- Apply for Authority
- P-ISSN2287-9099
- E-ISSN2287-4577
- SCOPUS, KCI

Vol.10 No.S
Abstract
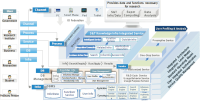
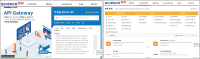
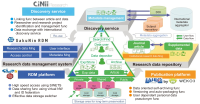
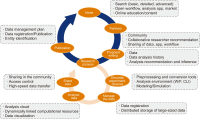
As data-based research activities and outcomes increase and ontact or non-face-to-face activities become common, the demand for easy utilization of resources, tools, functions, and easily accessible information required for research in the R&D sector has increased accordingly. With the rapid increase in the demand for collaborative research based on online platforms, research support institutions strive to provide venues for research activities that merge various information and functions. ScienceON, an integrated science & technology (S&T) knowledge infrastructure service developed and operated by the Korea Institute of S&T Information (KISTI), supports open collaboration by connecting and merging all the information, functions, and infrastructure required for research activities. This paper describes the online research activity support tool provided by ScienceON and the remarkable results achieved through this activity. Specifically, the excellent creation of the following flow of meta-material research activities in the ontact space is elucidated. First, the papers required for a meta-material analysis are retrieved, virtual simulation is conducted with the experimental data extracted from the papers, and research data are accumulated. ScienceON’s tools for supporting ontact research activity will play a role as an important service in the era of digital transformation and open science.



Abstract
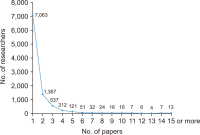
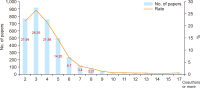
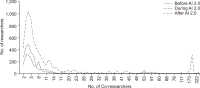
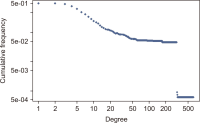
This study attempted to investigate changes in collaboration structure for each stage of national Research and Development (R&D) in the artificial intelligence (AI) field through analysis of a co-author network for papers written under national R&D projects. For this, author information was extracted from national R&D outcomes in AI from 2014 to 2019. For such R&D outcomes, NTIS (National Science & Technology Information Service) information from the KISTI (Korea Institute of Science and Technology Information) was utilized. In research collaboration in AI, power function structure, in which research efforts are led by some influential researchers, is found. In other words, less than 30 percent is linked to the largest cluster, and a segmented network pattern in which small groups are primarily developed is observed. This means a large research group with high connectivity and a small group are connected with each other, and a sporadic link is found. However, the largest cluster grew larger and denser over time, which means that as research became more intensified, new researchers joined a mainstream network, expanding a scope of collaboration. Such research intensification has expanded the scale of a collaborative researcher group and increased the number of large studies. Instead of maintaining conventional collaborative relationships, in addition, the number of new researchers has risen, forming new relationships over time.

Abstract
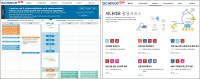
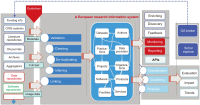
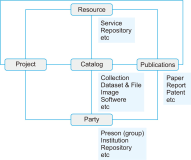
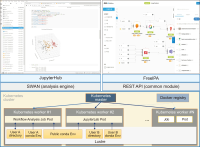
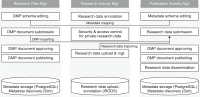
Research data means data used or created in the course of research or experiments. Research data is very important for validation of research conducted and for use in future research and projects. Recently, convergence research between various fields and international cooperation has been continuously done due to the explosive increase of research data and the increase in the complexity of science and technology. Developed countries are actively promoting open science policies that share research results and processes to create new knowledge and values through convergence research. Communities to promote the sharing and utilization of research data such as RDA (Research Data Alliance) and COAR (Confederation of Open Access Repositories) are active, and various platforms for managing and sharing research data are being developed and used. OpenAIRE (Open Access Infrastructure for Research In Europe), a research data platform in Europe, ARDC (Australian Research Data Commons) in Australia, and IRDB (Institutional Repositories DataBase) in Japan provide research data or research data related services. Korea has been establishing and implementing a research data sharing and utilization strategy to promote the sharing and utilization of research data at the national level, led by the central government. Based on this strategy, KISTI has been building a Korean research data platform (DataON) since 2018, and has been providing research data sharing and utilization services to users since January 2020. This paper reviews the characteristics of DataON and how it is used for research by showing its applications.






Abstract
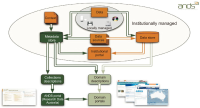
For national industrial development in the Fourth Industrial Revolution, it is necessary to provide researchers with appropriate job information. This can be achieved by interconnecting the National Science and Technology Standard Classification System used for management of research activity with the Korean Employment Classification of Occupations used for job information management. In the present study, an automatic linkage model of classification systems is introduced based on a pre-trained language model for interconnecting science and technology information with job information. We propose for the first time an automatic model for linkage of classification systems. Our model effectively maps similar classes between the National Science & Technology Standard Classification System and Korean Employment Classification of Occupations. Moreover, the model increases interconnection performance by considering hierarchical features of classification systems. Experimental results show that precision and recall of the proposed model are about 0.82 and 0.84, respectively.
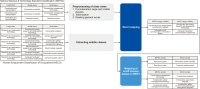



Abstract
Eight years have passed since the Sponsoring Consortium for Open Access Publishing in Particle Physics (SCOAP3) was launched. SCOAP3 is one of the most successful global partnerships and funds for Open Access and has been benchmarked by other Open Access initiatives. The Korea Institute of Science and Technology Information (KISTI) joined as the first Asian partner in 2011, and has supported its shared vision and contributed its financial commitment since the beginning of SCOAP3. SCOAP3-Korea is the first bottom-up collaboration for local libraries to re-direct funds previously used for subscriptions to Open Access publishing. This paper explores the roles and responsibilities of KISTI in the Open Access quest. It describes the commitment to SCOAP3 in South Korea, including how the collaboration model for SCOAP3-Korea differs from the global model. This paper also discusses the impact of SCOAP3-Korea by analyzing publications affiliated by Korean authors in SCOAP3 journals for the last six years (2014- 2019). We have integrated the national R&D project and research outcome data from NTIS (National Science and Technology Information Service) to investigate the research articles benefited by SCOAP3 and research publications in non-SCOAP3 journals. The positive impact of SCOAP3 in increasing research publication in the discipline was revealed compared to non-SCOAP3 journals. In addition, the financial benefit of SCOAP3-Korea has been proven. With regard to the investment for readers, $137,094 USD was saved during the SCOAP3 Phase 1 and 2, while $748,923 USD was saved with regard to publication fees. We discussed the lessons from SCOAP3-Korea for commitment to a larger-scale Open Access transition.


Abstract
Korea Institute of Science and Technology Information (KISTI) is a Worldwide LHC Computing Grid (WLCG) Tier-1 center mandated to preserve raw data produced from A Large Ion Collider Experiment (ALICE) experiment using the world’s largest particle accelerator, the Large Hadron Collider (LHC) at European Organization for Nuclear Research (CERN). Physical medium used widely for long-term data preservation is tape, thanks to its reliability and least price per capacity compared to other media such as optical disk, hard disk, and solid-state disk. However, decreasing numbers of manufacturers for both tape drives and cartridges, and patent disputes among them escalated risk of market. As alternative to tape-based data preservation strategy, we proposed disk-only erasure-coded archival storage system, Custodial Disk Storage (CDS), powered by Exascale Open Storage (EOS), an open-source storage management software developed by CERN. CDS system consists of 18 high density Just-Bunch-Of-Disks (JBOD) enclosures attached to 9 servers through 12 Gbps Serial Attached SCSI (SAS) Host Bus Adapter (HBA) interfaces via multiple paths for redundancy and multiplexing. For data protection, we introduced Reed-Solomon (RS) (16, 4) Erasure Coding (EC) layout, where the number of data and parity blocks are 12 and 4 respectively, which gives the annual data loss probability equivalent to 5×10-14. In this paper, we discuss CDS system design based on JBOD products, performance limitations, and data protection strategy accommodating EOS EC implementation. We present CDS operations for ALICE experiment and long-term power consumption measurement.



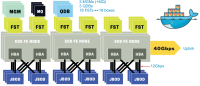






Abstract
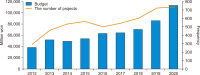
The manufacturing industry is the foundation that drives economic growth, and manufacturing innovation is essential for sustainable growth advantage and the transition into a digital economy. Therefore, major countries actively support the field of simulations, which incorporate information and communication technologies into manufacturing, and announce various policies at the national level along with increasing investment. Simulation technology virtualizes product development processes to replace physical production and experimentation of products, dramatically reducing time and costs. In South Korea, the Korea Institute of Science and Technology Information (KISTI) has supported manufacturing companies for about 14 years by providing relevant technologies. This study uses the input-output table for the Bank of Korea to analyze the economic ripple effect. First, we identified the domestic industrial sector dealing with the supercomputing-based simulation industry. Then we analyzed its ripple effects by dividing them into the production inducement effect, value-added inducement effect, employment inducement effect, and forward/ backward linkage effect. Consequently, when the supercomputing simulation budget of KISTI (28.3 billion won, 2007-2020) was set as an input coefficient, the analysis showed 45.1 billion won as the production inducement effect, 24.7 billion won as the valueadded inducement effect, and 282 individuals per 1 billion won as the employment inducement effect. This study is significant in that it derived the effects of the inputs by analyzing the economic ripple effects of the projects of KISTI, which have been supporting South Korean manufacturing companies for the past 14 years with supercomputing-based simulations.
Abstract
At the 8th National High-Performance Computing (HPC) Committee convened in 2021, the “National High-Performance Computing Innovation Strategy (draft) for the 4th Industrial Revolution Era” was deliberated and the original draft was approved. In this proposal, the Ministry of Science and ICT in KOREA announced three major plans and nine detailed projects with the vision of “Realizing the 4th industrial revolution quantum jumping by leaping into a high-performance computing powerhouse.” Thereby the most important policy about national mid-term and long-term HPC development was established and called the HPC innovation strategy (hereinafter “the innovation strategy”). The three plans of the innovation strategy proposed by the government are: Strategic HPC infrastructure expansion; Secure source technologies; and Activate innovative HPC utilization. Each of the detailed projects has to be executed nationally and strategically. In this paper, we propose a strategy for the implementation of two items (“Strategic HPC infrastructure expansion” and “activate innovative HPC utilization”) among these detailed plans.
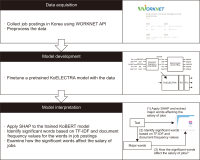
Abstract
Online recruitment websites discuss job demands in various fields, and job postings contain detailed job specifications. Analyzing this text can elucidate the features that determine job salaries. Text embedding models can learn the contextual information in a text, and explainable artificial intelligence frameworks can be used to examine in detail how text features contribute to the models’ outputs. We collected 733,625 job postings using the WORKNET API and classified them into low, mid, and high-range salary groups. A text embedding model that predicts job salaries based on the text in job postings was trained with the collected data. Then, we applied the SHapley Additive exPlanations (SHAP) framework to the trained model and discovered the significant words that determine each salary class. Several limitations and remaining words are also discussed.



Abstract
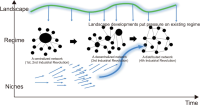
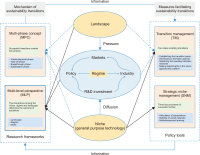
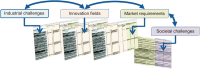
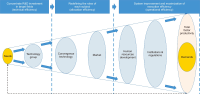
With the rapid development of the Fourth Industrial Revolution and digital transformation, scientific and technological innovation measures are being devised to overcome Korea’s low-growth, high-cost structure. Accordingly, by examining the R&D investment evaluation system of R&D PIE (R&D Platform for Investment and Evaluation), which has been promoted by the Korean government in response to the Fourth Industrial Revolution, from the perspective of R&D transformation, this study aims to explore a new path for a sustainable national science and technology innovation system following digital transformation. In particular, from the perspective of R&D PIE, a MLP (Multi-level Perspective), which had been conducted as an abstract theoretical study, was attempted with specific cases and analysis for each of the three layers: niche, landscape, and regime. In conclusion, R&D PIE was intended to elevate the abstract R&D investment evaluation system to a platform that leads innovation in the digital space of the Fourth Industrial Revolution. In addition, it was confirmed that the R&D PIE could be replaced or enhanced as a platform for innovation in response to the Fourth Industrial Revolution, thereby providing an alternative to job creation and an escape from economic crisis.




Abstract
Food security and its sovereignty have become among the most important key issues due to changes in the international situation. Regarding these issues, many countries now give attention to smart agriculture, which would increase production efficiency through a data-based system. The Korean government also has attempted to promote smart agriculture by 1) implementing the agri-food ICT (information and communications technology) policy, and 2) increasing the R&D budget by more than double in recent years. However, its endeavors only centered on large-scale farms which a number of domestic farmers rarely utilized in their farming. To promote smart agriculture more effectively, we diagnosed the government R&D trends of smart agriculture based on NTIS (National Science and Technology Information Service) data. We identified the research trends for each R&D period by analyzing three pieces of information: the regional information, research actor, and topic. Based on these findings, we could suggest systematic R&D directions and implications.

Abstract
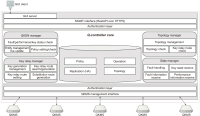
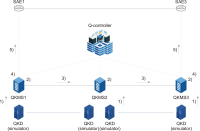
Existing network cryptography systems are threatened by recent developments in quantum computing. For example, the Shor algorithm, which can be run on a quantum computer, is capable of overriding public key-based network cryptography systems in a short time. Therefore, research on new cryptography systems is actively being conducted. The most powerful cryptography systems are quantum key distribution (QKD) and post quantum cryptograph (PQC) systems; in this study, a network based on both QKD and PQC is proposed, along with a quantum key management system (QKMS) and a Q-controller to efficiently operate the network. The proposed quantum cryptography communication network uses QKD as its backbone, and replaces QKD with PQC at the user end to overcome the shortcomings of QKD. This paper presents the functional requirements of QKMS and Q-Controller, which can be utilized to perform efficient network resource management.



Abstract
Recently, with the development of data processing technology and the increase of computational power, methods to solving social problems using Artificial Intelligence (AI) are in the spotlight, and AI technologies are replacing and supplementing existing traditional methods in various fields. Meanwhile in Korea, heavy rain is one of the representative factors of natural disasters that cause enormous economic damage and casualties every year. Accurate prediction of heavy rainfall over the Korean peninsula is very difficult due to its geographical features, located between the Eurasian continent and the Pacific Ocean at mid-latitude, and the influence of the summer monsoon. In order to deal with such problems, the Korea Meteorological Administration operates various state-of-the-art observation equipment and a newly developed global atmospheric model system. Nevertheless, for precipitation nowcasting, the use of a separate system based on the extrapolation method is required due to the intrinsic characteristics associated with the operation of numerical weather prediction models. The predictability of existing precipitation nowcasting is reliable in the early stage of forecasting but decreases sharply as forecast lead time increases. At this point, AI technologies to deal with spatio-temporal features of data are expected to greatly contribute to overcoming the limitations of existing precipitation nowcasting systems. Thus, in this project the dataset required to develop, train, and verify deep learning-based precipitation nowcasting models has been constructed in a regularized form. The dataset not only provides various variables obtained from multiple sources, but also coincides with each other in spatio-temporal specifications.
Abstract
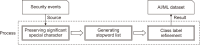
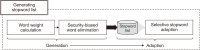
With the development of networks and the increase in the number of network devices, the number of cyber attacks targeting them is also increasing. Since these cyber-attacks aim to steal important information and destroy systems, it is necessary to minimize social and economic damage through early detection and rapid response. Many studies using machine learning (ML) and artificial intelligence (AI) have been conducted, among which payload learning is one of the most intuitive and effective methods to detect malicious behavior. In this study, we propose a preprocessing method to maximize the performance of the model when learning the payload in term units. The proposed method constructs a high-quality learning data set by eliminating unnecessary noise (stopwords) and preserving important features in consideration of the machine language and natural language characteristics of the packet payload. Our method consists of three steps: Preserving significant special characters, Generating a stopword list, and Class label refinement. By processing packets of various and complex structures based on these three processes, it is possible to make high-quality training data that can be helpful to build high-performance ML/AI models for security monitoring. We prove the effectiveness of the proposed method by comparing the performance of the AI model to which the proposed method is applied and not. Forthermore, by evaluating the performance of the AI model applied proposed method in the real-world Security Operating Center (SOC) environment with live network traffic, we demonstrate the applicability of the our method to the real environment.

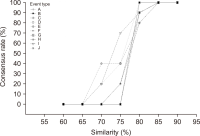

Abstract
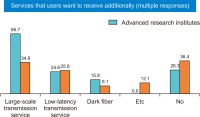
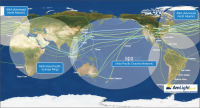
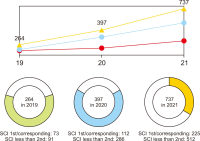
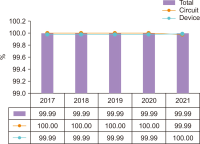
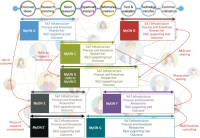
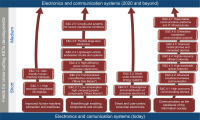
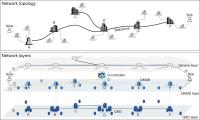
The purpose of this paper is to illuminate the role and importance of National Research & Education Network (NREN) in the national research and education field and to establish the future strategy of KREONET in Korea. To this end, we first carefully analyze the footsteps of NREN in major overseas countries, KREONET achievements, and future demand for KREONET. The history of NREN’s development is divided into the 2000s, 2010s, and present by era, and classified into network infrastructure, network service, and next-generation network technology by subject. KREONET achievements are divided into advanced research support, network backbone and operation, and network service. Future demand analysis of users who use KREONET was conducted through Korea Research International Incorporation, a survey company. This paper presents the future development strategy of KREONET by analyzing KREONET achievements and future demand.