics, some keywords are commonly used for each overlapping topics. For example, “covid” and “government” keywords are common to topics no. 10, 11, and 14. However, those clusters cover specific topics, and they are clusters of mutually distinct topics.
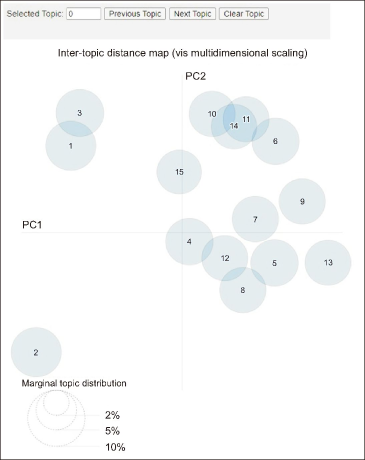
Fig. 7 shows the 30 most relevant terms and ranks them in order of relevance from top to bottom and fills the bar chart. Considering the keywords shown in LDAvis, the words with the highest frequency are “good,” “decisions,” “make,” “look,” “covid,” “trackle,” “people,” “inquiry,” “add,” and “vaccine.”

Fig. 8 (Sievert & Shirley, 2014) shows the interaction of left and right sides in the inter-topic distance map. For example, when topic number 10 is selected in the right panel, the left panel terms with their frequencies are represented by red bars. Primarily, LDAvis enables one to choose a topic and display the most relevant keywords for that topic. Relevance is defined by λ, which is the weight assigned to the probability of the term in a topic relative to its lift. The value is intended between 0 and 1. When λ=1, terms are ranked according to their probabilities inside the topic, whereas when λ=0, terms are re-ranked solely according to their lift; Sievert and Shirley (2014) realized that λ=0.6 was the optimum interpretable result.
Fig. 8
How the inter-topic distance map is displayed when the topic is selected. 1. Saliency(term w)=frequency(w)×[sum_t p(t|w)×log(p(t|w)/p(t))] for topics t. 2. Relevance(term w|topic t)=λ×p(w|t)+(1-λ)×p(w|t)/p(w); data from the article of Sievert & Shirley (2014).

4.2. LDA Topic Analysis
LDA assumes that each document is composed of a distribution of topics, and each topic is composed of a distribution of words. The task of this LDA algorithm is to build the hidden topic (“latent”). Table 3 presents the topics and keywords of tweets in each topic produced from 10,792 tweets. When considering Table 3, the study identified the five key themes and 15 topics about political behavior that occurred during the COVID-19 pandemic. “No” in Table 3 represents the relevant cluster numbers in the Inter-topic distance map in Fig. 6.
Table 3
Topics and themes generated through LDA
| No. | Topic | Keywords | Example Tweet |
|---|---|---|---|
| Theme 1: Government Responses for Managing the COVID-19 Pandemic | |||
| 1 | The travel mandates | “decision,” “government,” “follow,” “information,” “let,” “mandate,” “travel,” “allow,” “guideline” | “Updated information on Covid-19 vaccine mandates” |
| 4 | Ensuring public safety and the federal government | “good,” “government,” “state,” “federal,” “safe,” “require, “guideline’, “meet,” “covid” | “With the federal government handing off decisions, states have been the primary drivers behind moves with the most impact on the pandemic’s spread” |
| 11 | Enforcing regulations to manage the spreading of the virus | “government,” “covid,” “spread,” “stop,” “protect,” “rule,” “prevent,” “community,” “responsible,” “disease,” “affect” | “A citizen while we appreciate the government for trying very hard to stop the spread of Covid-19” |
| 14 | Efforts to control the spreading | “government,” “get,” “covid,” “measure,” “come,” “number,” “big,” “result,” “suffer,” “handle” | “Statement on the provincial government’s announcement today regarding additional Covid-19 public health measures” |
| Theme 2: Government decisions for COVID-19 | |||
| 3 | The decision to take control spreading of the virus | “decision,” “government,” “take,” “level,” “control,” “never,” “close,” “cover,” “decide” | “Governments on all levels are either unable to make the necessary decisions needed to control Covid-19” |
| 6 | Real-time monitoring of the situation | “covid,” “suggest,” “government,” “pandemic,” “case,” “watch,” “coronavirus,” “important,” “action,” “priority” | “The well worth watching particularly if you are questioning Government decisions and Covid-19 cases” |
| 10 | Testing and hospital capacity | “covid,” “government,” “bad,”, “death,” “hospital,” “virus,” “high,” “testing,” “staff,” “capacity,” “daily,” “threaten” | “As if the first two waves of Covid-19 hospitalizations in the USA weren’t enough to inspire serious political changes to stop the coronavirus” |
| Theme 3: Public Response to Government Measures for COVID-19 | |||
| 5 | COVID-19 testing and public response | “provide,” “help,” “test,” “report,” “response,” “covid,” “policy,” “datum,” “low” | “All our winter events will continue as planned, Covid-19 testing government guideline s and the Good To Go Covid-19 industry standard” |
| 7 | Issues, changes, and guidelines on public health | “change,” “regard,” “covid,” “issue,” “guidance,” “government,” “update,” “stay,” “social,” “post” | “Warns some against taking the vaccine. The key issue now is our regime restrictions tight enough to reduce the spread of infection. Some very tough decisions needed” |
| Theme 4: Social Influence | |||
| 8 | A new lifestyle with pandemic | “go,” “think,” “time,” “job,” “thing,” “life,” “start,” “really,” “live,” “try” | “It is absolutely true that Covid-19 has changed the lifestyle of many people all over the world. Along with human beings, animals suffer a lot due to this virus” |
| 9 | Economic changes | “covid,” “country,” “effect,” “business,” “support,” “lockdown,” “idea,” “restriction,” “economic,” “strategy” | “As a result of the Covid-19 lockdowns, numerous social and economic changes were intended! Consider the upward transfer of wealth and market share to Big Business since the start of the Covid-19 pandemic” |
| 12 | Leadership, media influence on increasing public health | “people,” “need,” “home,” “care,” “leader,” “news,” “point,” “question,” “risk,” “mask,” “wear” | “CTV NEWS: Civil society leaders call for evidence-based decisions for public health” |
| 15 | Effect of the education section | “tackle,” “government,” “see,” “new,” “school,” “student,” “rate,” “place,” “learn,” “reopen” | “Working fewer hours, concentrating on things we need more, E-learning, most will discover their potential and talents” |
| Theme 5: Vaccination | |||
| 2 | Global vaccine demand, failures, and distribution inequity | “inquiry,” “vaccine,” “health,” “public,” “failure,” “demand,” “repercussion,” “globally,” “inequity,” “service,” “immediate,” “safety” | “Join us in demanding that the Covid-19 inquiry looks at the government’s failure to tackle vaccine inequity globally, and the repercussions of these decisions on public health! because very immediate need to respond to the pandemic” |
| 13 | Role of experts and politics vaccination | “covid,” “give,” “vaccination,” “expert,” “political,” “share,” “medical,” “vaccinate,” “dose,” “critical,” “mandatory,” “relate” | “Government isn’t going to listen to an expert’s opinions about Covid-19 and vaccination!” |
As shown in the following Table 3, we defined and interpreted the five theme findings. These five themes are defined based on the results of the inter-topic distance map in Fig. 8 (Sievert & Shirley, 2014).
In Fig. 8 (Sievert & Shirley, 2014),
-
- 15 circles on the left side - 15 extracted topics from the LDA model.
-
- 30 terms on the right side - Set 30 keywords for the selected topic. Here we selected Topic 10 (highlighted in red color).
Fig. 8 (Sievert & Shirley, 2014) visualizes the relevant set of 30 keywords for each topic. Among the 30 keywords, the lengthy red bars at the top show the top keywords for the selected topic [in Fig. 8 (Sievert & Shirley, 2014), selected topic 10]. Based on these top keywords, we manually decided on the name for that topic based on expert knowledge and feedback.
As shown in Fig. 8 (Sievert & Shirley, 2014), we extracted 15 topics, and considering all the extracted 15 topics, we divided them into five themes manually based on expert knowledge and feedback. The decided themes are ‘Government Responses for Managing the COVID-19 Pandemic,’ ‘Government Decisions for COVID-19,’ ‘Public Response to Government Measures for COVID-19,’ ‘Social Influence,’ and ‘Vaccination.’ Considering the visualization of LDA and PLSA, as well as feedback from experts and knowledge from relevant authorities and government agencies, we decided that the themes are accurate and meaningful.
4.2.1. Theme 1: Government Responses for Managing the COVID-19 Pandemic
The first theme began with the government’s response to managing the COVID-19 pandemic. It focuses on the various measures, strategies, and actions that governments around the world have taken to address the challenges posed by the COVID-19 pandemic. This theme focuses on the impact of the following four topics.
4.2.1.1. Travel Mandates.
During the pandemic, travel mandates were one of the successful methods used to minimize the spreading of the virus. Quarantine requirements, mandates to obtain vaccination doses, lockdowns and shutdowns of countries, and foreign travel restrictions are the methods governments use to manage the movement of people and reduce the spread of infectious diseases.
4.2.1.2. Ensuring Public Safety and the Federal Government.
Public safety and the federal government were significant in that time period. The federal government is a general government concept practised in some countries where different powers are divided at different levels. Accordingly, it refers to the government’s process of establishing public health.
4.2.1.3. Enforcing Regulations to Manage the Spreading of the Virus.
The COVID-19 pandemic has significantly affected society worldwide, requiring governments to take proactive measures to minimize the spread of the virus.
4.2.1.4. Efforts to Control Spreading.
Government actions and measures are important in addressing the global crisis of the COVID-19 pandemic. The implementation of public health strategies, data tracking and reporting, and effective response to emergencies can be identified as part of governments’ efforts.
4.2.2. Theme 2: Government Decisions for COVID-19
Governments are entrusted with making decisions that affect the welfare and stability of a nation. This theme delves into the specific policy decisions made by governments in response to the COVID-19 pandemic. As part of this, we discussed how governments determine their strategy for COVID-19 testing and hospital capacity. Governments must stay updated about the state of the pandemic and adapt their strategies accordingly. This theme focuses on the impact of the following three topics.
4.2.2.1. The Decision to Take Control of the Spreading of the Virus.
Governments on all levels must be able to make the necessary decisions needed to control COVID-19. Authorities need to be effective in making decisions; otherwise, it will cause public displeasure.
4.2.2.2. Real-Time Monitoring of the Situation.
The word “today” indicates the need for real-time monitoring and rapid response to the evolving situation. Governments must stay updated about the state of the pandemic and adapt their strategies accordingly.
4.2.2.3. Testing and Hospital Capacity.
This theme focuses on a government’s decisions regarding COVID-19 testing and hospital capacity. Testing can be helpful to minimize the risk of spreading COVID-19 to others. There are two main types of viral tests: The first one is polymerase chain reaction testing and another one is antigen testing. Governments often make important decisions regarding testing protocols, procedures, and accessibility.
4.2.3. Theme 3: Public Response to Government Measures for COVID-19
Resources influence the ability of governments to provide assistance as well as their responsiveness to public needs and the public’s trust, compliance, and overall response to the measures implemented. Effective communication is responsible for dispelling misinformation and building trust. This theme focuses on the impact of the following two topics.
4.2.3.1. COVID-19 Testing and Public Response.
The keywords “provision,” “assistance,” “response,” “covid,” and “policy” are interrelated in understanding the public response to government actions regarding COVID-19. Resources influence the ability of governments to provide assistance as well as their responsiveness to public needs and the public’s trust, compliance, and overall response to the measures implemented. Effective communication is responsible for dispelling misinformation, building trust, monitoring mortality and infection rates, and reporting results.
4.2.4. Theme 4: Social Influence
The social influence of the COVID-19 pandemic is enormous. It has perhaps changed daily life, the economy, and education widely. However, leadership, social, and public media have had a critical role in sharing pandemic-related information and ensuring public health. This theme focuses on the impact of the following four topics.
4.2.4.1. A New Lifestyle with the Pandemic.
The impact of the COVID-19 pandemic has led to lifestyle changes. Wearing surgical masks, washing hands, and other options to reduce the spread of the virus are some occasions that presented lifestyle behavioral changes.
4.2.4.2. Economic Changes.
“Economic” represents the economy of the country, and the keywords “business” and “education” represent important sectors of the economy. This highlights how governments implement restrictions and lockdown measures directly affecting businesses, such as supply chain disruptions and economic downturns. Elsewhere, businesses have adapted to the new normal, such as transitioning to e-commerce, contactless delivery, and virtual services. This all effected to drive economic growth.
4.2.4.3. Leadership and Media Influence for Increasing Public Health.
The “News” keyword references public media activities. Social media and public media have become critical features for sharing information and engaging in the decisions made by respective governments regarding pandemic-related measures and public health.
4.2.5. Theme 5: Vaccination
This discussion highlighted the importance of fair access to COVID-19 vaccines and the challenges faced in global vaccination efforts. It emphasizes medical professionals’ and political leaders’ partnerships to navigate medical guidance and government challenges. This theme focuses on the impact of the following two topics.
4.2.5.1. Global Vaccine Demand, Failures, and Distribution Inequity.
There is an inequality in global vaccine demand and distribution. The focus is on the efforts made by governments worldwide and the challenges they face in tackling the COVID-19 pandemic through vaccination strategies. This involves discussing failures and emphasizing the need for more effective approaches to ensure equitable access to vaccines globally.
4.2.5.2. Role of Experts and Politics in Vaccination.
This topic emphasizes balancing the challenges of medical guidance and government. The COVID-19 vaccination campaign highlights the importance of maintaining a strong partnership between medical experts and political leaders.
Through this analysis, policies and measures taken to control the spread of the epidemic and ensure public health protection have been discussed as possible factors for political change during the COVID-19 epidemic. Examples include lockdowns, travel restrictions, vaccinations, and health precautions. As well, the underlying themes and topics that have been discussed on Twitter about the decisions taken by governments and the reactions given by citizens when they are implemented, as well as the trends that have occurred in society due to the COVID-19 epidemic, are revealed.
4.3. PLSA Topic Analysis
Considering the topic of the PLAS model, the model we generated 25 topics, and Table 4 shows a list of topics along with their corresponding probabilities in order from highest to lowest. Each topic represents a specific theme or concept, and the probability indicates the likelihood of that topic being present in a given dataset or document. These topics do not give an exact meaning to the dataset. However, this is based solely on the given word probabilities.
Table 4
Relevant words from the PLSA
| Probabilistic latent semantic analysis (PLSA) | |||
|---|---|---|---|
| Topic | Probability | Topic | Probability |
| ‘regulation’ | 0.0386 | ‘supplier’ | 0.0126 |
| ‘stage’ | 0.0385 | ‘conflict’ | 0.0113 |
| ‘distancing’ | 0.0361 | ‘politics’ | 0.0112 |
| ‘launch’ | 0.0351 | ‘covid’ | 0.0109 |
| ‘midnight’ | 0.0341 | ‘bill’ | 0.0100 |
| ‘update’ | 0.0271 | ‘find’ | 0.0100 |
| ‘stay’ | 0.0236 | ‘http’ | 0.0098 |
| ‘hey’ | 0.0189 | ‘lack’ | 0.0083 |
| ‘documentation’ | 0.0177 | ‘interest’ | 0.0081 |
| ‘store’ | 0.0158 | ‘thanks’ | 0.0074 |
| ‘procurement’ | 0.0137 | ‘news’ | 0.0076 |
| ‘contract’ | 0.0132 | ‘transparency’ | 0.0071 |
| ‘report’ | 0.0129 | ||
The most frequent topics are “stay,” “covid,” and “news,” highlighting the section on health during the COVID-19 pandemic. “Transparency,” “regulation,” “procurement,” “conflict,” and “politics” are keywords that refer to the political content of this data set. Others do not convey a specific meaning relating to our objectives. Most of them are verbs that are related to health protection. This means a significant portion of the analyzed data includes health concerns.
4.4. Word Cloud Visualization
The word cloud library is used here to illustrate the data visualization of pre-processed text from the data set. Words are arranged in no particular order, and the library randomly assigns colors to each word and visualizes word frequency and importance within a given text. Large words appear more frequently in the dataset, while smaller ones appear less often.
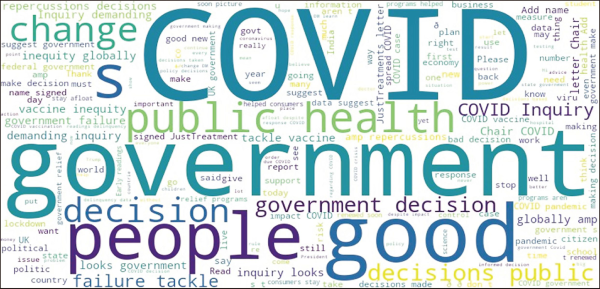
An overview of the 15 topics that the study generated is represented in Fig. 9. The size of each word reflects its frequency or importance within the corresponding topic. For example, the prominent words might include “covid,” “suggest,” “say,” “good,” “think,” “go,” “country,” “give,” “trust,” “due,” and “change.” The word cloud provides an overview but does not convey detailed insights.

According to Fig. 10, “government,” “covid,” “good,” “people,” “say,” “public,” “health,” and “decision” words are typically the larger words and are prominently shown rather than, “make,” “change,” “go,” “failure,” “tackle,” “look,” “demand,” “globally,” and “vaccine” words are prominently shown. Word clouds may not provide detailed information on word relationships, and they may not provide deep meaning to the dataset.
4.5. Analyzing the Results of Topic Modeling
Topic model evaluation determines how well a topic model performs its intended function. It is important to determine how well it performs the task for which it was created. When the topic model is used for a quantifiable goal, like classification, it is relatively easy to determine how effective the model is. However, evaluation is more challenging if the model is applied to a more qualitative task, such as examining the semantic themes in an unstructured corpus. Here, we evaluate the topic models using the coherence and Kullback-Leibler divergence (KL) scores.
4.5.1. Coherence Score
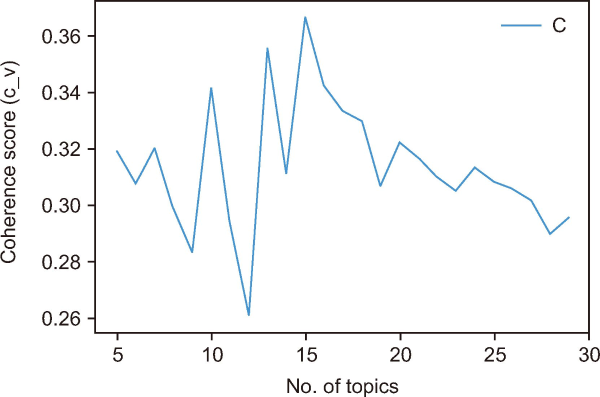
By calculating the degree of semantic similarity between high scoring terms in the topic, Topic Coherence measures the score of a single topic (Kapadia, 2019). These metrics help distinguish themes that can be understood semantically from topics that are the result of statistical inference. Among the different coherence measures, this study is based on the C_v measure. This measure builds word content vectors based on their co-occurrences and then determines the score using cosine similarity and normalized pointwise mutual information. The range from 0 to 1 is the C_v coherence score. Fig. 11 shows a graphical representation of the measurement of coherence scores. Higher scores of coherences are always better. This study identified that the optimal number of topics is 15, and its coherence value is 0.37.
4.5.2. Kullback-Leibler Divergence Score
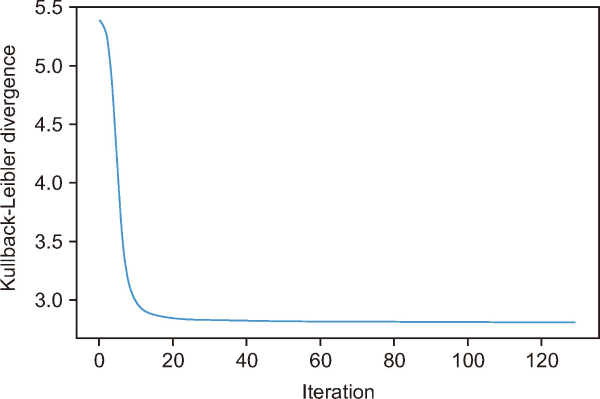
The KL score, often known as the KL score (Heimel, n.d.), measures how different two probability distributions are from one another. KL divergence is a non-negative measure of the difference between two different probability distributions. When approximating a distribution, we can try KL divergence to reduce information loss (Avanesov & Kozlov, 2014).
The KL divergence is on a downward trend in Fig. 12, and the method is getting closer to its goal of minimizing the variance between the distributions. PLSA is hard to train, and this model is based on an extensive collection of documents. Therefore, we can use KL divergence to improve the time efficiency of the training algorithm. The curve’s points represent the KL divergence values at particular iterations. Based on the lowest KL divergence attained, the optimal model can be chosen based on the KL divergence’s stabilization. For instance, the KL divergence is 5.4 in the first iteration (y=0). Indicating that the distributions are becoming more similar or aligned, the KL divergence reduces throughout the course of repetitions.
Here, the coherence and KL scores are used to measure the “optimal number of topics” for the topic models. In this case, we selected 15 topics belonging to the values with the highest coherence score probability for the LDA, and the lowest score iteration was used, and 25 topics were selected in PLSA.
4.6. Discussion
When discussing the significance of our research findings in comparison to previous studies, the key point is that we were unable to find any prior research that specifically focused on the political changes during the COVID-19 pandemic using a topic modeling approach to extract relevant topics. However, when considering some relevant studies, they are limited to one country and use relatively small data sets. Also, those studies used some Google forms, interviews, discussions, weblogs, or poll data instead of social media data. This proposed approach filled this research gap. The proposed approach used global data targeting the whole world; the data set is relatively large and successfully utilized both LDA and PLSA results for comparison. Moreover, Twitter data was more reliable for this kind of approach since people share their opinions on the platform freely and publicly. Therefore, when comparing the existing studies, the results of the proposed approach are significant and valuable for making more accurate decisions, ideas, and solutions for any relevant issues.
In this study, we extracted the main topics relevant to political changes during COVID-19 using a topic modeling approach. The topics that were identified as being related to political changes during the COVID-19 pandemic are explained in Table 3 and Table 4. As a result, 15 topics under five themes were identified using LDA (Table 3), and 25 topics were extracted through PLSA (Table 4). In order to identify topics, we used the most relevant keywords from each topic. For instance, consider topic no. 1, ‘The travel mandates’ in Table 3, where the keyword “travel” pertains to transportation. The keywords “government,” “follow,” “information,” “mandate,” and “guideline” act as a reminder of the rules and guidances to follow during the pandemic situation. On the other hand, the words “let” and “allow” imply restrictions on travelling. These kinds of suggestions are based on the topics and keywords in Table 3 and Table 4.
When comparing topic modeling approaches, LDA provided more accurate and coherent topics than PLSA. LDA is a valuable tool for comprehending the main discussions and trends surrounding political proceedings for health during the pandemic, as it provides a set of topics represented by their most probable words and their distribution across documents.
Important points excerpted from the Twitter data are that political authorities had to deal with many challenges and concerns brought on by the COVID-19 pandemic, and the focus was on the healthcare industry, which is grappling with the massive issues caused by the virus. The adoption of measures to prevent the spread of the virus and reduce its possible effects on individuals and communities depended heavily on political authorities. Addressing several issues, including virus detection and testing, manipulating vaccines, and healthcare infrastructure, has been given priority. In the discussion of the control of the spread of the virus, themes were cited along two lines: the effort to control the spread and the decision to control the spread of the virus. However, the adoption of decisions to prevent the spread of the virus and reduce its possible effects on individuals and communities depended heavily on political authorities.
Another concern is media influence and their leading actions to improve public health, affection of the economic and education sectors, lockdowns and travel restrictions, and how those issues have changed people’s lifestyles, which frequently came into the discussion. Many users expressed doubts about the necessity and efficacy of these policies, as well as worried about how they might affect the economy and personal freedoms. Users discussed news, facts, and personal experiences about vaccination programs, marketing tactics, and vaccine reluctance. They also conferred with the experts to give their opinions about the significance of vaccination.
The online discussion regarding government decision-making regarding the process of vaccination highlighted the difficulty of managing a public health emergency and the significance of incorporating the general public into the decision-making process. Accordingly, those discussions were highlighted during the pandemic period and the proposed approach successfully extracted and finalized them under the different topics and themes.
4.6.1. Limitations of the Study
The study is constrained by Twitter data’s inherent biases, which may not represent the broader public opinion due to demographic, geographic, and technical limitations. The findings reflect only the specific data collection period and may not capture the evolving political landscape. The dynamic nature of Twitter data also means that the findings are temporally limited and may not account for rapid changes in public discourse.
Language and cultural context are significant challenges, as the analysis might need to fully account for the nuances of multiple languages, dialects, or unique cultural expressions. Additionally, the research relies on the accuracy of NLP techniques, which can be impacted by the informal language, abbreviations, and slang commonly used on social media platforms. Furthermore, the study’s scope is restricted to textual data, potentially overlooking multimodal content like images, symbols, and videos, which could provide a fuller understanding of political sentiment and discussions.
5. CONCLUSION
Identifying the main topics discussed related to political changes during the COVID-19 period is essential. Therefore, this study aimed to identify the most frequently discussed topics related to politics during the COVID-19 pandemic using the topic modeling approaches. This study analyzed 10,658 political tweets during COVID-19 and political changes using Twitter between March 2020 and December 2021, applying LDA and PLSA topic modeling approaches. Both LDA and PLSA provided valuable insights into the latent topics present in the data, allowing us to understand the main discussions and trends related to political proceedings for health during the pandemic.
Through a comparative evaluation of the LDA and PLSA topic modeling techniques, we identified LDA as the superior method providing more accurate and coherent results. It helped to create a comprehensive explanation of the topics. It provided a set of topics represented by the most probabilistic words and the distribution of that topic across the documents. The adoption of measures to prevent the spread of the virus and reduce its possible effects on individuals and communities depended heavily on political authorities. Lockdowns, travel restrictions, governmental decision-making, vaccination and health measures, and lockdowns are some of the main topics of conversations on Twitter. Political authorities had to deal with several challenges and concerns brought on by the COVID-19 pandemic. Here, the focus was on the healthcare industry, which is grappling with the massive issues caused by the virus. The adoption of measures to prevent the spread of the virus and reduce its possible effects on individuals and communities depended heavily on political authorities.
Addressing several issues, including testing capacity, vaccine delivery, and healthcare infrastructure, has been given priority. Lockdowns and travel restrictions frequently came into the discussion. Political leaders’ judgments on the duration, severity, and application of lockdowns were strongly criticized on the platform. The online debates surrounding travel bans, lockdowns, and government decision-making highlighted the difficulty in handling a public health emergency and the value of incorporating the general public into the decision-making process.
Twitter provided a platform for citizens to voice their opinions and hold political leaders accountable for their actions. Government decision-making processes also drew attention to this activity, with users on Twitter expressing both support and criticism for how leaders handled the pandemic. The knowledge from this research can be applied to similar pandemic situations to guide practical political behavior by the relevant political parties.
6. FUTURE WORK
In the future, we plan to introduce novel, innovative methods under the methodology section instead of using an existing methodology. This will help us to conduct an in-depth analysis of these topics without relying on the existing LDA and PLSA models. To further expand the data efficiently by using different data sources and different deep learning algorithms, we plan to apply a sentiment analysis approach to categorize the data.
The topic modeling research methodology contains some limitations, such as its lack of contextual understanding and the risk of overuse. It is crucial to delve into alternative strategies to address these challenges. As a solution for this, combining traditional topic modeling with artificial intelligence (AI)-based methods will help to improve interpretability and performance. For instance, integrating AI techniques can enhance topic modeling, revealing deeper and more subtle insights within textual data. Therefore, we plan to incorporate AI-based technologies with this topic modeling approach to improve the results in a future study. Furthermore, images, symbols, and videos, which could provide a fuller understanding of political sentiment, are planned to be integrated with textual data in future studies to gain a better understanding of opinions compared to the current study. These advancements will allow for a more detailed understanding of public sentiment, opinions, and reactions during pandemics, providing valuable insights for policymakers to make informed decisions in the future.
REFERENCES
, , , , , , , , , , (2022) Public sentiment analysis and topic modeling regarding COVID-19's three waves of total lockdown: A case study on movement control order in Malaysia KSII Transactions on Internet and Information Systems, 16, 2169-2190 https://doi.org/10.3837/tiis.2022.07.003.
, , (2003) Latent dirichlet allocation Journal of Machine Learning Research, 3, 993-1022 https://dl.acm.org/doi/10.5555/944919.944937.
, (2022) Dynamic topic modeling of Twitter data during the COVID-19 pandemic PLoS One, 17, e0268669 https://doi.org/10.1371/journal.pone.0268669. Article Id (pmcid)
(2021) Topic modeling with LSA, PLSA, LDA & lda2Vec https://nanonets.com/blog/topic-modeling-with-lsa-plsa-lda-lda2vec/
, , , , (2016) Big social data analytics in journalism and mass communication: Comparing dictionary-based text analysis and unsupervised topic modeling Journalism & Mass Communication Quarterly, 93, 332-359 https://doi.org/10.1177/1077699016639231.
(n.d.) plsa.visualize module https://probabilistic-latent-semantic-analysis.readthedocs.io/en/latest/plsa.visualize.html
, (2012) Social media and political change: Capacity, constraint, and consequence Journal of Communication, 62, 359-362 https://doi.org/10.1111/j.1460-2466.2012.01626.x.
, , , (2023) Understanding researchers' Twitter uptake, activity and popularity-An analysis of applied research in Germany Scientometrics, 128, 325-344 https://doi.org/10.1007/s11192-022-04569-2.
(2019) Evaluate topic models: Latent dirichlet allocation (LDA) https://medium.com/towards-data-science/evaluate-topic-model-in-python-latent-dirichlet-allocation-lda-7d57484bb5d0
, , (2020) Is the message the medium? How politicians' Twitter blunders affect perceived authenticity of Twitter communication Computers in Human Behavior, 104, 106188 https://doi.org/10.1016/j.chb.2019.106188.
(2021) Editorial: History, lessons, and ways forward from the COVID-19 pandemic International Journal of Quality and Innovation, 5, 101-108 https://www.inderscience.com/info/dl.php?filename=2021/ijqi-7348.pdf.
(2020) COVID-19 and the politics of crisis International Organization, 74, E98-E127 https://doi.org/10.1017/S0020818320000375.
, , (2011) Investigating task performance of probabilistic topic models: An empirical study of PLSA and LDA Information Retrieval, 14, 178-203 https://doi.org/10.1007/s10791-010-9141-9.
, , , , (2022) Social media analytics system for action inspection on social networks Social Network Analysis and Mining, 12, 33 https://doi.org/10.1007/s13278-021-00853-w. Article Id (pmcid)
(n.d.) Topic modelling techniques in NLP https://iq.opengenus.org/topic-modelling-techniques/
, , , , (2017) Opinion mining using Twitter feeds for political analysis International Journal of Computer, 25, 116-123 https://ijcjournal.org/index.php/InternationalJournalOfComputer/article/view/929.
, , (2021) The language of pandemic leaderships: Mapping political rhetoric during the COVID-19 outbreak Political Psychology, 42, 747-766 https://doi.org/10.1111/pops.12753. Article Id (pmcid)
, (2018) Statistical inference of political spaces https://ec.europa.eu/research/participants/documents/downloadPublic?documentIds=080166e5bbe1d647&appId=PPGMS
(2021) Introducing the new academic research product track https://devcommunity.x.com/t/introducing-the-new-academic-research-product-track/148632/1
, (2022, February 23-24) Proceedings of the 2nd International Conference on Advanced Research in Computing IEEE Sentiment analysis of social media data using fuzzy-rough set classifier for the prediction of the presidential election, 188-193, https://doi.org/10.1109/ICARC54489.2022.9754173
, (2021) The politics of the COVID-19 pandemic in India Social Sciences, 10, 381 https://doi.org/10.3390/socsci10100381.
, (2023) Management lessons from impact of Covid-19 on political changes: Sentiment analysis using Twitter data IUP Journal of Management Research, 22, 5-27 https://iupindia.in/ViewArticleDetails.asp?ArticleID=6784.
, (2022) Trust in government actions during the COVID-19 crisis Social Indicators Research, 159, 967-989 https://doi.org/10.1007/s11205-021-02772-x. Article Id (pmcid)
World Health Organization (n.d.) Coronavirus disease (COVID-19) https://www.who.int/emergencies/diseases/novel-coronavirus-2019
, , , , (2022) Public opinion about the UK government during COVID-19 and implications for public health: A topic modeling analysis of open-ended survey response data PLoS One, 17, e0264134 https://doi.org/10.1371/journal.pone.0264134. Article Id (pmcid)
- Submission Date
- 2024-01-18
- Revised Date
- 2024-09-19
- Accepted Date
- 2024-10-15