- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI
 ISSN : 2287-9099
ISSN : 2287-9099
A Combinational Method to Determining Identical Entities from Heterogeneous Knowledge Graphs


Abstract
With the increasing demand for intelligent services, knowledge graph technologies have attracted much attention. Various application-specific knowledge bases have been developed in industry and academia. In particular, open knowledge bases play an important role for constructing a new knowledge base by serving as a reference data source. However, identifying the same entities among heterogeneous knowledge sources is not trivial. This study focuses on extracting and determining exact and precise entities, which is essential for merging and fusing various knowledge sources. To achieve this, several algorithms for extracting the same entities are proposed and then their performance is evaluated using real-world knowledge sources.
- keywords
- entity consolidation, knowledge extraction, knowledge graph, knowledge creation, knowledge interlinking
1. INTRODUCTION
With the increasing demand for intelligent services, knowledge graph technologies have attracted much attention for applications, ranging from question-answer systems to enterprise data integration (Gabrilovich & Usunier, 2016). A number of research efforts have already developed open knowledge bases such as DBpedia (Lehmann et al., 2009), Wikidata (Vrandecic, 2012), YAGO (Suchanek, Kasneci, & Weikum, 2007), and Freebase (Bollacker, Evans, Paritosh, Sturge, & Taylor, 2008). Most open knowledge bases heavily use Linked Data technologies for constructing, publishing, and accessing knowledge sources. Linked data is one of the core concepts of the Semantic Web, also called the Web of Data (Bizer, Cyganiak, & Heath, 2007; Gottron & Staab, 2014). It involves making relationships such as links between datasets understandable to both humans and machines. Technically, it is essentially a set of design principles for sharing machine-readable interlinked data on the Web (Berners-Lee, 2009). According to LODstats,1 149B triples from 2,973 datasets have been published in public, and 1,799,869 identical entity relations have already been made from 251 datasets. The standard method for stating a set of the same entities is to use the owl:same property. This property is used to describe homogeneous instances that refer to the same object in the real world. It aims to indicate that two uniform resource identifier (URI) references actually refer to the same thing (Berners-Lee, 2009).
Existing knowledge bases can be used to construct new ones to meet certain objectives, since constructing a new knowledge base from scratch is not easy. However, various issues arise when creating a new knowledge base by integrating multiple knowledge sources. One issue is whether the relationships in the existing knowledge base are always reliable. All individual instances of given knowledge sources should be identified and linked to these sources before integrating knowledge sources (Halpin, Hayes, McCusker, McGuinness, & Thompson, 2010). The problem of discovering the same entities in various data sources has been studied extensively; it is variously referred to as entity reconciliation (Enríquez, Mayo, Cuaresma, Ross, & Staples, 2017), entity resolution (Stefanidis, Efthymiou, Herschel, & Christophides, 2014), entity consolidation (Hogan, Zimmermann, Umbrich, Polleres, & Decker, 2012), and instance matching (Castano, Ferrara, Montanelli, & Lorusso, 2008). All of these approaches are very important for identifying the same relationships to extract and generate knowledge from different data sets. Entity consolidation for data integration at the instance level has attracted interest in the semantic web and linked data communities. It refers to the process of identifying same entities across heterogeneous data sources (Hogan et al., 2012). A problem can be simplified such that different identifiers are used for identical entities scattered across different datasets in a web of data. Because redundancy causes an increase in noisy or unnecessary information across a distributed web of data, identifying the same items can be advantageous in that multiple descriptions of the same entity can mutually complete and complement each other (Enríquez et al., 2017).
This study proposes a combinational approach for extracting and determining same entities from heterogeneous knowledge sources. It focuses on extracting exact and precise entity linkages, which is the key to merging and fusing various knowledge sources into new knowledge. The remainder of this paper is organized as follows. Section 2 presents a literature review of related works. Section 3 introduces research methods and basic principles of defining an entity pair from multiple knowledge bases. Section 4 introduces a formal model for entity consolidation and presents several strategies for extracting and identifying same entities. Section 5 introduces implementations of proposed strategies with some examples. Section 6 addresses and discusses findings from the evaluation using real-world knowledge bases. Section 7 concludes this study and discusses future work.
2. RELATED WORK
A number of open knowledge bases already exist such as DBpedia, Freebase, Wikidata, and YAGO (Paulheim, 2017). Wikidata (Vrandecic, 2012) is a knowledge base about the world that can be read and edited by humans and machines with the Creative Commons Zero license (CC-0).2 Information from Wikidata is called items, which are comprised of labels, descriptions, and aliases in all languages of Wikipedia. Wikidata does not aim to offer a single truth about things; instead, it provides statements given in a particular context. DBpedia (Lehmann et al., 2009) is a structured, multilingual knowledge set from Wikipedia and is made freely available on the Web using semantic web and linked data technologies. It has developed into the central interlinking hub in the Web of linked data, because it covers a wide variety of topics and sets resource data framework (RDF) links pointing to various external data sources. Freebase (Bollacker, Evans, Paritosh, Sturge, & Taylor, 2008) was a large collaborative and structured knowledge base harvested from diverse data sources. It aimed to create a global resource graph that allowed human and machines to access common knowledge more effectively. Google developed a Knowledge Graph using Freebase. On the other hand, Knowledge Vault is developed by Google to extract facts, in the form of disambiguated triples, from the entire web (Dong et al., 2014). The main difference from other works is that it fuses together facts extracted from text with prior knowledge derived from the Freebase graph. YAGO (Suchanek et al., 2007) fuses multilingual knowledge with English WordNet to build a coherent knowledge base from Wikipedia in multiple languages.
Färber, Ell, Menne, and Rettinger 2015) analyses existing knowledge graphs based on 35 characteristics, including general information (e.g., version, languages, or covered domains), format and representation (e.g., dataset formats, dynamicity, or query languages), genesis and usage (e.g., provenance of facts, influence on other linked open data [LOD] datasets), entities (e.g., entity reference, LOD registration and linkage), relations (e.g., reference, relevance, or description of relations), and schema (e.g., restrictions, constraints, network of relations). According to the comparison of entities, most knowledge graphs provide human-readable identifiers, however, Wikidata provides entity identifiers, which consists of “Q” followed by a specific number (Wang, Mao, Wang, & Guo, 2017). Most knowledge graphs are published in RDF and link their entities to entities of other datasets in LOD cloud.3 In particular, DBpedia and Freebase have a high degree of connectivity with other LOD datasets.
Note that Google recently announced that it transferred data from Freebase to Wikidata, and it launched a new API for entity search powered by Google’s Knowledge Graph. Mapping tools4 have been provided to increase the transparency of the publication process of Freebase content to integrate into Wikidata. Tanon, Vrandecic, Schaffert, Steiner, and Pintscher 2016) provided a method for migrating from Freebase to Wikidata with some limitations, including entity linking and schema mapping. This study provides comprehensive entity extraction techniques for interlinking from two knowledge sources. However identifying same entities from knowledge sources is not enough to integrating two knowledge bases. Various studies have investigated pragmatic issues of owl:sameAs in the context of the Web of Data (Halpin et al., 2010; Ding, Shinavier, Shangguan, & McGuinness, 2010; Hogan et al., 2012; Idrissou, Hoekstra, van Harmelen, Khalili, & den Besselaar, 2017). In particular, Hogan et al. 2012) discuss scalable and distributed methods for entity consolidation to locate and process names that signify the same entity. They calculate weighted concurrence measures between entities in the Linked Data corpus based on shared inlinks/ outlinks and attribute values using statistical analyses. This paper proposes a combinational approach to extract identical entity pairs from heterogeneous knowledge sources.
3. METHODOLOGY
3.1. Research Approach
This study proposes a method for extracting a set of identical entities from heterogeneous knowledge sources. An identical relationship of entities is based on calculating the properties and its values of the entities. The analysis is performed through a combination of several methods called ‘strategy.’ In this paper, five strategies are introduced and are combined for extracting and verifying identical relationships of entities. Each strategy has its own advantages and disadvantages. For example, a consistency strategy is a simple method for extracting entities, but it returns high ambiguities as noise to some extent, whereas a max confidence strategy delivers reduced ambiguities by calculating a confidence score of entity pairs. Although the max confidence method would be useful for extracting entity pairs compared to the consistency method, the max confidence strategy is based on the entity pairs extracted by the consistency one. Therefore, each strategy can be used for individual purposes, and also can be applied to determine a high quality of identical entity pairs by combining several strategies.
3.2. A Formal Model of an Entity Pair
Let knowledge bases K1 and K2 contain a set of entities and properties, respectively. The set of entities is KEi = { Ke1i, ... , Keni} and the set of properties in Ki is Kpi = { Kp1i, ... , Kpni}. In addition, let Koi = { Kci, ... , Kpi} be the ontology schema of Ki, where Kci is the set of classes and Kpi is the set of properties. Thus, entity pairs EP(K1, K2) as a set of identical entities for given knowledge bases K1 and K2 are denoted as follows:
EP(K1, K2)={(Ke11,Kej1),...,(Kes1,Ket2)}
where Ke1i is identical to Kej2. On the other hand, the schema alignment Ko is aligned to its schemas:
Ko=Ko1align⇔Ko2
where Kc1align⇔Kc2 is the class alignment and Kp1align⇔Kp2 is the property alignment for K1 and K2. In this sense, Kci1align⇔Kcj2 means that Kci1 is identical to Kcj2, and Kpi1align⇔Kpj2 means that the value of Pi in K1 corresponds to that of Pj in K2. Thus, according to Ko, a set of property mappings to the matching keys is defined as follows:
MK(K1,K2)={(Kpi1,Kpj2),...,(Kps1,Kpt2)}
4. STRATEGIES FOR ENTITY CONSOLIDATION
A number of approaches is available for identifying the same entities from heterogeneous knowledge bases (Hors & Speicher, 2014; Nguyen & Ichise, 2016; Moaawad, Mokhtar, & al Feel, 2017). This section addresses some methods to determine identical relationships from the extracted entities. Note that formal models of four strategies are introduced and their characteristics are also discussed.
4.1. Consistency Strategy
This strategy aims to extract a set of precise entities by mapping property values on specific knowledge bases. That is, to determine the consistency of Kei1 and Kej2 based on matching keys MK, two strategies, SI and SU, are defined:
Strategy SI: For Kem1 and Ken2 from K1 and K2, ∀(KPi1,KPj2)∈MK(K1,K2) , the Kpi1 value of Kem1 is exactly equal to the Kpj2 value of Kpj2. Then, (Kem1,Ken2) is an identical entity pair, and the consistency determination is of the intersection strategy SI.
Strategy SU: For Kem1 and Ken2 from K1 and K2, ∃(KPi1,KPj2)∈MK(K1,K2), the Kpi1 value of Kem1 is exactly equal to the Kpj2 value of Ken2. Then, (Kem1,Ken2) is an identical entity pair, and the consistency determination is of the union strategy SU.
This strategy is based on the assumption that all knowledge sources are trustworthy: The knowledge in Ki is precise and without defect. The identical relations EP(K1, K2) extracted by this strategy are considered precise because the mapping of the property values is exact without bias. On the contrary, most open knowledge bases contain some defects which may be caused by false recognition, inaccurate source, or knowledge redundancy. Note that one entity can be interlinked to multiple entities of different knowledge sources (e.g. ∃(Kei1,Kej2),(Kes1,Ket2)∈EP(K1,K2), and Kei1 = Kes1 and Kej2≠ Ket2 ). This ambiguous pair might arise from a defect in the knowledge base Ki. For establishing highquality linkages across heterogeneous knowledge sources, it is essential to extract confident EP(K1,K2) by eliminating ambiguities to the greatest extent possible. Therefore, alternative strategies are proposed.
4.2. Max Confidence Strategy
This strategy calculates a confidence score for the entity pairs extracted by the consistency strategy to reduce the noise caused by defects and determines precise and confident entity pairs. The formal notation of this strategy is defined as follows:
Given matching keys MK(K1,K2)={(Kpi1,Kpj2), ... , (Kps1,Kpt2)}, for Kem1∈KE1 and Ken2∈KE2, let MKm={Kpim1,Kpjm2),...,(Kpsm1,Kptm2)} be the matched MK(K1,K2), where (Kpim1,Kpjm2) indicates that the Kpim1 value of Kem1 is exactly equal to the Kpjm2 value of Ken2. Based on this, MKm and MK(K1,K2) can be defined as MKm⊆MK(K1,K2), then a confidence score of (Kem1,Ken2) is calculated by the following equation:
conf(Kem1,Ken1)=∥MKm∥/∥MK(K1,K2)∥
where ∥⋅∥ is the cardinality. Therefore, a confidence score is assigned to each entity pair, and for (Kei1,Kej2) , (Kes1,Ket2) ∈EP(K1,K2). Therefore, (Kei1,Kej2) is the confident identical entity pair where conf(Kei1,Kej2)>conf(Kes1,Ket2).
4.3. Threshold Filtering Strategy
The Max Confidence allows to filter out ambiguous same entity pairs; nonetheless, some of entity pairs may have relatively high scores with low confidence levels. To solve this issue, a threshold is added to the extraction process: If an entity pair has determined with the highest confidence and it has a low score compared to other scores, it can be removed from a set of candidates. The threshold filtering strategy aims to improve a confidence level of extracted entity pairs by using a threshold score. Given a threshold θ for (Kei1,Kej2),(Kei1,Ket2)∈EP(K1,K2), where conf(Kei1,Kej2)>conf(Kei1,Ket2) and conf(Kei1,Kej2)≥θ,(Kei1,Kej2) is selected as the confident same entity pair.
4.4. One-to-One Mapping Strategy
This strategy extracts simply 1-1 entity pairs from heterogeneous knowledge sources by ignoring multiple relations in which one identifier is matched to multiple identifiers of different sources. Formally, it is represented as ∀(Kei1,Kej2)∈EP(K1,K2),∄(Kes1,Ket2)∈EP(K1,K2) where i = s or j = t. By applying one-to-one mapping, identical entity pairs EP(K1,K2) have no ambiguous relations.
4.5. Belief-based Strategy
The four strategies introduced so far focus on interrelations between entity pairs by comparing properties of knowledge bases, whereas they do not consider intrarelations in a certain pair. In other words, property values of entities in a certain pair should be checked for determining identical relations. The belief-based strategy aims to analyse property values of extracted entity pairs that is based on the Dempster-Shafer theory (Yager, 1987), also called the theory of evidence.
Given a set of same entity pairs EP, let XEP denote the set representing all possible states of an entity pair. Here, two cases are possible: The two entities are linked (L) or the two entities are not linked (U). Note that XEP = {L, U}. Then, ΩXEP= { Φ , L, U, {L, U}}, where indicates the empty set, and {L, U} indicates that it is uncertain whether Φ they are linked. Therefore, a belief degree is assigned to each element of ΩXEP:

where m is the degree of same belief, which is the basic belief assignment in the Dempster-Shafer theory. Then, each pair of knowledge sources has four hypotheses, and the formal model is represented as follows:

Given MK(K1,K2)={(Kpi1,Kpj2),...,(Kps1,Kpt2)} and MK(K1,K2)={(Kpim1,Kpjm2),...,(Kpsm1,Kptm2)}, m is assigned as follows:
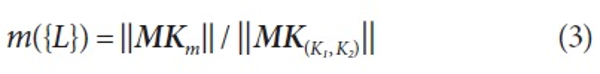
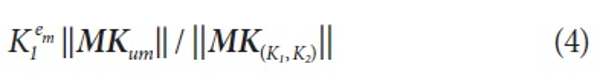
where MKum represents the unmatched MK(K1,K2), that is, the Kpi1 value of Kem1 is not equal to the Kpj2 value of Ken2. And uncertain pairs of knowledge sources are calculated by the following model:
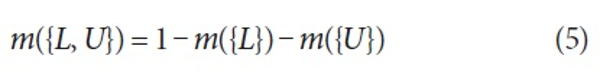
According to the theory of evidence, the basic belief assignment m(A), A∈Ω , expresses the proportion of all relevant and available evidence that supports the claim that the actual state belongs to A. In this sense, a degree of belief is represented as a belief function rather than a Bayesian probability distribution.
5. IMPLEMENTATION OF THE BELIEF-BASED STRATEGY
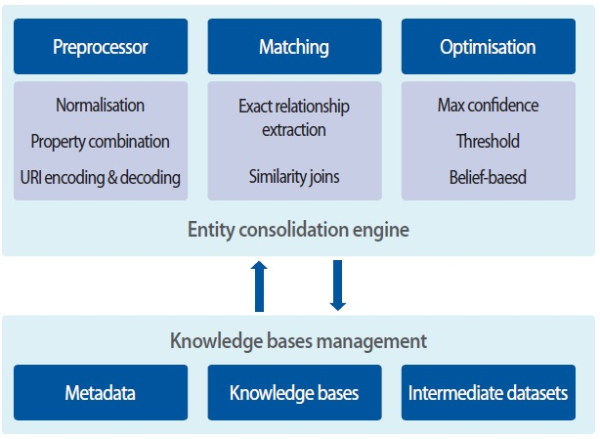
The proposed strategies are developed in the entity extraction framework (Kim, Liang, & Ying, 2014), which is to extract identical entities among heterogeneous knowledge sources. In particular, entity matching is carried out by configured property values for each entity pair. As illustrated in Fig. 1, it is comprised of several components: Preprocessor for normalising entities and properties and to extract a set of URI from knowledge sources, Matching for extracted entities and properties based on exact and similarity measure, Optimization for better extracting a set of same entity pairs using several strategies, and Knowledge Base Management that aims to create and interlink a knowledge base for the consolidation results.
Currently, this framework is being used for extracting relations from both Wikidata and Freebase. To identify the same entities from both knowledge sources, Wikipedia is the primary data source used to detect relations between Freebase and Wikidata. Therefore, for detecting source errors and identifying exact identical relationships, four strategies are implemented. In particular, those strategies are fully implemented in this framework: for example, the workflow of entity consolidation based on the Max Confidence as shown in Fig. 2. It is designed to compute the Max Confidence for entity consolidation to reduce the noise caused by defects and to obtain precise and confident same entity pairs.

For the threshold strategy, a threshold score is set as 0.5 by default. After eliminating a set of pairs under the threshold score, the Max Confidence approach is applied. Furthermore, the belief-based approach is developed and applied by using the same datasets. As shown in Table 1, for the Persian soldier Pharnabazus II ( https://en.wikipedia. org/wiki/Pharnabazus_II), Freebase ( http://rdf.freebase. com/ns/m.01d89y) has 8 Wikipedia links whereas Wikidata ( https://www.wikidata.org/wiki/Q458256) has 20 Wikipedia links in Table 2. Note that the belief-based approach for the case shown in Tables 1 and 2 can be calculated as follows:
Table 1.
An example of Freebase entity

The full uniform resource identifier of Freebase entity has ‘ http://rdf.freebase.com/ns/’ with identifier, i.e., http://rdf.freebase.com/ns/m.01d89y.
-
mass({ Φ}) = 0
-
mass({Link}) = Matched Wikipedia Link Number ⁄ Total Wikipedia Link Number
-
mass({Unlink}) = Unmatched Wikipedia Link Number ⁄ Total Wikipedia Link Number
-
mass({Link, Unlink}) = 1 - mass({ Φ}) - mass({Link}) - mass({Unlink})
There are matched and unmatched links compared to the given identifiers based on a Wikipedia link. On the other hand, both Wikidata and Freebase do not have the corresponding links. In this case, the status is uncertain. Therefore, the belief-based approach for the given example is calculated:
As a result, for entity ‘m.01d89y,’ the belief degree for unlinking with entity ‘Q458256’ is much greater than the belief degree for linking. Therefore, we consider that ‘m.01d89y’ is different from ‘Q458256.’
Table 2.
An example of Wikidata
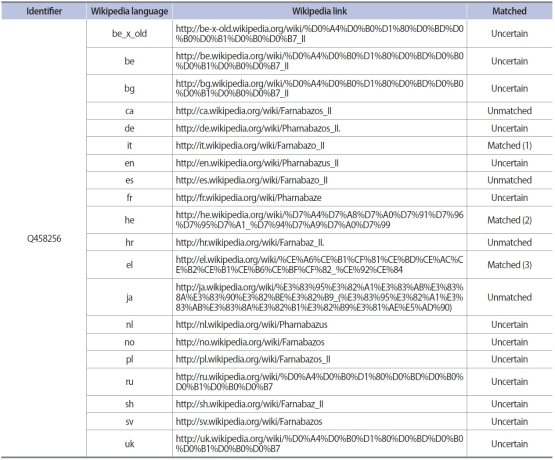
The full uniform resource identifier of Freebase entity has ‘ https://www.wikidata.org/wiki/’ with identifier, i.e., https://www.wikidata.org/wiki/Q458256.
6. EVALUATION
6.1. Data Collection
Two knowledge bases (i.e., Wikidata and Freebase) are selected to demonstrate the proposed strategies. Wikidata and Freebase are receiving great attention from academia and industry for constructing their own knowledge bases, and there are realistic issues for data integration between two knowledge sources. It is essential to derive homogeneous entities for knowledge integration, since Wikidata and Freebase have been developed independently. A set of same entities between Freebase (2015-02-10)5 and Wikidata (2015-02-07) is extracted via their own Wikipedia reference links (i.e., wiki-keys of Freebase and Wikipedia URLs of Wikidata). After pre-processing the collected datasets, 4,446,380 entities from Freebase and 15,403,618 entities from Wikidata are extracted with Wikipedia links. By using the consistency strategy (i.e., S1), 4,400,955 pairs are obtained from both knowledge sources.
6.2. Results
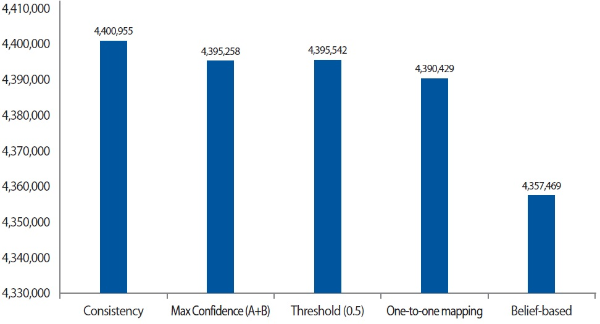
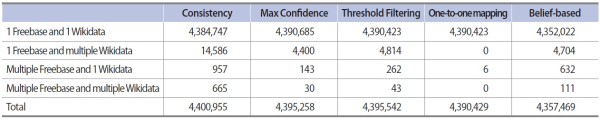
The aim of applying different approaches for same extraction is to generate links with the highest confidence between Freebase and Wikidata entities. The results differed slightly with the given datasets. Fig. 3. The result of extracting same entities between Freebase and Wikidata.3 illustrates the results obtained using different mapping styles with the proposed strategies. Note that the consistency strategy obtains the largest number of entity pairs. Nonetheless, there are a number of 1-multiple/multiple-1/multiple-multiple links which cause ambiguities as shown in Table 3. Without applying any approaches, the consistency strategy possesses the largest ambiguity (0.37%). The oneto-one mapping obviously holds the full confident same entity mapping pairs. The Max Confidence, the Threshold Filtering (0.5 threshold), and the Belief-based strategies show great effect on elimination of ambiguity. The number of mapping pairs based on belief degree is approximated to that of Max Confidence. The belief degree greatly influences the reduction in ambiguity in the multiple Freebase case but not in the multiple Wikidata case.
As shown in Table 4, the precision and F1 score are 100 percent for all strategies, because the set of matching pairs is extracted by using the Strategy SU, whereas both the precision and F1 score are greater than 98.1371 percent, and precision scores are slightly differed among these strategies. Based on this result, a combination of each strategy can reduce some ambiguities that are not removed using a single approach. On the other hand, both the precision and F1 score of the belief-based strategy are 99.1165 and 99.5563, respectively. This demonstrates that the belief-based strategy provides an extremely high matching quality.

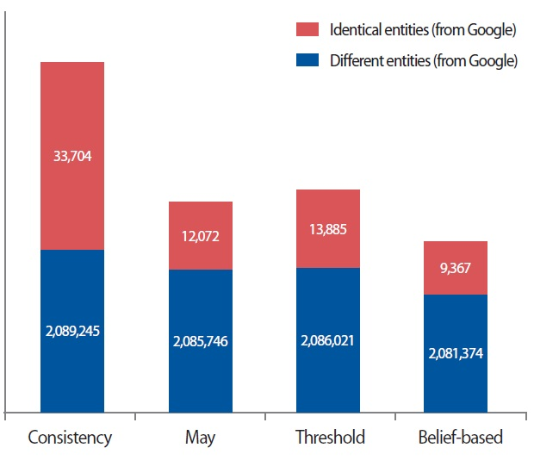
Note that Google has also constructed a mapping between Freebase and Wikidata that was published in October 2013. They detected 2,099,582 entity pairs with 2,096,745 Freebase entities and 2,099,582 Wikidata entities. Fig. 4 illustrates the result of identical entity pairs using the same datasets from Freebase and Wikidata. The entity pairs from all proposed strategies have some differences compared to the Google result. Although they did not explicitly announce how they extracted this result, it might use an exact matching of Wikipedia URL. Applying the proposed strategies to the Google results, the identical mapping pairs are more than 99.51%. However, they include ambiguous results according to individual strategies. For example, the consistency strategy has the highest different entities (1.59%), whereas the belief-based strategy is the smallest (0.45%). In summary, the belief-based strategy can be considered as an effective approach to reduce ambiguity for entity extraction. Note that matching performance of the Google result is not conducted, because they provided this dataset only once, and did not update related data sources.
7. CONCLUSIONS
This study proposed several approaches for identifying the same entities from heterogeneous knowledge sources and evaluated these approaches by using Wikidata and Freebase. According to the evaluation results, the belief-based approach is most effective for reducing the ambiguous relations between the given datasets. Although the consistency strategy returned the largest number of pairs of the same relation, it also had the highest number of errors. Entity resolution is a popular topic in industry and academia. Currently, common and popular approaches for entity resolution focus on similarity-join techniques, but few studies have focused on belief-based approaches. The proposed belief-based same extraction approach can be a new technique for measuring the matching degree of entity pairs.
Although this paper conducted an entity extraction using large-scale real-world datasets, there are more experiments for integrating heterogeneous knowledge sources. Future work may explore the alternative expanding algorithms for handling different property values and evaluating the impact of optimised approaches. Another potential area of research is to integrate heterogeneous knowledge into existing knowledge sources by instance matching techniques.
References
(2009, Retrieved Jun 10, 2018) The semantic web: linked data. https://www.w3.org/ DesignIssues/LinkedData.html
, , (2007, Retrieved Jun 10, 2018) How to publish linked data on the web. http://wifo5-03.informatik.uni-mannheim.de/bizer/pub/LinkedDataTutorial/
- Submission Date
- 2017-12-07
- Revised Date
- Accepted Date
- 2018-07-09