JOURNAL OF INFORMATION SCIENCE THEORY AND PRACTICE
- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

Discovery Layer in Library Retrieval: VuFind as an Open Source Service for Academic Libraries in Developing Countries

Parthasarathi Mukhopadhyay (Department of Library & Information Science, University of Kalyani, West Bengal, India)
Anirban Biswas (University of North Bengal, West Bengal, India)

Abstract
This paper provides an overview of the emergence of resource discovery systems and services, along with their advantages, best practices, and current landscapes. It outlines some of the key services and functionalities of a comprehensive discovery model suitable for academic libraries in developing countries. The proposed model (VuFind as a discovery tool) performs like other existing web-scale resource discovery systems, both commercial and open-source, and is capable of providing information resources from different sources in a single-window search interface. The objective of the paper is to provide seamless access to globally distributed subscribed as well as open access resources through its discovery interface, based on a unified index. This model uses Koha, DSpace, and Greenstone as back-ends and VuFind as a discovery layer in the front-end and has also integrated many enhanced search features like Bento-box search, Geodetic search, and full-text search (using Apache Tika). The goal of this paper is to provide the academic community with a one-stop shop for better utilising and integrating heterogeneous bibliographic data sources with VuFind (https://vufind.org/vufind).
- keywords
- information retrieval, web scale discovery, library discovery, federated searching, VuFind, academic library
1. INTRODUCTION
Due to the enormous growth of web resources in various forms and formats, the demand for library discovery services, especially in academic libraries, is growing, and such services have become a new standard in the domain of Library and Information Science (LIS) by replacing federated searching, meta-searching, and OPAC-based retrieval. Due to the open-source movement, new initiatives towards the management of heterogeneous knowledge resources are always on the horizon, and by examining the applications of different resource discovery technologies, both open-source and commercial (such as Primo Central, EBSCO Discovery Service, Summon, etc.), we were able to observe the paradigm change from library automation to library discovery (e.g., Blacklight, VuFind, and LibraryFind). Now, many academic libraries are planning to provide this type of service to their users keeping in mind users’ diverse information needs with modern expectations for search and presentation of information resources. For instance, from 2010 to 2012, discovery services increased from 16% to 29% in the United States and Canada (Hofmann & Yang, 2012). Through these library discovery tools, thousands of academic institutions are now making their local and global collections accessible to their users (Breeding, 2007). However, the first wave of adopters of VuFind (as reported by Seaman, 2012) were the National Library of Australia, Minnesota State Colleges and universities (Digby & Elfstrand, 2011), Western Michigan (Ho et al., 2009) and Villanova itself in 2008. This paper describes in detail the user interfaces, services, and functionalities of the resource discovery model developed using open-source software (OSS), i.e., VuFind, for academic libraries. The main objective of the paper is to provide different value-added services to users, not limited to the library resources through this model.
It is to be noted that commercial discovery tools are costly to subscribe to, install, and maintain. In this context, academic libraries in developing countries like India and other countries in Southeast Asia are exploring OSS for developing library discovery systems. On this basis, this paper may be considered as a confidence-building measure among library professionals of academic libraries in developing countries for developing discovery systems. As discussed in Section 3, most of the academic libraries in developing countries are facing the problems of retrieval silos, and the advent of the OSS movement has given library professionals in developing countries an opportunity to automate their library, to go for a digital library, or to set up an institutional repository (IR) using different open-source tools.
2. LITERATURE REVIEW
The emergence of Information and Communication Technology, especially the WWW (World Wide Web) and the Internet has brought about many fundamental changes to the academic library environment and to users’ information-seeking behaviours over the past three decades (such as changes in technology, library users’ perceptions towards information retrieval, cataloguing, resource management, information environment, or user expectations and searching behaviour). The latest change due to the application of OSS in the domain of LIS in recent years has been the introduction of and demand for library discovery systems.
Several studies point to user dissatisfaction with the traditional library catalogue or OPAC. The “classic” catalogue has very few features, and results cannot be limited by a wide variety of facets or delimiters. The present library search environment has become increasingly fragmented, and most academic libraries offer an assortment of pathways to disparate silos of information. Martell (2008) stated correctly that academic libraries should reassess their current cataloguing procedures to better meet the demands of their customers because use of the catalogue is declining (Han, 2012). Katz and Nagy (2013) reported that users currently prefer a “self-service-oriented approach to searching” that enhances discoverability and accessibility of library-provided content and is expected to boost utilisation statistics (Way, 2010). The evaluation of whether conventional library catalogue interfaces meet or fall short of user expectations and information demands has changed with the introduction of the next-generation catalogue and, subsequently, the discovery platform (Breeding, 2007; Majors & Mantz, 2011; Nagy, 2011; Vaughan, 2011b). Breeding (2011) correctly pointed out that discovery tools are not just for searching but also for finding resources.
As a result of changes in user expectations for information retrieval and competition from commercial web search engines, libraries are under tremendous pressure to provide content (both paid and open access) and services in ways that users prefer. As a result, a brand-new category of library catalogues that make use of technological services not present in conventional library catalogues has emerged. The “next generation catalogue” actually emerged after librarians realised that the library catalogue was no longer useful to users (Wisniewski, 2010). These new search interfaces are often referred to as library 2.0 catalogues (Wilson, 2007); next-generation OPACs, discovery tools, discovery platforms, or discovery layers (Breeding, 2007; Lindström & Malmsten, 2008; Marcin & Morris, 2008; Yang & Hofmann, 2010); or next-generation meta-search tools (Walker, 2015).
As a result, a new category of search system, i.e., library discovery systems, has come to the market and has become popular among the academic community, as it can index content from different locations (not limited to the library) and provide access to the content in an open manner through its unified search interface (Roy et al., 2018). Nagy et al. (2007) reported that the release of VuFind as a discovery tool has come at a perfect time when academic libraries all over the world currently recognize the need to offer their patrons a better tool to search and browse through all of their resources, both open access and subscribed/paid content. Keene (2011) said that a new breed of resource discovery services (RDSs) is an evolutionary step forward in providing academic library users with a ‘one-stop shop’ where they can find their information sources through a single-search box that can search a library’s online and physical content. Hienert et al. (2015) reported how heterogeneous databases from different data providers can be integrated through the VuFind interface to provide the user with one point of access to social science information.
A survey report (National Information Standards Organization, 2013) on librarians from the US and UK reported that 74% of academic libraries had a RDS or were planning to implement one (17%). Another survey report in the UK reported that 77.4% of respondents were already using a discovery service at their institution and about 11% of respondents were in the process of implementing one. This was mainly covered by three products, viz., EBSCO’s EDS, Ex-Libris’ Primo, and Serials Solutions’ Summon (Spezi et al., 2013). In the US, almost 40% of medium-sized libraries have similar offerings (Jones & Thorpe, 2014).
Another study conducted by Comeaux (2017) in 2012 reported that 31 out of 37 (84%) libraries of the Association of Southeastern Research had implemented a discovery service. Yang and Hofmann (2011) showed the use of discovery tools had doubled between 2010 and 2011 in US and Canadian academic libraries. In the same study, they also reported that about 16% of the OPACs in the sample under study did not show any advanced features of the next-generation catalogue. In another study, authors gave a different view and reported that almost 96% of the academic libraries with a discovery layer also offered users access to their regular OPAC (Hofmann & Yang, 2012). In another study (Kronenfeld & Bright, 2015), the authors found that 39% of AAHSL member institutions deployed a discovery tool (56 out of 144) for their libraries. Aaron Tay from the National University of Singapore reported that more than 40% of hits on popular databases come from discovery tools, meaning that 60% of hits come from other sources.
In spite of its success on a global scale, many authors (Fagan et al., 2012) criticized discovery systems/discovery tools and pointed out problems such as the difficulty of carrying out specific disciplinary search strategies or the absence of authority control, which negatively affect the precision of information retrieval. Shi and Levy (2015) expressed concerns about the discovery system by saying that it is no longer novel to many academicians including professional librarians. The understanding of this tool is far from inclusive, nor is it conclusive as to what they do, how they do it, or the cost of delivering this service. Other studies (Buttcher et al., 2007; Vaughan & Thelwall, 2004) confirmed that the bias of search engine coverage and the bias of information retrieval systems do exist among different discovery tools. As a result, product performance differs in many aspects and there is doubt about whether or not these products are well-designed and mature enough to fulfill the expectations of the targeted user group (Shi & Levy, 2015). Thomsett-Scott and Reese (2012) opined that information regarding tools, their implementation, maintenance, and evaluation is limited and insufficient. Narayanan and Mukundan (2015) raised some technical issues such as the level of integration with other systems, interoperability, and soundness of metadata regarding the present discovery system. Deodato (2015) also criticized existing discovery systems and offered a step-by-step guide for developing and evaluating a web-scale discovery system based on literature as well as his own experiences at Rutgers University. The author suggested a more standard set of practices for better representation of web content. On the other hand, Hanneke and O’Brien (2016) were not satisfied with the performance of the existing discovery tools. They reported that after evaluating three major commercial discovery systems, viz. EBSCO Discovery Service (EDS), Ex Libris’s Primo, and ProQuest’s Summon, all discovery tools returned between 50% and 60% of relevant results. Even so, technological features and performance of discovery systems/tools greatly vary, particularly in terms of search effectiveness (Asher et al., 2013). Some other studies expressed concerns over other issues such as technical problems during implementation (Buck & Mellinger, 2011), integration with other library delivery services (Sadeh, 2013), conducting search according to certain disciplines or subject headings, or cross-collection search.
Breeding (2005) first discussed broad-based discovery tools in 2005, shortly after the launch of Google Scholar, and proclaimed the need for a centralised search model like Google Scholar (Fagan et al., 2012). However, the first discovery layer services were introduced in the early 2000s (Antelman et al., 2006). Webb and Nero (2009) observed more value in implementing discovery layers in comparison to Integrated Library System (ILS) OPACs. Some other experts (Breeding, 2010a; Sadeh, 2008) consider VuFind as a next-generation catalogue that can harvest data from OPACs and other external sources such as digital repositories. Other experts (Emmanuel, 2011; Sadeh, 2008) predicted that VuFind may be considered as the next generation catalogue which can replace the traditional catalogue OPAC to increase discoverability of a wide range of objects in different formats from a single-box search interface. Houser (2009) reported the implementation of VuFind at Villanova University whereas Han (2012) reported its implementation in the University of Illinois library. Balaji Babu and Krishnamurthy (2013) reported the implementation of VuFind as a discovery layer by Bangalore University library, India. Another study (Burchill & Rasmussen, 2014) put emphasis on the application of VuFind in public libraries to improve search results and save the searcher time. Saha (2018) reported using the VuFind open discovery tool in German and showed how this discovery tool replaced the traditional OPAC.
Jetty et al. (2011) reported that the influence of Web 2.0 tools and techniques such as social networking, tagging, blogs, wikis, and news feeds has seemed to influence the outlook of future library OPACs and has become mandatory for both the users and the creators. Some other authors (Breeding, 2007; Jetty et al., 2011; Macan et al., 2013; Moore & Greene, 2012) pointed out several features of next-generation OPAC such as faceted navigation, content enrichment, related materials, interoperability, open URL, Unicode compatibility, integration of non-MARC metadata, Web 2.0 functions, and integration with citation management tools. Another group of authors has provided useful lists of criteria such as content, user interface, pricing, and contract options (Ronda, 2010); user interface and Web 2.0 features (Yang & Wagner, 2010); breadth and depth of indexing, search and refinement options, branding and customization, organizing, and exporting results (Hoeppner, 2012); library goals, cost, and vendor support (Luther & Kelly, 2011) for the evaluation of discovery tools, both commercial and open-source. Adams (2012) rightly identified the area and opined that there is enough scope for social engagement or social interactivity in the realm of discovery services for academic libraries. Ho (2013) highlighted many Web 2.0 catalogue features such as user tagging, comments, and reviews, as well as “more like this” and “Did you mean?” supported by VuFind, and also reported how they are being used at Western Michigan University. Merčun and Žumer (2008) also emphasised important issues concerning Web 2.0 features in library catalogues. However, what academic libraries should anticipate from a discovery system is outlined in detail by Kabashi et al. (2014) and is offered as a checklist. Breeding (2015) also provided guidelines and made some recommendations, including the evolution of discovery services and delivery technology (such as OAI-PMH and KBART, Knowledge Bases and Related Tools) required for providing such services to academic libraries. He also suggested incorporating altmetrics into their products.
As a result, discovery services are emerging in academic libraries as an evolution beyond federated searching because federated searching has several drawbacks (such as speed or thoroughness) and partially fulfills users’ needs by providing a single access point to multiple information sources (Kumar et al., 2008). Chen (2006) noted that “a federated search could be dozens of times slower than Google.” Actually, the concept of a “Next Generation Catalogue” has merged with this idea. Even so, federated searching has existed for the last 10-15 years (Roy et al., 2018) and several prototypes are available in various domains such as agriculture (Roy et al., 2016a, 2016b), LIS (Ganaie, 2014; Roy et al., 2017; Sengupta, 2012); and health and medicine (Sarkar & Mukhopadhyay, 2012). As well, prototypes are available for different object types such as electronic theses and dissertations (ETDs) (Sarkar & Mukhopadhyay, 2010, 2015). Again, Sarkar and Mukhopadhyay (2016) discussed designing an OSS based library discovery system for full-text ETDs retrieval apart from accessing ETDs from global-scale services like NDLTD, OATD, IndCat, and ShodhGanga. Gallinger and Neville (2016) shared their practical experiences of using ‘Pika,’ an open-source discovery layer developed by the Marmot Library Network. Dulle and Alphonce (2016) recommended adoption of the ‘LibHub’ discovery tool used by the Faculty of Agriculture at Sokoine University Agriculture in Tanzania. Dhara (2016) shared his practical experiences of designing a small-scale personalized discovery service for the Ramsaday College Library in Howrah, West Bengal and showed its integration with the library OPAC as a one-stop access to an array of library resources. Katz (2016) examined how VuFind was used as the glue to tie together the disparate components of the project at Villanova University. The following years may be considered as key events in the history of web-scale discovery services.
-
2000: The first discovery services were introduced in the early 2000s
-
2003: Federated search allows multiple databases and catalogues to be searched
-
simultaneously
-
2005: Next generation catalogues with discovery layer features
-
2006: First digital library project by Villanova University
-
2007: VuFind was released for the public
-
2007: WorldCat Local delivers the first marriage of discovery layer with central index
-
content
-
2007: VuFind was released as an open-source product to SourceForge
-
2008: National Library of Australia to use first VuFind as web discovery tool
-
2009: Summon joins the discovery layer with robust ‘web scale’ central index content
-
2010: Primo (product of Ex Libris) and EDS started functioning
3. RETRIEVAL SILOS IN ACADEMIC LIBRARIES
Before we begin the discovery search, we should consider how libraries are currently working or providing services to their users. At present, library environments are working through three parallel systems, viz. the library automation system, the system for licensed collections (also known as ERMS), and a digital repository system for open access resources, particularly ETDs. In a true sense, all academic libraries all over the world are presently operating in silos, meaning multi-point retrieval systems that are not related to each other in their operations and exist in isolation. For example, we use OPACs mainly for books and other macro documents in libraries, whereas institutional digital repositories are used for faculty publications, and ETDs. In addition, different retrieval silos are offered by different publishers/databases for paid/licensed/subscribed resources, as well as open-access resources distributed throughout the world in different forms and formats. Apart from the above, different retrieval systems use different search techniques as well as different metadata schemas for archiving different types of content, both textual and non-textual, which in turn provide poor search results to the reader. Additionally, different systems use different software, both open-source and commercial, and are supported by different text retrieval engines such as Solr, Lucene, and Zebra. Even so, all these systems work as independent sub-systems, and there is no such integration among them at any level of their operations. This present situation has made the retrieval process more troublesome for end-users. As a result, users are forced to go from pillar to post in order to retrieve relevant resources against a search query.
Libraries in general deal with homogeneous document types, and metadata schemas are almost the same. The search skills required by the user are almost the same and end-users are expected to know the different search techniques. Such is the present situation of library retrieval, mainly in developing countries. Naturally, questions may arise: Why are we thinking of an alternative option to solve this multi-point retrieval silo?; Should we opt for a discovery service as a solution beyond our traditional search or library search?; What are the added advantages of such a discovery system or what are the basic differences between library search and discovery search?
Our expectations of academic libraries have changed with the passing of time and major changes, particularly in the area of the OSS movement. Now the trend is towards retrieval of heterogeneous content from distributed, unrelated resource management systems. As we previously stated, these multi-point retrieval silos have already been replaced by a single-window search system that provides ‘one-stop-access’ to all library materials by administering a centrally located consolidated index for both internal (resources organised locally and retrieved worldwide) and external (subscribed and open-access resources not normally part of a local retrieval system) knowledge objects.
Here lies the scope of the discovery system or discovery search in academic libraries of developing countries. It is actually beyond the traditional library search, or we can say an improvement over traditional search, in that it can provide additional value-added services apart from merely supporting browsing and searching of library records. In the discovery system, the picture is totally different from the traditional library search in many aspects. This discovery system deals with heterogeneous data sources supported by different metadata schemas. Even so, users do not require any special skills in searching for scholarly resources distributed globally. The discovery system offers a Google-like single-search interface and an OPAC-like elegance (Narayanan & Byers, 2017; Taylor, 2012). It is characterized by supporting many features such as providing ranking and navigation services to subdivide search results by facet results, along with a suitability and visually rich display, suggestions, recommendations of associated resources, full-text indexing, third-party authority search integration, and personal search environment. However, library vendors see their inclusion in discovery tools as essential to their survival. Table 1 shows the differences between Retrieval Silos (library search) and Discovery Search.
Table 1
Comparison between retrieval silos (library search) and discovery search
| Parameters | Retrieval silos | Discovery search |
|---|---|---|
| User interface | Structure | Google-like/single-window approach |
| Search based on | Library catalogue | Single Entry Point/Google-like single search box beyond library |
| Search based on | Live and dynamic queries | Pre-index metadata/Pre-harvested metadata |
| Scope of search | Limited result sets, slow performance | No limit, Fast |
| FRBRization of resources | No | Yes |
| Index | No such index/authors or publishers provide data | Unified index |
| Ranking of search results | No | Yes |
| Data type | Homogeneous | Heterogeneous |
| Data format support | Restricted | No restriction/variety of formats |
| Data source type | Basically textual/documentary sources | Textual/non-textual/non-bibliographic resources |
| Metadata schema support | Limited/mainly for textual objects | Array of schema (different object type) |
| Searching skill/experience | Required | Low level/minimum skill |
| Nature of services | Not dynamic/real-time | Dynamic/real-time |
| Availability of Web 2.0 features | No | Yes |
| Linking to resources for live updates | No | Yes |
| Supporting full-text indexing | No | Yes |
| Supports item-wise search | No | Yes |
| Supports preference setting in searching | No | Yes |
| Supports query forwarding mechanism | No | Yes |
| Faceted navigation | No | Yes |
| Recommendation services | No | Yes |
| Provides use statistics | No | Yes |
| Interface compatible with information visualization technique | No | Yes |
4. OBJECTIVES
In keeping with the present multi-point retrieval windows of libraries, the objectives are set as follows.
4.1. Unification of Retrieval Silos
The main purpose of our paper is to create a single-window search system in place of multiple retrieval silos in an academic library. Our motto is to design a one-stop access point in place of the existing retrieval silos in libraries. The single window search offers users a single point of entry to scholarly resources (subscribed, in-house, and open access) available in multiple formats and on different retrieval platforms. Actually, it is a ‘one-stop-shop’ solution for libraries in providing easy access to heterogeneous collections through a single location. This single window interface allows researchers the facility to search and browse their documents in a variety of ways at a single point, bypassing the multi-point retrieval hazards of the present retrieval silos of libraries.
4.2. Integration of Enhanced Retrieval Techniques in Discovery Layer
This discovery portal not only provides access to subscribed, in-house, and open access resources owned by libraries, but also has the provision of incorporating several enhanced functionalities that provide additional value-added services through its unified interface. It integrates multiple services such as faceted navigation (here users can narrow down the search results by format, location, author, topic, subject area, call number, language, genre, region, and title), relevance-ranked results, integrated metadata search, full-text search, search history and favorites, persistent URLs, application program interfaces (APIs) like open search, etc. The “classic” catalogue has very few such features and results cannot be limited by a wide variety of facets or delimiters. Martell (2008) rightly said that use of the catalogue is down, even though this system has the ability to include query-forwarding mechanisms to fetch content from institutional repositories (OpenDOAR – https://v2.sherpa.ac.uk/opendoar; ROAR – http://roar.eprints.org); open access journal articles (DOAJ - https://doaj.org) and from different pathfinder search services (BASE – https://www.base-search.net; LENS – https://www.lens.org), Geodetic search, or Bento-box search.
5. RESEARCH QUESTIONS
To fulfill the stated objectives, we have designed two broad research questions. The main challenges in designing such a system are:
-
What type of discovery tool may be selected for an academic library in a developing country that will manage internal as well as external/subscribed/open access resources distributed across the world? What should be the architecture behind it? What considerations should be given to selecting a discovery layer from an array of open-source discovery tools?
-
How, and to what extent, can full-text search be integrated into the discovery interface in addition to the simple metadata-based retrieval of a typical academic library? How can a search system be enhanced with different value-added information services? Can it be converted into any native/regional language in India?
6. METHODOLOGY: DEVELOPMENT OF THE PROTOTYPE
This section is concerned with the development of the prototype. It has two parts, viz. selection of discovery software (Table 2), and application of the model in a real-life situation. Actually, the prototype has been developed using different OSS in different levels of its operations. Initially, selection of software for each stage (for example, Apache Tika – https://tika.apache.org has been selected as full-text extractor for supporting full text search) and preparing the ‘LAMP’ (Linux-Apache-MySQL-PERL/PHP) architecture is the most important task in developing the model. Another important task is integrating VuFind with Koha (ILS) through REST/API to display real-time item availability status, DSpace (repository software), and Greenstone.
Table 2
Features supported by three discovery software
| Criteria/parameters | Resource discovery software | ||
|---|---|---|---|
| Blacklight | eXtensible Catalog | VuFind | |
| Flexible support for non-MARC metadata formats | * | ✓ | ✓ |
| Support for RDA cataloging | * | ✓ | ✓ |
| Authority control mechanism | * | * | ✓ |
| Availability of linking mechanism with full-text extractor | * | * | ✓ |
| Availability of multiple crosswork mapping support for managing domain specific metadata schema | * | * | ✓ |
| Full-text searching | * | * | ✓ |
| ‘Bento Box’ search (categorization or records according to the sources) | * | * | ✓ |
| Search within search | * | * | ✓ |
| Search-term recommendations | * | * | ✓ |
| Geodetic search | * | * | ✓ |
| Persistent links | ✓ | * | ✓ |
| Stem search | ✓ | * | ✓ |
| Usage statistics | * | * | ✓ |
| OpenURL/opensearch | ✓ | * | ✓ |
| Google Analytics support | ✓ | * | ✓ |
| Support for images/multimedia objects | * | ✓ | ✓ |
| Support variety of data/metadata format | * | * | ✓ |
| Visualized searching tool | ✓ | * | ✓ |
| Visual organization (e.g., tag cloud) | ✓ | * | ✓ |
| Author biographies | * | * | ✓ |
| Geographic searching and map display/map search results view/GPS-enabled display | ✓ | * | ✓ |
| Visualizing graphs and maps | ✓ | * | ✓ |
| Advanced protocols (OA-DOI/OAI-ORE/RDF/ORCID) | * | * | ✓ |
| Linking with LOD | * | ✓ | ✓ |
| RDF/XML support | * | * | ✓ |
| Integration with commercial discovery system with connector (e.g., Serials Solutions’ Summon) | ✓ | * | ✓ |
| Support for the Piwik open source analytics tool | * | * | ✓ |
| Integrate the library’s locations and live record status | ✓ | * | ✓ |
| Search history | ✓ | * | ✓ |
| Query forwarding mechanism | * | * | ✓ |
| Multilingualism | * | * | ✓ |
Here, discussion has been made into three layers, viz. identification and selection of discovery layer (i.e., concerned with the selection of discovery tool on the basis of support for enhanced technological features (Table 2)), advocacy for VuFind (concerned with existing literature on and about library discover systems), and interoperability support.
6.1. Identification and Selection of Discovery Layer
We have already discussed in the literature review (Section 2) that VuFind has been the most preferable choice of library professionals in the open domain. After evaluating several discovery tools, both open-source and commercial, against a set of criteria, the desirable features in the context of an academic library in a developing country have been identified in three open-source tools (Table 2). We have already mentioned in the introduction why we have chosen open-source tools for developing the discovery interface for academic libraries. In this study, three OSS programs, VuFind (developed by Villanova University), Blacklight (developed by the University of Virginia), and eXtensible Catalog (developed by the River Campus Libraries of the University of Rochester), were compared against a set of parameters important for academic libraries in developing countries. VuFind was chosen as the discovery tool for designing the prototype. We must say that an open-source discovery tool like VuFind tends to operate in a similar way to any other commercial discovery tool.
Table 2 covers only the technical features of discovery tools, which are applicable globally to all discovery layers under discussion. Apart from these technical features, the following factors are also equally important while selecting discovery tools for academic libraries in developing countries like India. The factors include: cost of the product (one time and recurring), dedicated server, continuous support, user base, active forum, software as a service (SOS) model, age of maintenance, integration with other software, etc. For example, in India, commercial discovery systems like EDS cost more than 20 lakhs (equivalent to almost 25,593.94 US dollars) per year. It is not possible for all academic libraries to incur the cost. We cannot even say that such commercial systems are always better than open-source equivalents like VuFind. Apart from that, most of the academic libraries in India use an ILS like Koha or a digital library system like Omega ( https://omeka.org), which is also LAMP-based.
6.2. Advocacy for VuFind
Still now, the search interfaces of most academic libraries rely on quasi-traditional approaches to find resources by some selected options such as title or author. As stated, Katz and Nagy (2013) noted that users now prefer a “self-service-oriented approach to searching” and the search interface offered by libraries is not supported by Web 2.0 features. Like other commercial discovery tools, VuFind includes many Web 2.0 catalogue features such as recommendations, user tagging, comments, and reviews, as well as “more like this” and “Did you mean?” to reduce the limitations of traditional library catalogue searches (Ho, 2013). Breeding (2009) reported that VuFind was one of the first open-source discovery interfaces for libraries and a number of academic libraries have implemented it, such as the National University of Australia ( http://catalogue.nla.gov.au), Consortium of Academic and Research Libraries in Illinois ( http://vufind.carli.illinois.edu), Minnesota State Colleges and Universities ( http://plus.mnpals.net), and Yale University ( http://yufind.library.yale.edu). Many authors have praised the flexibility of open-source discovery layers, which provide the ability to devise customized solutions to local problems (Barber et al., 2016). Several academic libraries have already implemented VuFind either as their primary catalogue interface or as an optional alternative (Emmanuel, 2011; Johnston et al., 2013; Leebaw et al., 2013) due to its outstanding Web 2.0 features, including author biographies, full-text search, hit highlighting, faceted search, dynamic clustering, database integration, and rich document (e.g., Word, PDF) handling (Breeding, 2010b; Shahi, 2015). Ho and Horne-Popp (2013) opined that VuFind has been proven to be a valid solution for academic libraries in providing an alternative catalogue interface for users.
This has already been covered in the literature review, and most of the researchers have preferred VuFind as their discovery layer for academic libraries. Apart from this, more than 200 institutions throughout the world are currently running or testing VuFind ( https://vufind.org/wiki/community:installations). It is also found from the list that eight Indian organizations have already implemented VuFind in their institutes, such as N-List ( https://nlist.inflibnet.ac.in). Apart from this, it has the most installations ( https://vufind.org/wiki/community:installations) and also has the first position (Sourceforge, 2021) as per download statistics in the open-source domain. Hofmann and Yang (2012) found in their study that the top three popular discovery tools were WorldCat Local by OCLC, Summon by Serials Solutions, and VuFind. VuFind allows interoperability with most of the content and catalogue database providers such as Primo Central, EBSCO-Host, Summon, or WorldCat. Breeding (2015) stated that two open-source technologies, namely VuFind and Blacklight, have acquired significant popularity among the academic community in the discovery interface space. Parry (2009) reported that the most popular discovery tools in the open domain are VuFind, Blacklight, and eXtensible Catalog. Our paper published in Library Hi Tech News (Vol. 35, No. 3, pp. 16-22) has already established the fact that VuFind (Table 2) may be a potential software for designing discovery systems for academic libraries (Roy et al., 2018). The other important features which have made VuFind more popular than other discovery tools include auto suggestion, context-sensitive recommendations, use of APIs, and means of harvesting and locally indexing authority data (Katz et al., 2011). Brink-Drescher (2014) stated that VuFind is a highly customizable open-source product that allows information repositories of any size or type to tie together and brand multiple services into a single unified interface. Burchill and Rasmussen (2014) discussed how VuFind not only indexes library catalogues but also proprietary databases through the integration of APIs, offering public libraries the opportunity to develop a seamless website-to-catalogue experience, thereby building a true virtual branch for their patrons. Chickering and Yang (2014) showed the adoption of fourteen web-scale discovery tools, both commercial and open-source, in North America and, after comparing open-source tools against sixteen parameters, concluded that VuFind is the best in the open-source domain. Denton and Coysh (2011) also reported in their usability study that users preferred VuFind’s interface over the classic catalogue. Ho and Horne-Popp (2013) rightly said that VuFind has proved to be a valid solution for academic libraries.
Actually, VuFind was developed as a library discovery tool to take the place of the classic ILS database structure, which was its weakest link (Katz & Nagy, 2013). A number of academic libraries have been able to enhance their search results and add features by using VuFind. Many of the Web 2.0 features that consumers find on online article databases and commerce websites are also available through VuFind, in addition to increased search capabilities. VuFind is giving academic libraries a third way toward improving the concept of the library catalogue, the core tool for accessing library holdings (Ho & Horne-Popp, 2013). Skinner (2012) also compared the searching functionalities of VuFind with those of a traditional academic library’s catalogue. Even FINNA-the National Digital Library of Finland ( https://researchportal.helsinki.fi/en), TROVE-National Library of Australia ( https://trove.nla.gov.au), and BASE-Bielefeld Academic Search Engine ( https://www.base-search.net) also use VuFind as a back-end interface.
6.3. Interoperability Supports
A typical library discovery system has three parts: a harvester, a central index (import mechanisms), and a user interface. VuFind is no exception. It has all these three essential components, supporting globally agreed-upon interoperability standards for each layer. For example, it provides support for direct database interaction, ILS-DI, and REST/API for generating item availability status in real-time for many supported back-end ILSs. It provides an array of drivers for popular ILSs like Innopac, Voyager, SirsiDynix, Koha, Aleph, Folio, Virtua, and NewGenlib. It comes with support for a variety of retrieval features like Bento-box search and Geodetic search. Apart from other features like continuous revision of code, continuous release cycle, etc., the support for almost all global standards (like REST/API) has made the software popular with academic library administrators. VuFind’s standard ‘biblio’ core was also designed for indexing MARC as well as MARC-like data, e.g., simple and qualified Dublin Core metadata (Katz, 2016). Even so, VuFind allows interoperability with most content and catalogue database providers such as Primo Central, EBSCOHost, Summon, or WorldCat. It has many APIs to interact with other software in a library eco-system, and can act as an OAI data provider. Moreover, VuFind is compatible with the standards and protocols proposed by NISO (National Information Standards Organization) (National Information Standards Organization, 2020) and ODI (Open Discovery Initiative) (National Information Standards Organization, 2012).
The whole operational process of the model is illustrated here (Fig. 1).
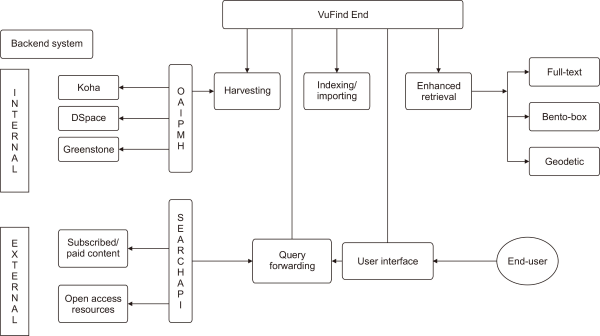
In our back-end system, we have used the three open-source tools mentioned above, implemented by most of the academic libraries in developing countries, for managing their internal resources. For example, DSpace is used for providing access to ETDs, whereas Koha is used for managing bibliographic data of library resources. All these tools are OAI-PMH compliant and allow us to import and index bibliographic data as well as full-text content. Apart from in-house resources, academic libraries are procuring various external resources, including subscribed/paid and open access content. A unique query-forwarding mechanism in VuFind can allow end-users to extend their search queries to selected subscribed and/or open access services/tools from the same search interface where they can search internal resources of an academic library. The availability of features like Bento-box search (which can indicate the origin of retrieved resources distributed in different back-end silos in an academic library), and geodetic search (map-based retrieval of resources) makes VuFind an automatic choice for designing a discovery layer in an academic library.
As stated, the model has been developed considering basic theoretical and practical problems that arise during its installation and customization, as well as keeping in mind a summary of ideas or observations as covered in the literature review. The model has been tested on different configurations and against a set of heterogeneous data. Initially, the prototype has been tested against 1,000 more unique documents, including books, articles, theses and dissertations, non-book materials, and non-English knowledge objects, against different search syntax to measure the effectiveness of the model and to fulfill the promises we have made. We have checked all the features of VuFind and the knowledge has already been communicated through different workshops, training sessions, and writings so that it becomes another movement like the Koha movement in India, even though this framework has been developed in such a way that it could be integrated with any web-enabled on-line information representation and retrieval system.
7. KEY FEATURES OF THE MODEL
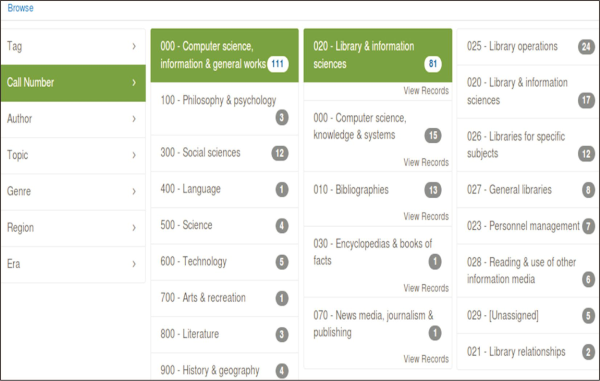
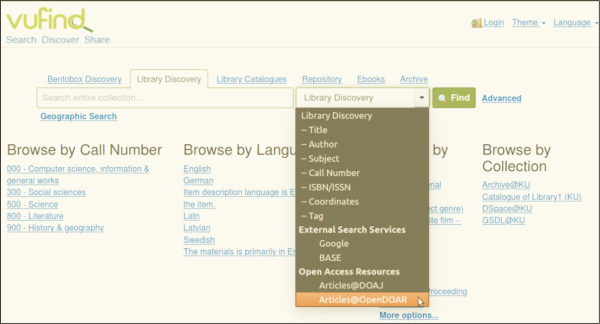
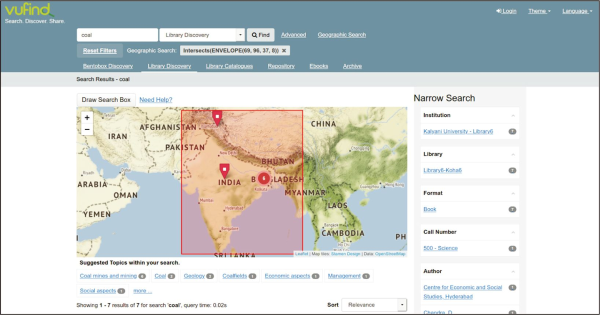
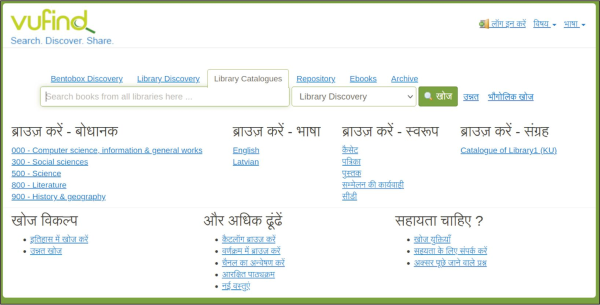
Like other resource discovery systems, including commercial ones such as EDS and Summon, this system offers: basic and advanced search facilities; support for searching resources by call number/class number of the respective document (here DDC – Dewey Decimal Classification, Fig. 2); support for searching varieties of contents including commercial, licensed, or open databases through query forwarding mechanism (Fig. 3); support for full-text searching using Tika (Fig. 4); Bento-box search (Fig. 5); Geodetic search (Fig. 6); and search collections by a particular language (here in Hindi language, Fig. 7). Some of these unique features (especially query forwarding; full-text search; Bentobox search; Geodetic search) are not generally supported by many academic libraries like the British Library ( https://www.bl.uk/#) or Library of Congress ( https://catalog.loc.gov).
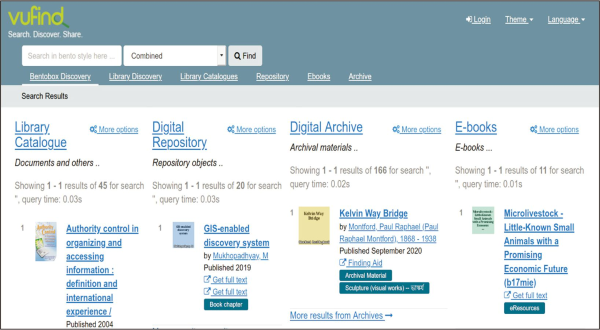
As well, this harvested index-based interface also provides full-text access of open access/licensed content based on real time usage data. In its retrieval interface, it also facilitates the integration of information visualisation tools. Every effort has been made through its real-time application, keeping in mind several limitations of present discovery systems (Section 8) and observations as suggested by authors (in the literature review section) following several practical implementations. Here, some of the services offered by this model are now illustrated.
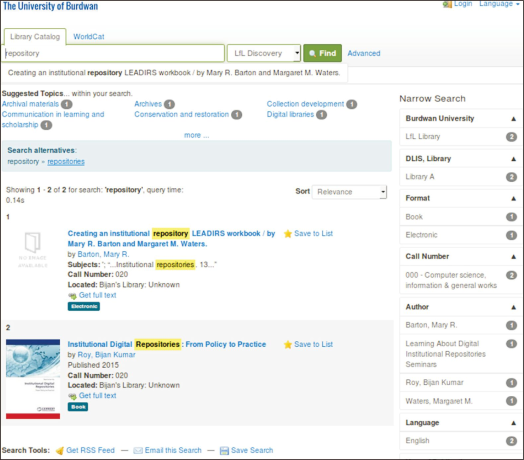
7.1. Catalogue in Discovery/Integrated Metadata Search
VuFind is well-equipped to index authority data from any ILS or Library Management Software (LMS). It allows data to be captured from any web-enabled and OAI-compliant bibliographic database. It supports a number of ILS or LMS, both commercial and open-source such as Koha or NewGenLib, to be integrated with its indexing mechanism. Here, MARC records were exported from Koha and then imported into VuFind (Fig. 8).
7.2. Knowledge Objects in Discovery
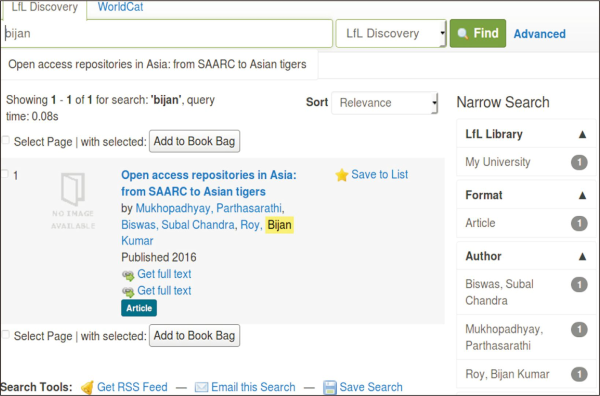
VuFind allows importing records from any repository system. For this study, resources have been extracted from local repository developed by DSpace software (Fig. 9).
7.3. Browsing in Discovery
Organizing resources and searching them using any subject access system is the added advantage of any online information retrieval system (Roy, 2014, 2015) and is the key to the success of an IR system (Roy et al., 2016c, 2016d). Most of the library catalogues or OPAC of academic libraries do not support browsing and facilitate only searching for resources. The most interesting feature of this framework is searching for resources by class/call number (here DDC - Dewey Decimal Classification) (Fig. 2).
7.4. Extended Search in Discovery
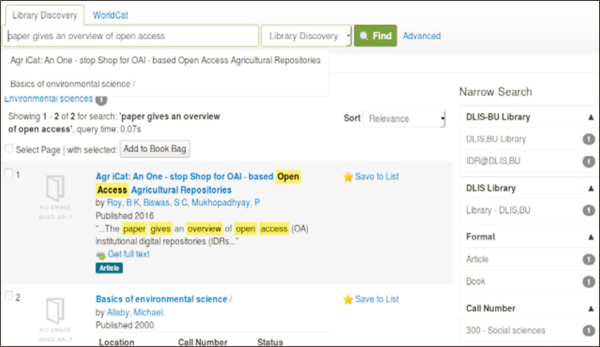
This model incorporated some of the pathfinder tools (such as BASE, DOAJ, and OpenDOAR) in its discovery interface in order to provide additional value-added/enhanced services to the users through a query forwarding mechanism (Fig. 3).
7.5. Full Text Search/Indexing
As stated, this model supports full-text searching and can extract keywords or phrases from any document (Fig. 4). For this purpose, ‘Apache Tika’ has been used as full-text extractor in the back-end layer of the model.
7.6. Bento-Box Search
The phrase ‘bento box’ is derived from Japanese cuisine where different components of a meal are compartmentalized in aesthetically pleasing ways. It is a unified approach where outcomes derived from many systems or categories are compartmentalized by system or category, like in a Japanese ‘bento’ style lunch box. The ‘bento box’ design is referred to as such because of its resemblance to the shape of Japanese lunch boxes (Singley, 2016). It provides a single search box that displays results from various libraries side by side (Fig. 5). The ‘bento-box’ presentation makes library search easier for users as results from several sources are returned in visually discrete boxes (Jaffy, 2020). The option to offer a ‘bento box’ display of search results is only available through a customization of OSS – no commercial product offers it.
7.7. Geodetic Search
A sub-domain of the Geographic Information System is geodetic search, often known as GIS-enabled search or geographic search (GIS). A geodetic search framework is a type of land-information system that uses a mathematical framework to spatially reference all land data to appreciable locations on the surface of the Earth. These systems use a mathematical framework for spatially referencing all land data to discrete points on the Earth’s surface to determine locations. When retrieving documents and data from sources where places or geographic names are the primary foci, such as information sources in the fields of geography, mineralogy, geology, travel guides, etc., the geodetic search mechanism may prove to be an effective process that goes beyond text-only search. In the bibliographic area, a geodetic search system should also facilitate the following actions: a) the document locations’ longitudes, latitudes, or boundary values; b) integrating geo-coordinate values with the active map service; and c) making geodetic data sources visible in the search interface to filter search results. A MARC-formatted authority data-set has been created by Mukhopadhyay and Mukhopadhyay (2022) for Indian geo-administrative divisions due to the lack of coverage of Indian place names in worldwide authority data-sets. Fig. 6 shows the availability of documents including their physical location in the library for the search term ‘coal.’
7.8. Interface in Hindi
The default interface of VuFind has been translated into two Indian languages. One of the co-authors of this paper is responsible for all Indian language translations and currently two languages (such as Bengali – https://github.com/vufind-org/vufind/blob/dev/languages/bn.ini; and Hindi – https://github.com/vufind-org/vufind/blob/dev/languages/hi.ini; (Barman & Mukhopadhyay, 2018)) (Fig. 7) have been done.
8. FUTURE CONSIDERATIONS
As is clear from the literature review, many libraries are not using discovery tools and thus the adoption rate of such systems among academic libraries widely differs by discipline and region. It is a hard fact that there is a lot of work (as stated below in this section) to be done in different levels of its settings and operations by adding new functionalities and capabilities, to make the present-day discovery system more encompassing and efficient for academic library users to find the information that they need. As a result, the discovery system did not meet our inflated expectations, and there are numerous practical issues to consider in addition to the quantitative factors measured in our work. Simultaneously, the authors admit that the time of trials, beta testing, and debate over whether to adopt discovery tools in academic libraries is past.
Still, there is enough scope for integrating the discovery layer with transactions logs, cloud services, open linked data, incorporation of altmetrics into the discovery services eco-system, research data management, facet visualization, visual analytics, incorporation of external social networks, incorporation of learning management systems, integration of user-generated metadata into the cataloguing records, RDA-compliant MARC fields in authority records, integration of abstracting and indexing services, folksonomies or user generated tags to form ‘word clouds,’ integration with OpenStreetMaps, GeoNames (for the location of an item and user-driven acquisitions), OpenURL and Digital Object Identifiers, automatic mapping of search terms between different thesauri, integration with controlled vocabularies or ontologies, interoperability with link resolver, etc. to make the user interface more intuitive and visually attractive to readers.
Another important area of concern in the discovery system is maintaining the quality of metadata and integrating domain-specific metadata schemas for indexing or importing metadata of non-textual objects. The discovery system should integrate different metadata schemas meant for non-textual resources or special types of collections. Most academic libraries have some sort of special collection, but they are not accessible to users. The use of these types of objects is increasing due to their immense value to society. VuFind presently supports MARC (MARC-XML), Dublin Core, and CDWA-Lite metadata schemas. There is no such development that has been reported in the existing literature for incorporating these special collections into discovery interfaces. Some of the metadata schemas have been suggested for some non-textual objects: for example, for cultural, museum, art and architecture objects (CCO, LIDO), audio, musical materials, video or images (VRA Code), and learning objects (LOM). Further studies may be conducted in this area to make the interface more attractive to users.
Managing authority records in the discovery layer is also important as “the value of rich authority data should be shared with everyone, not just catalogers” (Katz et al., 2011). Authority file cross-references are not currently utilized in the discovery system, although this is a planned enhancement to the discovery environment (Houser, 2009; Skinner, 2012). If library catalogues can provide a Google-like experience and retain many of the ‘behind the scenes’ search aspects of traditional catalogues, the combined features may well result in the creation of a truly powerful discovery and search tool in the domain of academic library systems (Merčun & Žumer, 2008).
9. CONCLUSION
Still, academic library environments in developing countries are not fully aware of these new systems (Vaughan, 2011a; Way, 2010) and are in their infant stages of development. But these next-generation catalogues are emerging quickly as an alternative service model for library professionals by replacing existing practises (Tay, 2011; Vaughan, 2011a; Vaughan & Hanken, 2011). Walker (2015) correctly stated that RDSs are popular because they “offer superior performance, a much broader search scope, and no limit on the number of results retrieved by the system.” Breeding (2015) supports this by saying that discovery layers provide an interface with search and retrieval capabilities, with relevancy ranking and various facets to narrow the results, and interoperability with a link resolver.
It is quite clear from the above discussions (made in Section 8) that discovery systems or discovery tools are not up to the standard in many aspects. Hence, selecting a discovery tool, particularly open-source, and designing its technical architecture best suited for academic libraries in developing countries is also a challenging task. In our study, we have made an attempt to reduce some of the lacuna of the existing discovery system by incorporating a few unique features into our model following global recommendations and best practices. To fulfill the promises made in Section 5, we have developed a back-end architecture and customized our discovery software, VuFind, to make it unique from other discovery systems. As a result, our model, apart from supporting full-text searching through Apache Tika, provides some other value added services as stated in Section 7 and smoothly handles internal and external resources or resources from the public domain, including licensed/subscribed resources owned by commercial publishers, as depicted in Fig. 1.
Through the discussion of literature and our experience in developing discovery systems, the research questions covered in Section 5.1 have the following answers. Open-source discovery software compared to costly commercial discovery tools will be more beneficial in the long run for an academic library in developing countries (see Section 6.1 and Table 2). A LAMP-based discovery tool will have the possibility to be merged seamlessly with other library software eco-systems in an academic library. As we have said, most of the academic libraries in India use Koha as an ILS and Omega or DSpace as digital library software, and both the tools are LAMP-based. Thus, the integration of open-source discovery tools with ILS or DL systems will be much easier than with other discovery tools (see Section 7.1 & 7.2, Figs. 8 and 9); so question number 2 is fulfilled. Table 2 has already discussed in detail the technical features of VuFind and it comes in fine colour in comparison with open-source counter parts. Sometimes, VuFind is found to be at par with other discovery tools, and in some cases, it performs much better than other tools; so question number 3 is fulfilled.
Now the research questions covered in Section 5.2 are to be discussed. Many open-source tools are available for full-text extractors. As stated, VuFind is based on open architecture. We have seamlessly integrated Apache Tika with VuFind in our prototype (see Section 7.5, Fig. 4). Before populating the Solr index, VuFind can get full-text indexing done through Apache Tika and store it in Apache Solr; so the first question of this section is fulfilled. The next question is concerned with incorporating different value-added services into the discovery layer. Our prototype also discusses search enhancements like bento-box search. We are not only providing a single-window search interface but also ensuring that our model can compartmentalise the sources of data from where it is coming (see Section 7.6, Fig. 5). In addition, our model can highlight the physical location of any library holdings (see Section 7.7, Fig. 6). This is an added advantage of this model, which is not supported by other discovery systems. Apart from that, our model supports browsing and searching for resources in any native or regional language (see Section 7.8, Fig. 7). In a country like India, where a good number of knowledge objects are published in different vernacular languages such as Bengali and Hindi, there should be a provision for incorporating non-English knowledge objects into the discovery system. As a result, our system has kept its promise by making a discovery interface in Hindi, and there is enough scope for integrating any other language apart from English; so the third question of this section is fulfilled.
As a result, this integrated model offers new opportunities and innovative services to users and fulfills its promises by delivering easy, fast, and comprehensive search results effectively and efficiently through a single-entry point. The authors cannot claim this model as a ‘one-size-fits-all’ arena, but it may be helpful in increasing usage statistics of full-text resources or online collections including journal articles and databases. Even more, it may even help library professionals improve their service efficiency by guiding users in searching for web resources from multiple external data sources, both commercial and license-free. In this context, this model may be considered as a ‘class of products’ in the academic world, as it supports resource discovery beyond the library OPAC at the metadata level as well as at the full-text level. As well, the user interface is much more ‘cosmetically and functionally’ better than the old web OPACs of the library, so the outcome of this model may present an example to library managers who wish to integrate distributed library resources in a one-stop access and thereby want to save end users running from pillar to post in retrieving required resources.
Finally, we must say that although progress has been made in different directions in this arena and the discovery system has improved immensely over the years, discovery services still have room for improvement by incorporating different tools and services as covered in Section 8. In our proposed model, we have included some of the Web 2.0 tools in addition to incorporating different pathfinder sites as suggested in our objectives (Fig. 3). This is an attempt to better index, retrieve, and rank heterogeneous resources in a more magical way than before. As well, there is still a wealth of space for library professionals to be part of this development, and they can play a crucial role in this new journey by contributing their professional knowledge to this challenging and aspiring area. Then, discovery systems/tools can be viewed as a mixed blessing for library professionals as well as academic library users in developing countries.
REFERENCES
(2012) Collaborations: The rise of research networks Nature, 490(7420), 335-336 https://doi.org/10.1038/490335a.
, , (2006) Toward a twenty-first century catalog Information Technology and Libraries, 25(3), 128-139 https://doi.org/10.6017/ital.v25i3.3342.
, , (2013) Paths of discovery: Comparing the search effectiveness of EBSCO Discovery Service, Summon, Google Scholar, and conventional library resources College & Research Libraries, 74(5), 464-488 https://doi.org/10.5860/crl-374.
, (2013) Library automation to resource discovery: a review of emerging challenges The Electronic Library, 31(4), 433-451 https://doi.org/10.1108/EL-11-2011-0159.
, , (2016) Customizing an open source discovery layer at East Carolina University Libraries: The cataloger's role in developing a replacement for a traditional online catalog Library Resources & Technical Services, 60(3), 182-190 https://doi.org/10.5860/lrts.60n3.182.
, (2018) Library discovery system in Bengali script: An experiment with VuFind Journal of Advancements in Library Sciences, 5(2), 20-26 https://doi.org/10.37591/joals.v5i2.815.
(2005) Plotting a new course for metasearch Computers in Libraries, 25(2), 27-30 https://librarytechnology.org/document/11341/.
(2007) Next-generation library catalogs Library Technology Reports, 43(4) https://librarytechnology.org/document/12723/.
(2009) Open source discovery interfaces gain momentum Smart Libraries Newsletter, 29(4), 1-4 https://librarytechnology.org/document/13999.
(2010a) Library technology guides: Key resources in the field of library automation www.librarytechnology.org
(2011) Discovering Harry Potter Computers in Libraries, 31(2), 21-25 https://librarytechnology.org/document/15596/.
(2015) The future of library resource discovery Information Standards Quarterly, 27(1), 24-30 https://www.niso.org/sites/default/files/stories/2017-10/NR_Breeding_Discovery_isqv27no1_0.pdf.
(2014) VuFind: A NextGen overlay The Charleston Advisor, 16(2), 46-54 https://doi.org/10.5260/chara.16.2.46.
, (2011) The impact of Serial Solutions' Summon™ on information literacy instruction: Librarian perceptions Internet Reference Services Quarterly, 16(4), 159-181 https://doi.org/10.1080/10875301.2011.621864.
, (2014) Implementing VuFind: A public library improves electronic search quality and saves searcher time Public Library Quarterly, 33(1), 76-82 https://doi.org/10.1080/01616846.2014.877718.
(2006) MetaLib, WebFeat, and Google: The strengths and weaknesses of federated search engines compared with Google Online Information Review, 30(4), 413-427 https://doi.org/10.1108/14684520610686300.
, (2014) Evaluation and comparison of discovery tools: An update Information Technology and Libraries, 33(2), 5-30 https://doi.org/10.6017/ital.v33i2.3471.
(2017) Web design trends in academic libraries-A longitudinal study Journal of Web Librarianship, 11(1), 1-15 https://doi.org/10.1080/19322909.2016.1230031.
, (2011) Usability testing of VuFind at an academic library Library Hi Tech, 29(2), 301-319 https://doi.org/10.1108/07378831111138189.
(2015) Evaluating web-scale discovery services: A step-by-step guide Information Technology and Libraries, 34(2), 19-75 https://doi.org/10.6017/ital.v34i2.5745.
(2016) A personalised discovery service using Google custom search engine Annals of Library and Information Studies, 63(4), 298-305 http://op.niscair.res.in/index.php/ALIS/article/view/13880.
, (2011) Discovering open source discovery: Using VuFind to create MnPALS plus Computers in Libraries, 31(2), 6-10 https://eric.ed.gov/?id=EJ926247.
, (2016) Addressing online information resources' access challenges: Potentials of resource discovery tools' application Annals of Library and Information Studies, 63(4), 266-273 https://core.ac.uk/download/pdf/229207291.pdf.
(2011) Usability of the VuFind next-generation online catalog Information Technology and Libraries, 30(1), 44-52 https://doi.org/10.6017/ital.v30i1.3044.
, , , , (2012) Usability test results for a discovery tool in an academic library Information Technology and Libraries, 31(1), 83-112 https://doi.org/10.6017/ital.v31i1.1855.
, (2016) Usability in the Pika discovery layer: An academic and public library case study Annals of Library and Information Studies, 63(4), 261-265 http://nopr.niscair.res.in/bitstream/123456789/39768/1/ALIS%2063%284%29%20261-265.pdf.
(2014) Current trends of the open access digital repositories in library and information science International Journal of Information Dissemination and Technology, 4(4), 278-282 https://ijidt.com/index.php/ijidt/article/view/444.
(2012) New discovery services and library bibliographic control Library Trends, 61(1), 162-172 https://doi.org/10.1353/lib.2012.0025.
, (2016) Comparison of three web-scale discovery services for health sciences research Journal of the Medical Library Association, 104(2), 109-117 https://doi.org/10.3163/1536-5050.104.2.004. Article Id (pmcid)
, , (2015) Digital library research in action: Supporting information retrieval in Sowiport D-Lib Magazine, 21(3/4), 8 https://doi.org/10.1045/march2015-hienert.
, , (2009) Implementing VuFind as an alternative to Voyager's WebVoyage interface: One library's experience Library Hi Tech, 27(1), 82-92 https://doi.org/10.1108/07378830910942946.
(2012) The ins and outs of evaluating web-scale discovery services Computers in Libraries, 32(3), 6-10 https://eric.ed.gov/?id=EJ970478.
, (2012) "Discovering" what's changed: A revisit of the OPACs of 260 academic libraries Library Hi Tech, 30(2), 253-274 https://doi.org/10.1108/07378831211239942.
(2009) The VuFind implementation at Villanova University Library Hi Tech, 27(1), 93-105 https://doi.org/10.1108/07378830910942955.
(2020) Bento-box user experience study at Franklin University Information Technology and Libraries, 39(1), 1-20 https://doi.org/10.6017/ital.v39i1.11581.
, , , (2011) OPAC 2.0: Towards the next generation of online library catalogues http://eprints.mdx.ac.uk/7964
, , (2013) Determining usability of VuFind for users in the United Arab Emirates Code4Lib Journal, 19 http://journal.code4lib.org/articles/7880.
, (2014) Library homepage design at medium-sized institutions Journal of Web Librarianship, 8(1), 1-22 https://doi.org/10.1080/19322909.2014.850315.
, , (2014) Discovery services: A white paper for the Texas State Library and Archives Commission https://librarytechnology.org/document/19732/
(2016) The triumph of David: A case study in VuFind customization Annals of Library and Information Studies, 63(4), 241-260 http://op.niscair.res.in/index.php/ALIS/article/view/14527.
, , (2011) Using authority data in VuFind Code4Lib Journal, 14 https://journal.code4lib.org/articles/5354.
(2011) Discovery services: Next generation of searching scholarly information Serials, 24(2), 193-196 https://doi.org/10.1629/24193.
, (2015) Library resource discovery Journal of the Medical Library Association, 103(4), 210-213 https://doi.org/10.3163/1536-5050.103.4.011. Article Id (pmcid)
, , , , (2013) Improving library resource discovery: Exploring the possibilities of VuFind and web-scale discovery Journal of Web Librarianship, 7(2), 154-189 https://doi.org/10.1080/19322909.2013.785825.
, (2008) User-centred design and the next generation OPAC - A perfect match? https://library.wur.nl/elag2008/presentations/Lindstrom_Malmsten.pdf
, , (2013) Open source solutions for libraries: ABCD vs Koha Program: Electronic Library and Information Systems, 47(2), 136-154 https://doi.org/10.1108/00330331311313726.
, (2011) Moving to the patron's beat OCLC Systems & Services, 27(4), 275-283 https://doi.org/10.1108/10650751111182588.
, (2008) OPAC: The next generation placing an encore front end onto a SirsiDynix ILS Computers in Libraries, 28(5), 6-9 https://eric.ed.gov/?id=EJ793035.
(2008) The absent user: Physical use of academic library collections and services continues to decline 1995-2006 The Journal of Academic Librarianship, 34(5), 400-407 https://doi.org/10.1016/j.acalib.2008.06.003.
, (2008) New generation of catalogues for the new generation of users: A comparison of six library catalogues Program: Electronic Library and Information Systems, 42(3), 243-261 https://doi.org/10.1108/00330330810892668.
, (2012) The search for a new OPAC: Selecting an open source discovery layer Serials Review, 38(1), 24-30 https://doi.org/10.1080/00987913.2012.10765415.
, (2017) Improving web scale discovery services Annals of Library and Information Studies, 64(4), 276-279 https://core.ac.uk/download/pdf/229208282.pdf.
(2011) Defining the next-generation catalog Library Technology Reports, 47(7), 11-15 https://journals.ala.org/index.php/ltr/article/view/4744.
, , (2007) "VuFind rocks the house" -- Open-source initiative well received Compass: New Directions at Falvey, 4(1) https://blog.library.villanova.edu/compass/202.html.
National Information Standards Organization (2012) ODI: Open discovery initiative http://www.niso.org/workrooms/odi
National Information Standards Organization (2013) ODI survey report: Reflections and perspectives on discovery services https://dfdf.dk/wp-content/uploads/2017/02/UKSG_final_report_16_12_13_by_LISU.pdf
National Information Standards Organization (2020) NISO RP-19-2020. Open discovery initiative: Promoting transparency in discovery Open discovery initiative https://doi.org/10.3789/niso-rp-19-2020
(2009) After losing users in catalogs, libraries find better search software Chronicle of Higher Education, 75(6), 54-57 https://www.chronicle.com/article/after-losing-users-in-catalogs-libraries-find-better-search-software/.
(2010) Web-scale discovery: A review of Summon, EBSCO discovery service, and WorldCat local The Charleston Advisor, 12(1), 5-10 https://doi.org/10.5260/chara.12.1.5.
, , (2016a) Status of open access institutional digital repositories in agricultural sciences: A case study of Asia Library Philosophy and Practice, 1329 http://digitalcommons.unl.edu/cgi/viewcontent.cgi?article=3615&context=libphilprac.
, , (2016b) AgriCat: An one-stop shop for OAI-based open access agricultural repositories Journal of Agricultural Informatics, 7(1), 103-115 https://doi.org/10.17700/jai.2016.7.1.277.
, , (2016c) Open access repositories for Indian universities: Towards a multilingual framework IASLIC Bulletin, 61(4), 150-161 https://www.researchgate.net/publication/323186821_Open_Access_Repositories_for_Indian_Universities_Towards_a_Multilingual_Framework.
, , (2016d) DDC in DSpace: Integration of multi-lingual subject access system in institutional digital repositories International Journal of Knowledge Content Development & Technology, 7(4), 71-84 https://doi.org/10.5865/IJKCT.2017.7.4.071.
, , (2017) Designing metadata harvesting framework for OAI-based LIS repositories: A prototype International Journal of Information Science and Management, 15(1), 73-88 https://ijism.ricest.ac.ir/index.php/ijism/article/view/938/294.
, , (2018) Designing web-scale discovery systems using the VuFind open source software Library Hi Tech News, 35(3), 16-22 https://doi.org/10.1108/LHTN-12-2017-0088.
(2018) Using vufind discovery tool is how much replace Germany's traditional OPAC?? International Journal of Library and Information Studies, 8(2), 268-272 https://www.ijlis.org/articles/using-vufind-discovery-tool-is-how-much-replace-germanys-traditional-opac.pdf.
(2008) User experience in the library: A case study New Library World, 109(1/2), 7-24 https://doi.org/10.1108/03074800810845976.
, (2010) Designing single-window search service for electronic theses and dissertations through harvesting Annals of Library and Information Studies, 57(4), 354-364 http://hdl.handle.net/10760/17539.
, (2016) Full-text ETD retrieval in library discovery system: Designing a framework Annals of Library and Information Studies, 63(4), 274-288 https://www.researchgate.net/publication/313383707_Full-text_etd_retrieval_in_library_discovery_system_Designing_a_framework.
(2012) Adapting VuFind as a front-end to a commercial discovery system Aridane, 68 http://www.ariadne.ac.uk/issue/68/seaman.
, (2015) An empirical review of library discovery tools Journal of Service Science and Management, 8(5), 716-725 https://doi.org/10.4236/jssm.2015.85073.
(2016) To bento or not to bento - Displaying search results https://emilysingley.net/usablelibraries/to-bento-or-not-to-bento-displaying-search-results
(2012) A comparison of searching functionality of a VuFind catalogue implementation and the traditional catalogue Library Trends, 61(1), 208-217 https://doi.org/10.1353/lib.2012.0031.
Sourceforge (2021) VuFind® https://sourceforge.net/projects/vufind
, , (2013) Impact of library discovery technologies: A report for UKSG https://dfdf.dk/wp-content/uploads/2017/02/UKSG_final_report_16_12_13_by_LISU.pdf
(2011) Why not web scale discovery tools? http://musingsaboutlibrarianship.blogspot.com/2011/06/why-not-web-scale-discovery-tools.html
(2012) A study of the information search behaviour of the millennial generation Information Research, 17(1), 508 http://InformationR.net/ir/17-1/paper508.html.
, (2012) Academic libraries and discovery tools: A survey of the literature College & Undergraduate Libraries, 19(2-4), 123-143 https://doi.org/10.1080/10691316.2012.697009.
(2011a) Web scale discovery what and why? Library Technology Reports, 47(1), 5-11 https://journals.ala.org/index.php/ltr/article/view/4380.
(2011b) Ebsco discovery services Library Technology Reports, 47(1), 30-38 https://journals.ala.org/index.php/ltr/article/view/4384.
, (2011) Evaluating and implementing web scale discovery services: Part one https://digitalscholarship.unlv.edu/cgi/viewcontent.cgi?article=1089&context=libfacpresentation
, (2004) Search engine coverage bias: Evidence and possible causes Information Processing & Management, 40(4), 693-707 https://doi.org/10.1016/S0306-4573(03)00063-3.
(2015) The NISO open discovery initiative: Promoting transparency in discovery Insights, 28(1), 85-90 https://doi.org/10.1629/uksg.186.
(2010) The impact of web-scale discovery on the use of a library collection Serials Review, 36(4), 214-220 https://doi.org/10.1080/00987913.2010.10765320.
, (2009) OPACs in the clouds Computers in Libraries, 29(9), 18-22 https://eric.ed.gov/?id=EJ858684.
(2007) OPAC 2.0: Next generation online library catalogues ride the Web 2.0 wave! Online Currents, 21(10), 406-413 https://researchportal.scu.edu.au/esploro/outputs/journalArticle/OPAC-20-Next-generation-online-library/991012821731902368.
(2010) Web scale discovery: The future's so bright, I gotta wear shades Online, 34(4), 55-57 https://www.researchgate.net/publication/294420311_Web_Scale_Discovery_The_Future's_So_Bright_I_Gotta_Wear_Shades.
, (2010) The next generation library catalog: A comparative study of the OPACs of Koha, Evergreen, and Voyager Information Technology and Libraries, 29(3), 141-150 https://doi.org/10.6017/ital.v29i3.3139.
, (2011) Next generation or current generation? A study of the OPACs of 260 academic libraries in the USA and Canada Library Hi Tech, 29(2), 266-300 https://doi.org/10.1108/07378831111138170.
, (2010) Evaluating and comparing discovery tools: How close are we towards next generation catalog? Library Hi Tech, 28(4), 690-709 https://doi.org/10.1108/07378831011096312.
- 투고일Submission Date
- 2022-01-09
- 수정일Revised Date
- 2022-06-22
- 게재확정일Accepted Date
- 2022-07-07